ASCII

ASCII (acronimo di American Standard Code for Information Interchange, lett. "codice standard americano per lo scambio di informazioni") è un codice per la codifica di caratteri. La prima edizione dello standard ASCII è stata pubblicata dall'American National Standards Institute (ANSI) nel 1963[1], quindi il codice ha subito un'importante revisione nel 1968[2]. L'aggiornamento più recente risale al 1986[3]. In italiano viene pronunciato aschi /ˈaski/ o asci /ˈaʃʃi/[4], mentre la pronuncia originale inglese è askey /ˈæski/.
L'asteroide 3568 ASCII prende il nome da questa codifica dei caratteri.
Storia
[modifica | modifica wikitesto]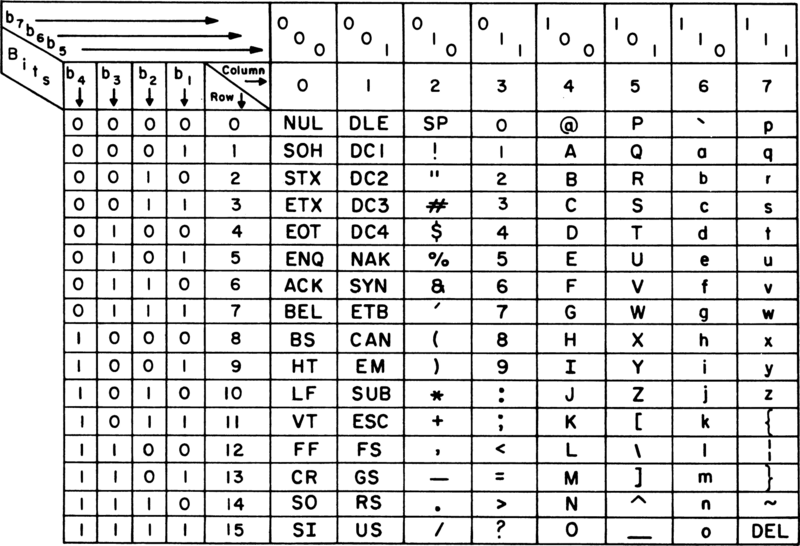
Con US-ASCII si intende un sistema di codifica dei caratteri a 7 bit, comunemente utilizzato nei calcolatori, proposto dall'ingegnere dell'IBM Bob Bemer nel 1961, e successivamente accettato come standard dall'ISO, con il nome di ISO/IEC 646.
Alla specifica iniziale basata su codici di 7 bit fecero seguito negli anni molte proposte di estensione ad 8 bit, con lo scopo di raddoppiare il numero di caratteri rappresentabili. Tuttavia nessuna estensione è uno standard internazionale. Nei personal computer si fa e si faceva uso di una di una serie di estensioni locali e configurabili in base al paese, spesso indicate con extended ASCII o high ASCII e non sono mai standard, per esempio queste codifiche sono differenti da paese a paese e una stessa nazione può avere più codifiche differenti attivabili, inoltre il set utilizzato in sistemi operativi come CP/M era diverso per ogni produttore, e a sua volta differente dai set utilizzati in MS-DOS, a sua volta diverso da quelli di Windows, Linux e MacOS. Inoltre i set multipli e localizzati sono nemmeno univoci perché ogni sistema, come MS-DOS, ha spesso più sotto-sistemi di estensione (codepage). Per esempio alcuni sistemi usano delle sottopagine dello standard 646, nei Mac c'era la gestione Mac Roman, in MS-DOS si usavano spesso sotto-pagine dei codepage 437, 850, 852, 1252, ISO 8859-1 in occidente (ognuno con una serie di sotto-pagine), del 866 nell'ex blocco sovietico In questo ASCII esteso, i caratteri aggiunti sono ad esempio vocali accentate, simboli semigrafici e altri simboli di uso meno comune, pensati anche per adattarsi alle specificità delle diverse lingue[5]. A sua volta il problema della rappresentazione nelle varie lingue è stato superato dalle codifiche Escape e dai codici ANSI, e poi esteso e uniformato con i vari standard Unicode, mentre l'unico ASCII davvero standard rimane quello a 7 bit. L'ottavo bit può essere utilizzato per estensioni più o meno personalizzate oppure per il controllo di parità nelle trasmissioni, cosa che avviene per esempio nelle trasmissioni seriali con RS-232C (oggi incapsulata nelle porte USB per i PC domestici), RS-485 e RS-488.
