Localizador de recursos uniforme
Un LRU o localizador de recursos uniforme (más conocido por las siglas URL, del inglés Uniform Resource Locator)[1] es un identificador de recursos uniforme (Uniform Resource Identifier, URI) cuyos recursos referidos pueden cambiar, esto es, la dirección puede apuntar a recursos variables en el tiempo. Están formados por una secuencia de caracteres de acuerdo con un formato modélico y estándar que designa recursos en una red como, por ejemplo, Internet.
Los URL fueron una innovación en la historia de Internet. Fueron usados por primera vez por Tim Berners-Lee en 1991, para permitir a los autores de documentos establecer hiperenlaces en la World Wide Web (WWW). Desde 1994, en los estándares de Internet, el concepto de LRU ha sido incorporado dentro del más general de URI, pero el término URL todavía se utiliza ampliamente.
Aunque nunca fueron mencionadas como tal en ningún estándar, mucha gente cree que las iniciales LRU significan universal —en lugar de uniform— resource locator (localizador universal de recursos). Esto se debe a que en 1990 era así, pero al unirse las normas Functional Recommendations for Internet Resource Locators (RFC 1736) y Functional Requirements for Uniform Resource Names (RFC 1737) pasó a denominarse identificador de recursos uniforme (RFC 2396). Sin embargo, la letra «U» en URL siempre ha significado «uniforme».
El LRU es una cadena de caracteres con la que se asigna una dirección única a cada uno de los recursos de información disponibles en Internet.[2] Existe un URL único para cada página de cada uno de los documentos de la WWW, para todos los elementos de Gopher y todos los grupos de debate Usenet, y así sucesivamente.
El LRU de un recurso de información es su dirección en Internet, la cual permite que el navegador web la encuentre y la muestre de forma adecuada. Por ello, el URL combina el nombre de la computadora que proporciona la información, el directorio donde se encuentra, el nombre del archivo y el protocolo a usar para recuperar los datos para que no se pierda alguna información sobre dicho factor que se emplea para el trabajo.
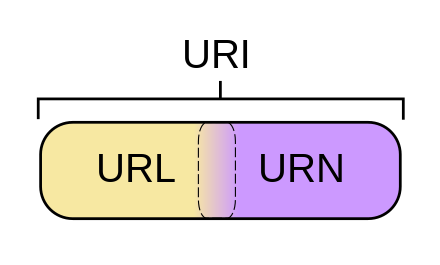
Se puede entender que una URI = URL + URN.
Formato general
[editar]El formato general de un URL es:
esquema://máquina/directorio/archivo
También pueden añadirse otro tipo de información:
esquema://usuario:contraseña@máquina:puerto/directorio/archivo
Por ejemplo: https://www.wikipedia.org/
La especificación detallada se encuentra en la RFC 1738, titulada Uniform Resource Locators.
Esquema URL
[editar]
Un URL se clasifica por su esquema, que generalmente indica el protocolo de red que se usa para recuperar, a través de la red, la información del recurso identificado. Un URL comienza con el nombre de su esquema, seguido por dos puntos, seguido por una parte específica del esquema.
Algunos ejemplos de esquemas URL:
http- recursos Hypertext Transfer Protocol (HTTP).https- HTTP sobre Secure Sockets Layer (SSL).ftp- File Transfer Protocol.mailto- direcciones de correo electrónico.ldap- búsquedas Lightweight Directory Access Protocol (LDAP).file- recursos disponibles en el sistema local o en una red local.news- grupos de noticias Usenet (newsgroup).gopher- el protocolo Gopher (en desuso).telnet- el protocolo Telnet.ws- el protocolo WebSocket.data- el esquema para insertar pequeños trozos de contenido en los documentos esquema de URI de datos (Data: URL).
Algunos de los esquemas URL, como los populares mailto, http, ftp y file, junto con los de sintaxis general URL, se detallaron por primera vez en 1994 en el Request for Comments RFC 1630, sustituido un año después por los más específicos RFC 1738 y RFC 1808.
Todavía son válidos algunos de los esquemas definidos en el primer RFC, mientras que otros son debatidos o han sido refinados por estándares posteriores. Mientras tanto, la definición de la sintaxis general de los URL se ha escindido en dos líneas separadas de especificación de URI: RFC 2396 (1998) y RFC 2732 (1999), ambos ya obsoletos pero todavía ampliamente referidos en las definiciones de esquemas URL.
El estándar actual es el STD 66/RFC 3986 de 2005.
