Egyszempontos varianciaanalízis
A statisztikában az egyszempontos varianciaanalízis (rövidítve egyszempontos ANOVA) olyan technika, amely két vagy több minta átlagának összehasonlítására használható (az F-eloszlás használatával). Ez a technika csak numerikus válasz adatokkal használható, a függő változó, általában egy változó, és ezek numerikus, vagy (általában) kategorikus bemeneti adatok, a független változó, mindig egy változó, ezért "egyirányú".[1]
Az ANOVA azt a nullhipotézist teszteli, hogy a minták minden csoportban azonos átlagértékű populációkból kerülnek kiválasztásra. Ehhez két becslés készül a lakosság varianciájáról. Ezek a becslések különböző feltételezésekre támaszkodnak (lásd alább). Az ANOVA képez egy F-statisztikát, ami a mintákon belüli átlagok varianciájának a varianciahányadosa. Hogyha a csoportátlagokat azonos átlagértékű populációkból vettük, akkor a csoportok közötti variancia alacsonyabb kellene, hogy legyen, mint a minták varianciája, követve a központi határeloszlás-tételt. Egy magasabb arány tehát implikálja, hogy a mintákat különböző átlagértékű populációkból vettük.
Jellemzően azonban az egyszempontos ANOVA legalább három csoport közötti különbségek mérésére használt teszt, mivel a két csoport eseté t-próba alkalmazható (Gosset, 1908). Amikor csak két csoport átlagát hasonlítjuk össze, a t-próba valamint az F-teszt egyenértékű; az összefüggés az ANOVA és a t között F = t2. Az egyszempontos ANOVA kiterjesztése a kétszempontos varianciaanalízis, ami két különböző kategorikus független változó hatását vizsgálja a függő változóra.
Feltételezések
[szerkesztés]Az egyszempontos ANOVA eredményei addig tekinthetőek megbízhatónak, amíg a következő feltételezések teljesülnek:
- Válasz változó reziduálisok normális eloszlásúak (vagy közel normális eloszlásúak).
- A populációk varianciája egyenlő.
- Adott csoport válaszai független, azonos eloszlású, normális eloszlású véletlen változók (nem egy egyszerű véletlen minta (SRS)).
Ha az adatok ordinálisak, nem-parametrikus alternatívaként például a Kruskal–Wallis egyutas varianciaanalízis használható. Ha a varianciák nem egyenlőek, a kétmintás Welch t-teszt általánosítását lehet használni.[2]
Eltávolodás a populáció normalitásától
[szerkesztés]Az ANOVA egy viszonylag robusztus eljárás, a normalitás megsértésére való tekintettel is.[3]
Az egyszempontos ANOVA általánosítható faktoriális, többváltozós elrendezésekhez, valamint kovariancia elemzéséhez is.
Gyakran kijelentetik a népszerű irodalomban, hogy ezen F-tesztek egyike sem robusztus, amikor súlyosan sérül az a feltételezés, hogy az egyes populációk követik normális eloszlást, különösen a kis alfa szintek és az aszimmetrikus elrendezés miatt.[4] Emellett azt is állítják, hogy ha a mögöttes feltételezés, a homoszkedaszticitás megsérül, az elsőfajú hiba lehetősége jelentősen nő.[5]
Azonban az 1950-es években és korábban készült munkák alapján ez tévedés. Az első átfogó vizsgálat a kérdésre a Monte Carlo szimuláció volt Donaldson (1966) által.[6] Megmutatta, hogy a normalitás általános sérülései során (pozitív ferdeség, nem egyenlő szórások) "az F-teszt olyan konzervatív", hogy kevésbé valószínű azt találnunk, hogy egy változó szignifikáns, mint azt, hogy nem. Azonban, hogyha akár a minta mérete, vagy a cellák száma növekszik, "a teljesítmény görbék a normál eloszlás felé konvergálnak". Tiku (1971) megállapította, hogy "a nem-normál elméletű F ereje eltér a normál elmélet erejétől, egy korrekciós idő által, amely élesen csökken a minta méretének növekedésével."[7] A probléma a nem-normalitással, különösen a nagy minták esetén, sokkal kevésbé súlyos, mint azt népszerű cikkek sejtetik.
