मानक विचलन

प्रत्येक रंग की पट्टी की चौड़ाई एक मानक विचलन है।
प्रायिकता सिद्धांत और सांख्यिकी में, किसी सांख्यिकीय जनसंख्या, डाटा सेट या प्रायिकता वितरण के प्रसरण के वर्गमूल को मानक विचलन (स्टैण्डर्ड देविएशन) कहते हैं। मानक विचलन, व्यापक रूप से प्रयोग होने वाला एक मापदंड है प्रकीर्णन की माप करता है कि आंकड़े कितने 'फैले हुए' हैं। मानक विचलन बीजगणित की दृष्टि से अधिक सुविधाजनक है यद्यपि व्यावहारिक रूप से प्रत्याशित विचलन या औसत निरपेक्ष विचलन की तुलना में यह कम सुदृढ़ होता है।
इससे पता चलता है कि यहां "औसत" (मध्यमान) से कितनी भिन्नता है। इसे वितरण के मध्यमान से अंकों के औसत अंतर के रूप में माना जा सकता है कि वे मध्यमान से कितनी दूर हैं। एक निम्न मानक विचलन इंगित करता है कि डाटा के अंक मध्यमान के बहुत समीप होते हैं जबकि उच्च मानक विचलन इंगित करता है कि डाटा, मानों की एक बहुत बड़ी श्रेणी पर फैला हुआ है।
उदाहरण के लिए, संयुक्त राज्य अमेरिका में वयस्क पुरुषों की औसत ऊंचाई 70 इंच (178 से॰मी॰) है और इसके साथ ही साथ इनका मानक विचलन लगभग 3 इंच (8 से॰मी॰) है। इसका मतलब है कि अधिकांश पुरुषों (एक सामान्य वितरण की कल्पना के आधार पर लगभग 68 प्रतिशत) की ऊंचाई मध्यमान (67–73 इंच (170–185 से॰मी॰)) के 3 इंच (8 से॰मी॰) के भीतर – एक मानक विचलन है जबकि लगभग सभी पुरुषों (लगभग 95%) की ऊंचाई मध्यमान (64–76 इंच (163–193 से॰मी॰)) के 6 इंच (15 से॰मी॰) के भीतर – 2 मानक विचलन है। यदि मानक विचलन शून्य होता, तो सभी पुरुष वास्तव में 70 इंच (178 से॰मी॰) ऊंचे होते. यदि मानक विचलन 20 इंच (51 से॰मी॰) होता, तो पुरुषों की ऊंचाइयों में बहुत ज्यादा अंतर, विशेष रूप से लगभग 50 से 90 इंच (127 से 229 से॰मी॰) होता. तीन मानक विचलन के तहत वितरण को सामान्य (घंटाकार) मानकर जनसंख्या के नमूने के 99% जनसंख्या के विवरणों का अध्ययन किया गया।
जनसंख्या की परिवर्तनीयता को व्यक्त करने के अलावा, मानक विचलन को आम तौर पर सांख्यिकीय निष्कर्ष के विश्वास को मापने के लिए प्रयोग में लाया जाता है। उदाहरण के लिए, यदि एक ही चुनाव को कई बार आयोजित किया गया हो तो मतदान डाटा की त्रुटि सीमा को परिणाम के प्रत्याशित मानक विचलन की गणना द्वारा निर्धारित किया जाता है। सूचित त्रुटि सीमा विशिष रूप से मानक विचल का लगभग दोगुना – 95% आत्मविश्वास अंतराल की त्रिज्या के बराबर होती है। विज्ञान में, शोधकर्ता आमतौर पर प्रयोगात्मक डाटा के मानक विचलन की सूचना देते हैं और मानक विचलन की सीमा से बिलकुल परे एकमात्र प्रभाव को सांख्यिकी की दृष्टि से महत्वपूर्ण माना जाता है—सामान्य यादृच्छिक त्रुटि या मापन भिन्नता को इस तरह से कारणात्मक भिन्नता से अलग कर दिया जाता है। मानक विचलन, वित्त में भी महत्वपूर्ण है, जहां किसी निवेश के प्रतिफल दर का मानक विचलन, निवेश की अस्थिरता का एक माप है।
मानक विचलन संज्ञा का सबसे पहला प्रयोग[1] 1894 में कार्ल पीयरसन[2] के लेखन में किया गया और उसके बाद उनके व्याख्यानों में इसका प्रयोग किया गया। इसे एक ही विचार को व्यक्त करने वाले आरंभिक वैकल्पिक नामों के बदले प्रयोग किया गया: उदाहरण के तौर पर गॉस ने "मध्यमान त्रुटि" का प्रयोग किया।[3] मानक विचलन की एक उपयोगी विशेषता यह है कि प्रसरण के विपरीत, इसे डाटा के रूप में एक ही इकाइयों में व्यक्त किया जाता है। ध्यान दें, तथापि, कि इकाई के रूप में प्रतिशत युक्त मापन के लिए, मानक विचलन में इकाई के रूप में प्रतिशत अंक होगा.
