The {{Row_numbers}} template, which numbers the rows in a wikitable, doesn't seem to work at all, at least on the Android app and in the VisualEditor. Instead of a proper, functioning table, the entire wikitext of the table is displayed instead (due to the <nowiki> tags required for the template to function). This can be seen on articles such as List of living cardinals or List of motor yachts by length. It seems to work on the desktop (first image) and mobile browser versions. I am currently using Wikipedia Beta for Android, version 2.7.239-beta-2018-07-31 (second image). Thanks.
Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Open | None | T352451 Parsoid runs ParserAfterTidy & ParserAfterParse hooks multiple times, causing problems for DiscussionTools | |||
| Open | None | T352453 Invoke ParserBeforeInternalParse from Parsoid | |||
| Open | cscott | T257606 Extension API: strip state issues | |||
| Resolved | ssastry | T203293 Strip state: {{Row numbers}} completely fails on the Android app / VisualEditor |
Event Timeline
Comment Actions
The example from https://en.wikipedia.org/wiki/Template:Row_indexer in https://en.wikipedia.org/wiki/Special:ExpandTemplates produces,
<nowiki>{| class="wikitable"
|+test incrementor
!count !! lorem
|-
|_row_count || {{Str left|{{Lorem ipsum}}|123}}
|-
|_row_count || {{Str left|{{Lorem ipsum}}|27}}
|-
|_row_count || {{Str left|{{Lorem ipsum}}|5}}
|-
|_row_count_hold || {{Str left|{{Lorem ipsum}}|11}}
|-
|_row_count || {{Str left|{{Lorem ipsum}}|123}}
|}</nowiki>Maybe the call to local tbl_str = mw.text.unstripNoWiki (frame.args[1]); in the module is failing? To be investigated, but it at least seems like Parsoid is doing the right thing with the result of the template expansion.
Comment Actions
Digging a little deeper, since c7a8875 in core, nowikis are stripped as general markers while preprocessing only (ie. ot['pre'], and not ot['html']). A change like,
diff --git a/includes/parser/Parser.php b/includes/parser/Parser.php index 51c04ea035..d12aa3e63e 100644 --- a/includes/parser/Parser.php +++ b/includes/parser/Parser.php @@ -3953,13 +3953,13 @@ class Parser { $isFunctionTag = isset( $this->mFunctionTagHooks[strtolower( $name )] ) && ( $this->ot['html'] || $this->ot['pre'] ); + $name = strtolower( $name ); if ( $isFunctionTag ) { $markerType = 'none'; } else { - $markerType = 'general'; + $markerType = ($name === 'nowiki') ? 'nowiki' : 'general'; } if ( $this->ot['html'] || $isFunctionTag ) { - $name = strtolower( $name ); $attributes = Sanitizer::decodeTagAttributes( $attrText ); if ( isset( $params['attributes'] ) ) { $attributes = $attributes + $params['attributes'];
turns the above into,
<nowiki>{| class="wikitable"
|+test incrementor
!count !! lorem
|-
|1 || {{Str left|{{Lorem ipsum}}|123}}
|-
|2 || {{Str left|{{Lorem ipsum}}|27}}
|-
|3 || {{Str left|{{Lorem ipsum}}|5}}
|-
|3 || {{Str left|{{Lorem ipsum}}|11}}
|-
|5 || {{Str left|{{Lorem ipsum}}|123}}
|}</nowiki>which is closer to what's desired, except for the fact that this is still wrapped in nowikis and the comment in the module expects the contents to have been rendered.
-- get an already rendered table from whereever <nowiki>...</nowiki> put it
This is again because we're preprocessing only and what gets stored in the strip state hasn't been rendered yet. The difference is in this block, https://github.com/wikimedia/mediawiki/blob/master/includes/parser/Parser.php#L3961-L4010
Presumably, the fix is to take different actions in the lua module based on the output type, accounting for the above observations.
Comment Actions
When you bring Special:ExpandTemplates into it, see T199852: mw.text.unstripNoWiki doesn't work in special:ExpandTemplates.
Tags aren't processed by the PHP parser unless the parser is producing HTML (i.e. OT_HTML).[1] In other modes it just wraps them in a strip marker so they can be passed through as-is to the output.
I have no idea what Parsoid does or is intending to do.
[1]: "Function" tags are also processed when using OT_PREPROCESS.
Presumably, the fix is to take different actions in the lua module based on the output type, accounting for the above observations.
There's nothing the module itself can do. We'd need some change in Scribunto (and possibly also in the PHP parser) to let mw.text.unstripNoWiki be able to recognize and unstrip nowiki tags even when using non-OT_HTML output types.
Comment Actions
I have no idea what Parsoid does or is intending to do.
