No (kana)
This article has multiple issues. Please help improve it or discuss these issues on the talk page. (Learn how and when to remove these messages)
|
| no | |||
|---|---|---|---|
| |||
| transliteration | no | ||
| hiragana origin | 乃 | ||
| katakana origin | 乃 | ||
| Man'yōgana | 努 怒 野 乃 能 笑 荷 | ||
| spelling kana | 野原のノ (Nohara no no) | ||
| unicode | U+306E, U+30CE | ||
| braille | |||
| Note: These Man'yōgana originally represented morae with one of two different vowel sounds, which merged in later pronunciation | |||


| kana gojūon | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Kana modifiers and marks | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Multi-moraic kana | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
の, in hiragana, and ノ, in katakana, are Japanese kana, both representing one mora. In the gojūon system of ordering of Japanese morae, it occupies the 25th position, between ね (ne) and は (ha). It occupies the 26th position in the iroha ordering. Both represent the sound [no]. The katakana form is written similar to the Kangxi radical 丿, radical 4.
| Form | Rōmaji | Hiragana | Katakana |
|---|---|---|---|
| Normal n- (な行 na-gyō) |
no | の | ノ |
| nou noo nō |
のう, のぅ のお, のぉ のー |
ノウ, ノゥ ノオ, ノォ ノー |
Stroke order
[edit] |
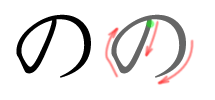
|
 |

|
To write の, begin slightly above the center, stroke downward diagonally, then round upward and continue curve around, leaving a small gap at the bottom. To write ノ, simply do a swooping curve from top-right to bottom left.
Other communicative representations
[edit]| Japanese radiotelephony alphabet | Wabun code |
| 野原のノ Nohara no "No" |
|
|

|

| |
| Japanese Navy Signal Flag | Japanese semaphore | Japanese manual syllabary (fingerspelling) | Braille dots-234 Japanese Braille |

- Full Braille representation
| の / ノ in Japanese Braille | |||
|---|---|---|---|
| の / ノ no |
のう / ノー nō/nou |
Other kana based on Braille の | |
| にょ / ニョ nyo |
にょう / ニョー nyō/nyou | ||
| Preview | の | ノ | ノ | ㋨ | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | HIRAGANA LETTER NO | KATAKANA LETTER NO | HALFWIDTH KATAKANA LETTER NO | CIRCLED KATAKANA NO | ||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 12398 | U+306E | 12494 | U+30CE | 65417 | U+FF89 | 13032 | U+32E8 |
| UTF-8 | 227 129 174 | E3 81 AE | 227 131 142 | E3 83 8E | 239 190 137 | EF BE 89 | 227 139 168 | E3 8B A8 |
| Numeric character reference | の |
の |
ノ |
ノ |
ノ |
ノ |
㋨ |
㋨ |
| Shift JIS[1] | 130 204 | 82 CC | 131 109 | 83 6D | 201 | C9 | ||
| EUC-JP[2] | 164 206 | A4 CE | 165 206 | A5 CE | 142 201 | 8E C9 | ||
| GB 18030[3] | 164 206 | A4 CE | 165 206 | A5 CE | 132 49 153 55 | 84 31 99 37 | ||
| EUC-KR[4] / UHC[5] | 170 206 | AA CE | 171 206 | AB CE | ||||
| Big5 (non-ETEN kana)[6] | 198 210 | C6 D2 | 199 102 | C7 66 | ||||
| Big5 (ETEN / HKSCS)[7] | 199 85 | C7 55 | 199 202 | C7 CA | ||||
History
[edit]Like every other hiragana, the hiragana の developed from man'yōgana, kanji used for phonetic purposes, written in the highly cursive, flowing grass script style. In the picture on the left, the top shows the kanji 乃 written in the kaisho style, and the centre image is the same kanji written in the sōsho style. The bottom part is the kana for "no", a further abbreviation.
Hentaigana and gyaru-moji variant kana forms of no can also be found.
Usage
[edit]の is a dental nasal consonant, articulated on the upper teeth, combined with a close-mid back rounded vowel to form one mora.
In the Japanese language, as well as forming words, の may be a particle showing possession. For example, the phrase "わたしのでんわ” watashi no denwa means "my telephone."
In China
[edit]
の has also proliferated on signs and labels in the Chinese-speaking world. It is used in place of the Modern Chinese possessive marker 的 de or Classical Chinese possessive marker 之 zhī, and の is pronounced in the same way as the Chinese character it replaces. This is usually done to "stand out" or to give an "exotic/Japanese feel", e.g. in commercial brand names, such as the fruit juice brand 鲜の每日C, where the の can be read as both 之 zhī, the possessive marker, and as 汁 zhī, meaning "juice".[8] In Hong Kong, the Companies Registry has extended official recognition to this practice, and permits の to be used in Chinese names of registered businesses; it is thus the only non-Chinese symbol to be granted this treatment (aside from punctuation marks with no pronunciation value).[9]
References
[edit]- ^ Unicode Consortium (2015-12-02) [1994-03-08]. "Shift-JIS to Unicode".
- ^ Unicode Consortium; IBM. "EUC-JP-2007". International Components for Unicode.
- ^ Standardization Administration of China (SAC) (2005-11-18). GB 18030-2005: Information Technology—Chinese coded character set.
- ^ Unicode Consortium; IBM. "IBM-970". International Components for Unicode.
- ^ Steele, Shawn (2000). "cp949 to Unicode table". Microsoft / Unicode Consortium.
- ^ Unicode Consortium (2015-12-02) [1994-02-11]. "BIG5 to Unicode table (complete)".
- ^ van Kesteren, Anne. "big5". Encoding Standard. WHATWG.
- ^ "@nifty:デイリーポータルZ:中国に日本の「の」が浸透した". Portal.nifty.com. Retrieved 2016-04-21.
- ^ "'Business' Required to be Registered and Application for Business Registration: Business Name", Inland Revenue Department (Hong Kong).