Az aktuális nézet szerint a "Monte-Carlo tanulmányokat széles körben használták a normál eloszlás-alapú vizsgálatokhoz meghatározandó, hogy milyen érzékenyek ezek a normál eloszlás megsértésének feltételezésére, a vizsgált változókra vonatkozóan a populáción belül . Az általános következtetés ezekből a vizsgálatokból, hogy az ilyen sértések következményei kevésbé súlyosak, mint azt korábban gondolták. Ezek a következtetések növelték az eloszlás-függő statisztikai tesztek általános népszerűségét rengeteg kutatási területen."[8]
Nemparaméteres alternatívákért faktoriális elrendezésben, lásd Sawilowsky.[9] További párbeszédért lásd ANOVA rangsorolva.
Fixált hatások, teljesen randomizált kísérlet, kiegyensúlyozatlan adatok esete
[szerkesztés]A modell
[szerkesztés]A normál lineáris modell a kezelt csoportokat a valószínűségi disztribúció alapján írja le, amelyej hasonló harang alakú (normál) görbék más átlagokkal. Tehát a modellek illeszkedési csupán az egyes kezelési csoportok átlagait és a variancia számítását igényli. Az átlagok és a variancia számítása a hipotézis tesztelés részeként zajlik.
A leggyakrabban használt normál lineáris modellek egy teljesen randomizált kísérlethez:[10]
- (az átlagok modell)
vagy
- (a hatások modell)
ahol
- index a kísérleti egységek fölött
- index a kezelt csoportok között
- a kísérleti egységek száma a j-edik kezelt csoportban
- a kísérleti egységek teljes száma
- megfigyelések
- a j-edik kezelt csoportokra vonatkozó megfigyelések átlaga
- a megfigyelések nagy átlaga
- a j-edik kezelési hatás, a nagy átlagtól való eltérés
- , normál eloszlású zéró átlagú random hibák.
Az indexet " " a kísérleti egységek felett több módon lehet értelmezni. Egyes kísérleteknél, ugyanaz a kísérleti egység számos kezeléshez tartozik; egységre. Máskor minden csoportban van külön, egyedi kísérleti egységek vannak; ilyenkor egyszerűen egy indexe a -edik listának.
Az adatok és az adatok statisztikai összegei
[szerkesztés]A kísérleti megfigyeléseket elrendezhetjük oszloponként csoportokban:
| Lists of Group Observations | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | ||||||||
| 2 | ||||||||
| 3 | ||||||||
| Group Summary Statistics | Grand Summary Statistics | |||||||
| # Observed | # Observed | |||||||
| Sum | Sum | |||||||
| Sum Sq | Sum Sq | |||||||
| Mean | Mean | |||||||
| Variance | Variance | |||||||
Összehasonlítva a modellt az összegzésekkel: és . A nagy átlag és a nagy variancia a nagy összegekből számolandó, nem pedig a csoport átlagokból és szórásokból.
A hipotézis tesztek
[szerkesztés]Az összefoglaló statisztikákat figyelembe véve a hipotézis teszt számításait láthatjuk táblázatos formában. Míg két oszlop négyzetösszeg (SS) látható, addig csak egy oszlop is elég az eredmények megjelenítéséhez.
| Source of variation | Sums of squares | Sums of squares | Degrees of freedom | Mean square | F |
|---|---|---|---|---|---|
| Explanatory SS[11] | Computational SS[12] | DF | MS | ||
| Treatments | |||||
| Error | |||||
| Total |
a modell -ének becsült varianciája.
Elemzési összefoglaló
[szerkesztés]Az ANOVA elemzés alapja egy sor számításon áll. Az adatokat táblázatos formában gyűjti. Aztán
- Minden egyes kezelési csoport összegezve van a kísérleti egységek száma, két összeg, egy átlag és egy variancia alapján. A kezelési csoport összefoglalók kombinálva vannak, hogy biztosítsák az egységek számáról és a végösszegek összértékét. A nagy átlag és a nagy variancia a nagy végösszegekből számolandó. A kezelési és a nagy átlagokat felhasználja a modell.
- A három szabadságfok és négyzetösszeg a végösszegekből számolandó.
- A számítógép általában az F-értékből határozza meg a p-értéket, ami megállapítja, hogy a kezelések szignifikáns eredményeket szültek-e. Hogyha az eredmények szignifikánsak, akkor a modellnek előreláthatóan van érvényessége.