Parsoid asks the MediaWiki API to expandtemplates, which is effectively the same as T199852
There's nothing the module itself can do. We'd need some change in Scribunto (and possibly also in the PHP parser) to let mw.text.unstripNoWiki be able to recognize and unstrip nowiki tags even when using non-OT_HTML output types.
Yeah, the patch in T203293#4566886 for one
But, what are the valid use cases for being able to call mw.text.unstripNoWiki?
Comment Actions
For example. this template is using it as an adhoc escape mechanism, where heredoc args would be preferable (see T114432)
There is a caveat: the table must be wrapped inside <nowiki>...</nowiki> tags so that all of the pipe characters (|) required in a wiki table do not confuse the template into thinking that they are all individual template parameters.
Comment Actions
Except that, as you noted, isn't completely right. If we're going to do this, the module shouldn't have to sometimes remove stray <nowiki> tags and sometimes not.
But, what are the valid use cases for being able to call mw.text.unstripNoWiki?
Any situation where someone has a nowiki strip marker and wants to get at the text inside. Besides escaping as used here, sometimes there's a parameter that's intended to be text but sometimes people have to include a <nowiki> for various reasons.
True, but those don't exist yet.
Comment Actions
If we're going to do this, the module shouldn't have to sometimes remove stray <nowiki> tags and sometimes not.
There's more to it than that though, the module notes,
There are further caveats. When wrapped in <nowiki>...</nowiki>, the '<' and '>' characters that begin and end all html-like markup, are replaced with < and > html entities respectively. Because the Module cannot know if there are html entities already in use before the table was wrapped in the <nowiki>...</nowiki> tags required here, when the module replaces the html entities with '<' and '>' characters, something may break. caveat lector.
which is because it isn't acting on wikitext, it's reversing the rendered html.
Presumably, we should "fix" that and have the function return the wikitext from the body of the tag for both output types?
(I know, lots of presumptions on my part.)
Comment Actions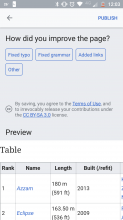
Also, if it helps, the automatic preview shown after editing and before publishing on the mobile app seems to render the template perfectly well. The screenshot is of the Table section of the List of motor yachts by length article, in preview mode.
Comment Actions
This seems to me to be a duplicate of T199852, except with more complicated reproduction steps that involve an actual template in use.
Comment Actions
That comment is incorrect. The table is not "already rendered" at that stage in the processing; the unstrip call is returning partially-escaped wikitext of the table, which the module then unescapes and processes. The actual rendering of the table happens after the module returns.
Comment Actions
That comment is incorrect. The table is not "already rendered" at that stage in the processing; the unstrip call is returning partially-escaped wikitext of the table, which the module then unescapes and processes. The actual rendering of the table happens after the module returns.
The "partial-escaping" is what was meant by "already rendered" though, which comes from,
https://github.com/wikimedia/mediawiki/blob/master/includes/parser/CoreTagHooks.php#L127
and is an indication that content is in a state that's ready to be unstripped into the parser's HTML output,
https://github.com/wikimedia/mediawiki/blob/master/includes/parser/Parser.php#L1435
The distinction I'm trying to make is that it is rendered, just that it was not interpreted as wikitext table syntax and rendered as an HTML table.
Comment Actions
I'm sitting here feeling a bit puzzled about why we should support this (particular) use case with this as the (particular) fix. Imo it's a bit pathological to use nowiki to actually get content like this.
The module should probably be able to do something else with that HTML without hacking around with nowiki.
Comment Actions
As for completely failing, VE (and the apps which I think load VE/WTE17 these days) doesn't try to work with pathological behavior.
Comment Actions
This seems to be in the general category of "hacks to escape template arguments" which T114432: [RFC] Heredoc arguments for templates (aka "hygienic" or "long" arguments) is intended to fix "properly". In this case, wrap the template argument with <nowiki> and then yank the raw content out of the strip state, to avoid having to laboriously escape the | and = characters in the arguments. We still need to determine upgrade/transition/support strategy for strip state in the legacy parser (T257606).
Comment Actions
Looks like the underlying module has been fixed to work without needing the nowiki hack. This is better solved with heredoc support, so hopefully we can boot up that project first thing after parsoid read views. This nowiki hack may still be used elsewhere (other modules, other wikis), so we will investigate if there are some ways to support this.
Comment Actions
Given that the Row Numbers module has been updated to make it work with Parsoid, I'm going to mark this resolved right now.
In T299103, I also note that this hack usage seems to be quite rare and given that, we won't support this hack in Parsoid.
However, I have reopened T272507: mw.text.unstripNoWiki doesn't unstrip when using Parsoid for now since that is not quite the same hack as the one with the Row Numbers even though the underlying cause is the same. That task focuses us more clearly on what support is missing in Parsoid and if / how we might support that.