जब जनसंख्या से आंकड़ों का केवल एक नमूना उपलब्ध हो, तो जनसंख्या के मानक विचलन का आकलन, नमूना मानक विचलन कहलाने वाले एक संशोधित मात्रा द्वारा किया जा सकता है जिसकी व्याख्या नीचे दी गई है.
एक सरल उदाहरण
[संपादित करें]मान लें कि जनसंख्या में निम्नलिखित मान हैं:
इसमें कुल आठ डाटा अंक हैं जिसका मध्यमान (या औसत) मान 5 है:
जनसंख्या के मानक विचलन की गणना करने के लिए, सबसे पहले मध्यमान से प्रत्येक डाटा अंक के अंतर का परिकलन करें और प्रतिफल का वर्ग निकालें:
उसके बाद इन मानों के योगफल को आंकड़ों की संख्या से विभाजित करें और मानक विचलन ज्ञात करने के लिए इनका वर्गमूल निकालें:
इस प्रकार, उपरोक्त उदाहरण से पता चलता है कि जनसंख्या का मानक विचलन 2 है।
उपरोक्त उदाहरण एक सम्पूर्ण जनसंख्या की कल्पना है। यदि कुछ मूल जनसंख्या से यादृच्छिक नमूना द्वारा 8 मानों को प्राप्त किया जाता है, तो नमूना मानक विचलन के परिकलन में 8 के बजाय 7 से भाग दिया जायेगा। व्याख्या के लिए जनसंख्या के मानक विचलन का आकलन अनुभाग देखें.
परिभाषा
[संपादित करें]प्रायिकता वितरण या यादृच्छिक परिवर्तनीय
[संपादित करें]मान लें, X एक यादृच्छिक परिवर्तनीय है जिसका मध्यमान मान μ है:
यहां, ऑपरेटर E, X के औसत या प्रत्याशित मान को दर्शाता है। तो, X की मानक विचलन मात्रा है
अर्थात्, मानक विचलन σ (सिग्मा), (X − μ)2 के औसत मान का वर्गमूल है।
इस मामले में जहां X, एक परिमित डाटा सेट से यादृच्छिक मान प्राप्त करता है जिसके प्रत्येक मान में एक ही प्रायिकता है, तो मानक विचलन है
या, जोड़ संकेतन का प्रयोग करने पर,
(एकविचारण) प्रायिकता वितरण का मानक विचलन, उसी प्रकार के वितरण वाले यादृच्छिक परिवर्तनीय के मानक विचलन के समान ही होता है। चूंकि इन प्रत्याशित मानों का होना आवश्यक नहीं है, इसलिए सभी यादृच्छिक परिवर्तनीय में मानक विचलन नहीं होता है। उदाहरण के लिए, एक यादृच्छिक परिवर्तनीय का मानक विचलन, जो एक कॉची वितरण का अनुसरण करता है, परिभाषित रहता है क्योंकि इसका प्रत्याशित मान, अपरिभाषित होता है।
सतत यादृच्छिक परिवर्तनीय
[संपादित करें]सतत वितरण आम तौर पर वितरण के मापदंडों के एक फलन के रूप में मानक विचलन की गणना करने के लिए एक सूत्र प्रदान करता है। साधारणतः, प्रायिकता घनत्व फलन p (x) युक्त एक सतत वास्तविक मूल्य वाले यादृच्छिक परिवर्तनीय X का मानक विचलन
है जहां
और जहां अभिन्न, निश्चित अभिन्न है जो X की श्रेणी पर x श्रेणी का कल्पित मान है।
असतत यादृच्छिक परिवर्तनीय या डाटा सेट
[संपादित करें]एक असतत यादृच्छिक परिवर्तनीय का मानक विचलन, मध्यमान से इसके मानों का मूल-मध्यमान-वर्ग (RMS) विचलन होता है।
यदि यादृच्छिक परिवर्तनीय X, समान प्रायिकता वाले N मानों (जो वास्तविक संख्या हैं) को ग्रहण करता है, तो इसके मानक विचलन σ की गणना निम्न प्रकार से की जा सकती है:
- मानों का मध्यमान, ज्ञात करें.
- प्रत्येक मान के लिए मध्यमान से इसके विचलन () की गणना करें.
- इन विचलनों के वर्ग की गणना करें.
- वर्ग किए गए विचलनों का मध्यमान ज्ञात करें. यह मात्रा, प्रसरण σ 2 है।
- प्रसरण का वर्गमूल निकालें.