Ha a kísérlet kiegyensúlyozott, minden feltétel egyenlő, tehát a négyzetösszeg számolások egyszerűsödnek. Egy bonyolultabb kísérletben, ahol a kísérleti egységek (vagy a környezeti hatások) nem homogének, sorban értelmezett statisztikákat is használunk az elemzésben. Az extra feltételek meghatározása csökkenti az elérhető szabadságfokok számát.
Példa
[szerkesztés]Képzeljünk el egy kísérletet, hogy egy faktor 3 szintjének hatását tanulmányozzuk (pl. három szintű permetező egy növényültetvényen). Hogyha 6 megfigyelésünk van minden szinten, akkor le tudjuk írni a lehetséges kimeneteleket az alábbi táblázatnak megfelelően, ahol a1, a2, és a3 a faktor 3 szintje, melyeket megfigyelünk.
a1 a2 a3 6 8 13 8 12 9 4 9 11 5 11 8 3 6 7 4 8 12
A nullhipotézis (H0), az összes F-tesztre vonatkozóan erre a kísérletre nézve az lenne, hogy a faktor három szintje ugyanazt a hatást váltja ki, átlagosan. Hogy kiszámítsuk az F-arányt:
1. lépés: Számítsuk ki az átlagot az egyes csoportokon belül:
2. lépés: Számítsuk ki a teljes átlagot
- ahol a a csoportok száma.
3. lépés: Számítsuk ki a csoportok közötti (between-group) négyzetösszegek különbségét:
ahol n az adat értékek száma csoportonként.
A csoportok közötti szabadságfok eggyel kevesebb, mint a csoportok száma
így a csoportok közötti átlagos négyzetes érték:
4. lépés: Számítsuk ki a csoporton belüli (within-group) négyzetösszeget. Kezdjük adatok központosításával az egyes csoportokban
| a1 | a2 | a3 |
|---|---|---|
| 6-5=1 | 8-9=-1 | 13-10=3 |
| 8-5=3 | 12-9=3 | 9-10=-1 |
| 4-5=-1 | 9-9=0 | 11-10=1 |
| 5-5=0 | 11-9=2 | 8-10=-2 |
| 3-5=-2 | 6-9=-3 | 7-10=-3 |
| 4-5=-1 | 8-9=-1 | 12-10=2 |
A csoporton belüli négyzetösszeg az alábbi táblázat minden értékének négyzetösszege:
A csoporton belüli szabadságfok:
Így a csoporton belüli átlag négyzet értéke:
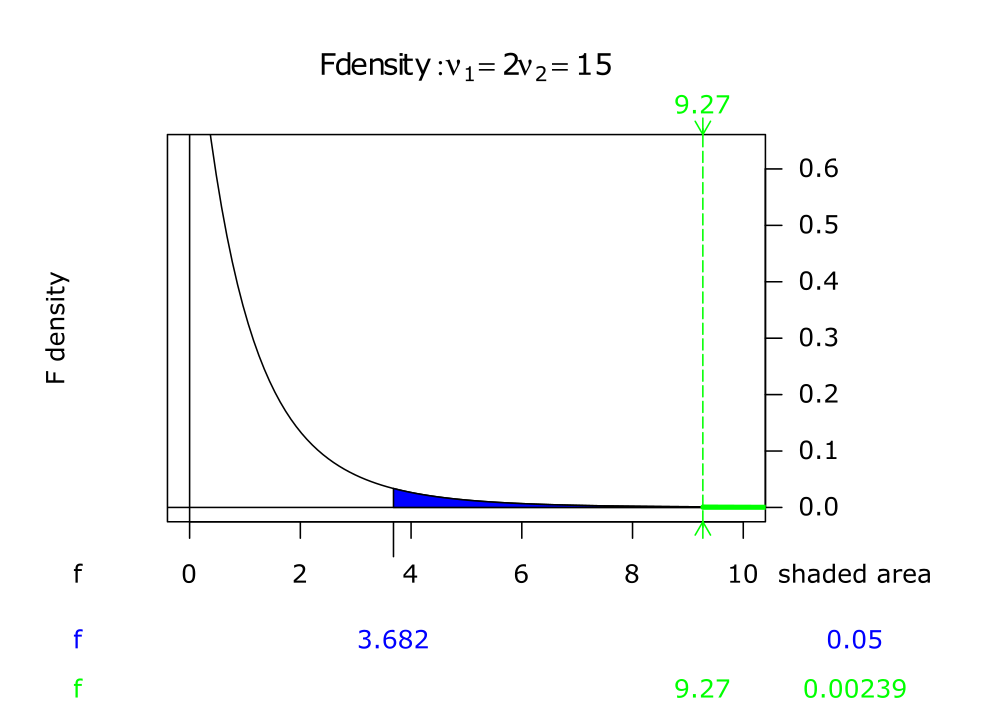
5. lépés: Az F-arány
A kritikus érték az a szám, amelyet a teszt statisztika meg kell, hogy haladjon, hogy elutasíthassuk a tesztet. Ebben az esetben, Fcrit(2,15) = 3.68 ahol α = 0.05. Mivel F=9.3 > 3.68, az eredmények szignifikánsak 5% - os szignifikancia szinten. Tehát el kell utasítanunk a nullhipotézist, következtetésként levonva, hogy erős bizonyíték áll fent a három csoport elvárt értékeinek különbözőségére. Erre a tesztre vonatkozó p-érték 0.002.