URL en el uso diario
[editar]Un HTTP URL combina en una dirección simple los cuatro elementos básicos de información necesarios para recuperar un recurso desde cualquier parte en Internet:
- El protocolo que se usa para comunicar o enviar datos.
- El anfitrión (servidor o host) con el que se comunica.
- El puerto de red en el servidor para conectarse.
- La ruta al recurso en el servidor (por ejemplo, su nombre de archivo).
Un URL típico puede ser del tipo:
http://es.wikipedia.org:80/wiki/Special:Search?search=tren&go=Go
Donde:
httpes el protocolo.es.wikipedia.orges el anfitrión.80es el número de puerto de red en el servidor (Siendo 80 el valor por defecto para el protocolo HTTP, esta porción puede ser omitida por completo)./wiki/Special:Searches la ruta de recurso.?search=tren&go=Goes la cadena de búsqueda (Parte opcional).
Muchos navegadores web no requieren que el usuario introduzca http:// para dirigirse a una página web, porque HTTP es el protocolo más común que se usa en navegadores web. Igualmente, dado que 80 es el puerto por defecto para HTTP, usualmente no se especifica. Normalmente, solo se introduce un URL parcial, por ejemplo: www.wikipedia.org/wiki/Train. Para ir a una página principal se introduce únicamente el nombre de anfitrión, como www.wikipedia.org.
Dado que el protocolo HTTP permite que un servidor responda a una solicitud redirigiendo el navegador web a un URL diferente, muchos servidores adicionalmente permiten a los usuarios omitir ciertas partes del URL, tales como la parte "www.", o el carácter numeral ("#") de rastreo si el recurso en cuestión es un directorio. Sin embargo, estas omisiones técnicamente constituyen un URL diferente, de modo que el navegador web no puede hacer estos ajustes y tiene que confiar en que el servidor responderá con una redirección. Es posible para un servidor web (debido a una extraña tradición) ofrecer dos páginas diferentes para URL que difieren únicamente en un carácter "#".
Nótese que en es.wikipedia.org/wiki/Tren, el orden jerárquico de los cinco elementos es:
- org (dominio de nivel superior genérico)
- Wikipedia (dominio de segundo nivel)
- es (subdominio)
- wiki
- Tren
Es decir, antes de la primera barra diagonal «/» se lee de derecha a izquierda, y después el resto se lee de izquierda a derecha.
Visión general
[editar]El término URL también es usado fuera del contexto de la WWW. Los servidores de bases de datos especifican URL como un parámetro para realizar conexiones. De forma similar, cualquier aplicación cliente-servidor que siga un protocolo particular puede especificar un formato URL como parte de su proceso de comunicación.
Ejemplo de un URL en una base de datos:
jdbc:datadirect:oracle://myserver:1521;sid=testdb
Si una página web es en forma singular y más o menos permanentemente definida a través de un URL, puede ser enlazada (véase también permalink, deep linking). Este no siempre es el caso, por ejemplo, una opción de menú puede cambiar el contenido de un marco dentro de la página, sin que esta nueva combinación tenga su propio URL. Una página web puede depender también de información almacenada temporalmente. Si el marco o página web tiene su propio URL, esto no es siempre obvio para alguien que quiere enlazarse a ella: el URL de un marco no aparece en la barra de direcciones del navegador, y una página sin barra de direcciones pudo haber sido producida. El URL se puede encontrar en el código fuente o en las propiedades de varios componentes de la página.
Aparte del propósito de enlazarse a una página o a un componente de página, puede ocurrir que se quiera conocer el URL para mostrar únicamente el componente o superar restricciones tales como una ventana de navegador que no tenga barras de herramientas o que sea de tamaño pequeño y no ajustable.
Los servidores web también tienen la capacidad de direccionar URL si el destino ha cambiado, permitiendo a los sitios cambiar su estructura sin afectar los enlaces existentes. Este proceso se conoce como redireccionamiento de URL.
Véase también
[editar]Referencias
[editar]- ↑ «Resolución del 19 de febrero de 2013, de la Secretaría de Estado de Administraciones Públicas, por la que se aprueba la Norma Técnica de Interoperabilidad de Reutilización de recursos de la información» (pdf). BOE.
- ↑ Hu$tle, Blogger's (6 de noviembre de 2020). «how to download youtube videos in laptop». Medium (en inglés). Archivado desde el original el 25 de noviembre de 2020. Consultado el 26 de noviembre de 2020.
| Control de autoridades |
|
|---|
Datos: Q42253
Multimedia: Uniform Resource Locator / Q42253