ASCII ed UTF-8
[modifica | modifica wikitesto]Lo standard successore di ASCII è l'UTF-8, che è diventato la codifica principale di Unicode per internet secondo il W3C, che pur non impedendo altre codifiche (purché correttamente dichiarate), lo consiglia e lo usa quasi sistematicamente negli esempi del suo sito[6], fornendo anche le istruzioni per convertire i documenti (cosa che non fornisce per tutte le codifiche)[7]. Questa codifica di Unicode, che ormai è universalmente accettata da ogni nuovo programma, offre caratteristiche interessanti grazie al fatto di sfruttare il bit di controllo del vecchio ASCII in modo più efficiente. Se da una parte lo prepara per la pensione, UTF-8 in un certo senso ha reso molto più longevo l'ASCII, inglobandolo in una codifica più adatta alle esigenze attuali. Infatti le comunicazioni sono in centinaia di lingue, ed inoltre diverse lingue possono convivere in uno stesso documento, o in uno stesso programma: si pensi ai software di messaggistica istantanea che possono contenere contatti da varie parti del mondo dei quali visualizzare correttamente i nomi.
UTF-8 infatti si distingue dalle altre codifiche Unicode perché sfrutta il vecchio bit di parità di ASCII, non come bit di controllo, bensì come indicatore: analizza ogni byte, e se al posto del vecchio bit di parità c'è 0, allora il byte sarà letto come ASCII a 7 bit e teoricamente compatibile anche con programmi obsoleti; se però il byte corrente inizia con 1, allora sarà concatenato al byte successivo (o ai successivi, in realtà il meccanismo è un poco più complesso). In tal modo riesce ad includere tutti gli alfabeti delle lingue viventi, di alcune morte e potenzialmente può essere esteso per rappresentarne ancora altri (infatti spesso viene aggiornato).
Il vantaggio è che è possibile scrivere un testo in Italiano ed usare un numero di byte di poco maggiore rispetto ad una codifica di ASCII esteso (le lettere accentate occupanno solo 4 byte in più); un testo in lingua Cinese avrà ogni carattere di tre byte, con numeri, lettere, punteggiatura ed altri eventuali caratteri ASCII presenti nel testo di un solo byte.
Tabella dei caratteri
[modifica | modifica wikitesto]La tabella seguente è relativa al codice US ASCII, ANSI X3.4-1986 (ISO 646 International Reference Version). I codici decimali da 0 a 31 e il 127 sono caratteri non stampabili (caratteri di controllo). Il 32 corrisponde al carattere di "spazio". I codici dal 32 al 126 sono caratteri stampabili.
Non stampabili
[modifica | modifica wikitesto]| Binario | Ottale | Decimale | Esadecimale | |||||
|---|---|---|---|---|---|---|---|---|
| 000 0000 | 000 | 0 | 00 | NUL | ␀ | ^@ | \0 | Null character |
| 000 0001 | 001 | 1 | 01 | SOF | ␁ | ^A | ☺ | |
| 000 0010 | 002 | 2 | 02 | STX | ␂ | ^B | ☻ | |
| 000 0011 | 003 | 3 | 03 | ETX | ␃ | ^C | ♥ | |
| 000 0100 | 004 | 4 | 04 | EOT | ␄ | ^D | ♦ | |
| 000 0101 | 005 | 5 | 05 | ENQ | ␅ | ^E | ♣ | |
| 000 0110 | 006 | 6 | 06 | ACK | ␆ | ^F | ♠ | |
| 000 0111 | 007 | 7 | 07 | BEL | ␇ | ^G | \a | • |
| 000 1000 | 010 | 8 | 08 | BS | ␈ | ^H | \b | ◘ |
| 000 1001 | 011 | 9 | 09 | ␉ | ^I | \t | ○ | |
| 000 1010 | 012 | 10 | 0A | LF | ␊ | ^J | \n | ◙ |
| 000 1011 | 013 | 11 | 0B | VT | ␋ | ^K | \v | ♂ |
| 000 1100 | 014 | 12 | 0C | FF | ␌ | ^L | \f | ♀ |
| 000 1101 | 015 | 13 | 0D | CR | ␍ | ^M | \r | ♪ |