Az F-teszt elvégzése után, szokás szerint "post-hoc" tesztet futtatunk a csoportátlagokról. Ebben az esetben, az első két csoport átlaga 4 egységgel különbözik, az első és a harmadik csoport átlaga 5 egységgel, a második és a harmadik csoport átlaga pedig csak egy egységgel. A standard hiba minden ilyen különbségre nézve . Következésképp, az első csoport erősen különbözik a többitől, mivel az átlagos különbség többszöröse a standard hibának, szóval magabiztosan kijelenthetjük, hogy az első csoport populációjának az átlaga különbözik a többi csoport populációjának átlagától. Ellenben nincs bizonyíték arra, hogy a második és a harmadik csoportnak eltérő populáció átlagai vannak, mivel egy egység átlagos különbsége összehasonlítható a standard hibával. Megjegyzés: az F(x, y) az F-eloszlás kumulatív eloszlás függvényének x szabadságfokú számlálóját, y szabadságfokú nevezőjét jelöli.
Kapcsolódó szócikkek
[szerkesztés]- Varianciaanalízis
- F próba (Tartalmaz egy egyirányú ANOVA példát)
- Vegyes modell
- Többváltozós varianciaanalízis (MANOVA)
- Repeated measures ANOVA
- Kétszempontos ANOVA
- Welch t-teszt
Jegyzetek
[szerkesztés]- ↑ Howell, David. Statistical Methods for Psychology. Duxbury, 324–325. o. (2002). ISBN 0-534-37770-X
- ↑ (1951. december 2.) „On the Comparison of Several Mean Values: An Alternative Approach”. Biometrika 38, 330–336. o. DOI:10.2307/2332579. JSTOR 2332579.
- ↑ Kirk, RE. Experimental Design: Procedures For The Behavioral Sciences, 3, Pacific Grove, CA, USA: Brooks/Cole (1995)
- ↑ Blair, R. C. (1981). „A reaction to 'Consequences of failure to meet assumptions underlying the fixed effects analysis of variance and covariance.'”. Review of Educational Research 51, 499–507. o. DOI:10.3102/00346543051004499.
- ↑ Randolf, E. A. (1989). „Type I error rate when real study values are used as population parameters in a Monte Carlo study”.
- ↑ Donaldson, Theodore S. (1966). „Power of the F-Test for Nonnormal Distributions and Unequal Error Variances”.
- ↑ Tiku, M. L. (1971). „Power Function of the F-Test Under Non-Normal Situations”. Journal of the American Statistical Association 66 (336), 913–916. o. DOI:10.1080/01621459.1971.10482371.
- ↑ Archivált másolat. [2018. december 4-i dátummal az eredetiből archiválva]. (Hozzáférés: 2018. december 4.)
- ↑ Sawilowsky, S. (1990). „Nonparametric tests of interaction in experimental design”. Review of Educational Research 60 (1), 91–126. o. DOI:10.3102/00346543060001091.
- ↑ Montgomery, Douglas C.. Design and Analysis of Experiments, 5th, New York: Wiley, Section 3-2. o. (2001). ISBN 9780471316497
- ↑ Moore, David S.. Introduction to the Practice of Statistics, 4th, W H Freeman & Co., 764. o. (2003). ISBN 0716796570
- ↑ Winkler, Robert L.. Statistics: Probability, Inference, and Decision, 2nd, Holt, Rinehart and Winston, 761. o. (1975)
További információk
[szerkesztés]- George Casella. Statistical design. Springer (2008. április 18.). ISBN 978-0-387-75965-4