| 000 1110 | 016 | 14 | 0E | SO | ␎ | ^N | ♫ | |
| 000 1111 | 017 | 15 | 0F | SI | ␏ | ^O | ☼ | |
| 001 0000 | 020 | 16 | 10 | DLE | ␐ | ^P | ► | |
| 001 0001 | 021 | 17 | 11 | DC1 | ␑ | ^Q | ◄ | |
| 001 0010 | 022 | 18 | 12 | DC2 | ␒ | ^R | ↕ | |
| 001 0011 | 023 | 19 | 13 | DC3 | ␓ | ^S | ‼ | |
| 001 0100 | 024 | 20 | 14 | DC4 | ␔ | ^T | ¶ | |
| 001 0101 | 025 | 21 | 15 | NAK | ␕ | ^U | § | |
| 001 0110 | 026 | 22 | 16 | SYN | ␖ | ^V | ▬ | |
| 001 0111 | 027 | 23 | 17 | ETB | ␗ | ^W | ↨ | |
| 001 1000 | 030 | 24 | 18 | CAN | ␘ | ^X | ↑ | |
| 001 1001 | 031 | 25 | 19 | EM | ␙ | ^Y | ↓ | |
| 001 1010 | 032 | 26 | 1A | SUB | ␚ | ^Z | → | |
| 001 1011 | 033 | 27 | 1B | ESC | ␛ | ^[ | ← | |
| 001 1100 | 034 | 28 | 1C | FS | ␜ | ^\ | ∟ | |
| 001 1101 | 035 | 29 | 1D | GS | ␝ | ^] | ↔ | |
| 001 1110 | 036 | 30 | 1E | RS | ␞ | ^^ | ▲ | |
| 001 1111 | 037 | 31 | 1F | US | ␟ | ^_ | ▼ | |
| 111 1111 | 177 | 127 | 7F | DEL | ␡ | ^? | Delete (tasto elimina-backspace) | |
Stampabili
[modifica | modifica wikitesto]
| Binario | Oct | Dec | Hex | Glifo |
|---|---|---|---|---|
| 010 0000 | 040 | 32 | 20 | Spazio |
| 010 0001 | 041 | 33 | 21 | ! |
| 010 0010 | 042 | 34 | 22 | " |
| 010 0011 | 043 | 35 | 23 | # |
| 010 0100 | 044 | 36 | 24 | $ |
| 010 0101 | 045 | 37 | 25 | % |
| 010 0110 | 046 | 38 | 26 | & |
| 010 0111 | 047 | 39 | 27 | ' |
| 010 1000 | 050 | 40 | 28 | ( |
| 010 1001 | 051 | 41 | 29 | ) |
| 010 1010 | 052 | 42 | 2A | * |
| 010 1011 | 053 | 43 | 2B | + |
| 010 1100 | 054 | 44 | 2C | , |
| 010 1101 | 055 | 45 | 2D | - |
| 010 1110 | 056 | 46 | 2E | . |
| 010 1111 | 057 | 47 | 2F | / |
| 011 0000 | 060 | 48 | 30 | 0 |
| 011 0001 | 061 | 49 | 31 | 1 |
| 011 0010 | 062 | 50 | 32 | 2 |
| 011 0011 | 063 | 51 | 33 | 3 |
| 011 0100 | 064 | 52 | 34 | 4 |
| 011 0101 | 065 | 53 | 35 | 5 |
| 011 0110 | 066 | 54 | 36 | 6 |
| 011 0111 | 067 | 55 | 37 | 7 |
| 011 1000 | 070 | 56 | 38 | 8 |
| 011 1001 | 071 | 57 | 39 | 9 |
| 011 1010 | 072 | 58 | 3A | : |
| 011 1011 | 073 | 59 | 3B | ; |
| 011 1100 | 074 | 60 | 3C | < |
| 011 1101 | 075 | 61 | 3D | = |
| 011 1110 | 076 | 62 | 3E | > |
| 011 1111 | 077 | 63 | 3F | ? |
| Binario | Oct | Dec | Hex | Glifo |
|---|---|---|---|---|
| 100 0000 | 100 | 64 | 40 | @ |
| 100 0001 | 101 | 65 | 41 | A |
| 100 0010 | 102 | 66 | 42 | B |
| 100 0011 | 103 | 67 | 43 | C |
| 100 0100 | 104 | 68 | 44 | D |
| 100 0101 | 105 | 69 | 45 | E |
| 100 0110 | 106 | 70 | 46 | F |
| 100 0111 | 107 | 71 | 47 | G |
| 100 1000 | 110 | 72 | 48 | H |
| 100 1001 | 111 | 73 | 49 | I |
| 100 1010 | 112 | 74 | 4A | J |
| 100 1011 | 113 | 75 | 4B | K |
| 100 1100 | 114 | 76 | 4C | L |
| 100 1101 | 115 | 77 | 4D | M |
| 100 1110 | 116 | 78 | 4E | N |
| 100 1111 | 117 | 79 | 4F | O |
| 101 0000 | 120 | 80 | 50 | P |
| 101 0001 | 121 | 81 | 51 | Q |
| 101 0010 | 122 | 82 | 52 | R |
| 101 0011 | 123 | 83 | 53 | S |
| 101 0100 | 124 | 84 | 54 | T |
| 101 0101 | 125 | 85 | 55 | U |
| 101 0110 | 126 | 86 | 56 | V |
| 101 0111 | 127 | 87 | 57 | W |
| 101 1000 | 130 | 88 | 58 | X |
| 101 1001 | 131 | 89 | 59 | Y |
| 101 1010 | 132 | 90 | 5A | Z |
| 101 1011 | 133 | 91 | 5B | [ |
| 101 1100 | 134 | 92 | 5C | \ |
| 101 1101 | 135 | 93 | 5D | ] |
| 101 1110 | 136 | 94 | 5E | ^ |
| 101 1111 | 137 | 95 | 5F | _ |
| Binario | Oct | Dec | Hex | Glifo |
|---|---|---|---|---|
| 110 0000 | 140 | 96 | 60 | ` |
| 110 0001 | 141 | 97 | 61 | a |
| 110 0010 | 142 | 98 | 62 | b |
| 110 0011 | 143 | 99 | 63 | c |
| 110 0100 | 144 | 100 | 64 | d |
| 110 0101 | 145 | 101 | 65 | e |
| 110 0110 | 146 | 102 | 66 | f |
| 110 0111 | 147 | 103 | 67 | g |
| 110 1000 | 150 | 104 | 68 | h |
| 110 1001 | 151 | 105 | 69 | i |
| 110 1010 | 152 | 106 | 6A | j |
| 110 1011 | 153 | 107 | 6B | k |
| 110 1100 | 154 | 108 | 6C | l |
| 110 1101 | 155 | 109 | 6D | m |
| 110 1110 | 156 | 110 | 6E | n |
| 110 1111 | 157 | 111 | 6F | o |
| 111 0000 | 160 | 112 | 70 | p |
| 111 0001 | 161 | 113 | 71 | q |
| 111 0010 | 162 | 114 | 72 | r |
| 111 0011 | 163 | 115 | 73 | s |
| 111 0100 | 164 | 116 | 74 | t |
| 111 0101 | 165 | 117 | 75 | u |
| 111 0110 | 166 | 118 | 76 | v |
| 111 0111 | 167 | 119 | 77 | w |
| 111 1000 | 170 | 120 | 78 | x |
| 111 1001 | 171 | 121 | 79 | y |
| 111 1010 | 172 | 122 | 7A | z |
| 111 1011 | 173 | 123 | 7B | { |
| 111 1100 | 174 | 124 | 7C | | |
| 111 1101 | 175 | 125 | 7D | } |
| 111 1110 | 176 | 126 | 7E | ~ |
ASCII art
[modifica | modifica wikitesto]Esiste anche un tipo di arte, chiamata ASCII art, che consiste nel creare immagini con i caratteri dell'alfabeto ottenendo una grossolana scala di grigi sfruttando il riempimento del carattere.

Note
[modifica | modifica wikitesto]- ^ CNN - 1963: The debut of ASCII - July 6, 1999, su edition.cnn.com. URL consultato il 21 marzo 2022.
- ^ World Power Systems:Texts:Annotated history of charactercodes, su www.sr-ix.com. URL consultato il 21 marzo 2022.
- ^ Federal Information Processing Standards Publication: code extension techniques for use with the 7-bit coded character set of American national standard code for information interchange, National Bureau of Standards, 1974. URL consultato il 21 marzo 2022.
- ^ ASCII, in Treccani.it – Vocabolario Treccani on line, Roma, Istituto dell'Enciclopedia Italiana.
- ^ ASCII-American-Standard-Code-for-Information-Interchange, su IONOS Digitalguide. URL consultato il 21 marzo 2022.
- ^ (EN) Character encodings, su W3C. URL consultato il 22 giugno 2015.
- ^ (EN) Changing an HTML page encoding to UTF-8, su W3C. URL consultato il 22 giugno 2015.
Bibliografia
[modifica | modifica wikitesto]- (EN) RFC 20 — ASCII format for Network Interchange, su datatracker.ietf.org, Internet Engineering Task Force.
- (EN) David Salomon, The ASCII Code, in Data Compression: The Complete Reference, 1ª ed., New York, Springer, 1998, pp. 301-303, DOI:10.1007/978-1-4757-2939-9, ISBN 978-1-4757-2939-9.
Voci correlate
[modifica | modifica wikitesto]Altri progetti
[modifica | modifica wikitesto]Wikizionario contiene il lemma di dizionario «ASCII»
Wikimedia Commons contiene immagini o altri file sull'ASCII
Collegamenti esterni
[modifica | modifica wikitesto]- ASCII, su Treccani.it – Enciclopedie on line, Istituto dell'Enciclopedia Italiana.
- ASCII, su sapere.it, De Agostini.
- (EN) ASCII, su Enciclopedia Britannica, Encyclopædia Britannica, Inc.
- (EN) Opere riguardanti ascii code, su Open Library, Internet Archive.
- (EN) Denis Howe, American Standard Code for Information Interchange, in Free On-line Dictionary of Computing. Disponibile con licenza GFDL
- (EN) ASA standard X3.4-1963, su wps.com. URL consultato il 3 novembre 2013 (archiviato dall'url originale il 24 luglio 2012).
| Controllo di autorità | LCCN (EN) sh98005902 · GND (DE) 4665825-7 · J9U (EN, HE) 987007546943005171 |
|---|