इस गणना को निम्नलिखित सूत्र द्वारा वर्णित किया जाता है:
जहां , मान xi का अंकगणितीय मध्यमान है, जो निम्न रूप में परिभाषित है:
यदि सभी मानों की प्रायिकता समान न हो, लेकिन मान xi की प्रायिकता pi के समान हो, तो मानक विचलन का परिकलन निम्न प्रकार से की जा सकती है:
- और
जहां
और N', गैर-शून्य भार तत्वों की संख्या है।
एक डाटा सेट का मानक विचलन, असतत यादृच्छिक परिवर्तनीय के मानक विचलन के समान ही होता है जो डाटा सेट से विधिपूर्वक मानों की कल्पना कर सकता है जहां प्रत्येक मान का बिंदु आधिक्य, डाटा सेट में इसकी बहुलता के समानुपातिक होता है।
उदाहरण
[संपादित करें]मान लें, हम 3, 7, 7 और 19 मान वाले डाटा सेट का मानक विचलन ज्ञात करना चाहते थे।
चरण 1: 3, 7, 7 और 19 का अंकगणितीय मध्यमान (औसत) ज्ञात करें,
चरण 2: मध्यमान से प्रत्येक संख्या का विचलन ज्ञात करें,
चरण 3: प्रत्येक विचलन का वर्ग निकालें, जो बड़े विचलनों को परिवर्धित करती हैं और ऋणात्मक मानों को धनात्मक में बदल देती है,
चरण 4: उन वर्गित विचलनों का मध्यमान ज्ञात करें,
चरण 5: भागफल (वर्गित इकाइयों को पुनः नियमित इकाइयों में परिवर्तित करके) के गैर-ऋणात्मक वर्गमूल लें,
तो, समुच्चय का मानक विचलन 6 है। इस उदाहरण से यह भी पता चलता है कि, सामान्य रूप से, मानक विचलन मध्यमान निरपेक्ष विचलन (इस उदाहरण में जिसका मान 5 है) से भिन्न होता है।
ध्यान दें कि यदि उपरोक्त डाटा सेट केवल वृहत्तर जनसंख्या के एक नमूने को दर्शाए, तो जनसंख्या के मानक विचलन का आकलन करने के लिए एक संशोधित मानक विचलन की गणना (नीचे व्याख्या दी गई है) करनी होगी जो इस उदाहरण के लिए 6.93 प्रदान करेगा.
सूत्र का सरलीकरण
[संपादित करें]वर्गित विचलनों के योगफल की गणना का सरलीकरण निम्न प्रकार से किया जा सकता है।
मानक विचलन के मूल सूत्र में इसे लागू करने पर प्राप्त होता है:
(औसत के वर्ग से कम वर्गों के औसत) का वर्गमूल निकालकर इसे स्मृति में रखा जा सकता है।
जनसंख्या के मानक विचलन का आकलन
[संपादित करें]कुछ परिस्थितियों (जैसे मानकीकृत परीक्षण) में व्यक्त सम्पूर्ण जनसंख्या के मानक विचलन को ज्ञात कर सकते हैं जहां जनसंख्या के प्रत्येक सदस्य का नमूना उपलब्ध हो. ऐसे मामलों में जहां ऐसा नहीं किया जा सकता है, वहां मानक विचलन σ का आकलन जनसंख्या से लिए गए एक यादृच्छिक नमूने का परीक्षण करके किया जाता है। कुछ आकलनकर्ता नीचे दिए गए हैं:
नमूने के मानक विचलन के साथ
[संपादित करें]कभी-कभी प्रयोग किए जाने वाले σ का एक आकलनकर्ता, नमूने का मानक विचलन है जिसे s n द्वारा चिह्नित किया जाता है और जिसे निम्न रूप में परिभाषित किया गया है:
इस आकलनकर्ता में "नमूना मानक विचलन" (नीचे देखें) की अपेक्षा एक-समान छोटा मध्यमान वर्गित त्रुटि होती है और जब जनसंख्या को आम तौर पर वितरित किया जाता है तब यह अधिकतम संभावित आकलन होता है। लेकिन यह आकलनकर्ता, जब इसे एक छोटे या मामूली आकार वाले नमूने में कार्यान्वित किया जाता है, तब बहुत कम हो जाता है: यह एक पक्षपाती आकलनकर्ता है।
नमूना मानक विचलन के साथ
[संपादित करें]σ प्रयोग का सर्वाधिक सामान्य आकलनकर्ता एक समायोजित संस्करण, नमूना मानक विचलन है जिसे "s" द्वारा चिह्नित किया जाता है और निम्न रूप में परिभाषित है:
जहां , नमूना है और , नमूने का मध्यमान है। इस संशुद्धि (N के बजाय N − 1 का प्रयोग) को बेसेल की संशुद्धि के रूप में जाना जाता है। इस संशुद्धि का कारण यह है कि s 2, अंतर्निहित जनसंख्या के प्रसरण σ2 का एक निष्पक्ष आकलनकर्ता है, यदि वह प्रसरण मौजूद हो और नमूने के मान को प्रतिस्थापन के साथ स्वतंत्रतापूर्वक तैयार किया गया हो. हालांकि, s, मानक विचलन σ का एक निष्पक्ष आकलनकर्ता नहीं है, बल्कि यह जनसंख्या के मानक विचलन के न्यून-आकलन में सहायक है।
ध्यान दें कि शब्द "नमूने का मानक विचलन" असंशुद्ध आकलनकर्ता (N का प्रयोग करके) के लिए प्रयोग में लाया जाता है जबकि शब्द "नमूना मानक विचलन" संशुद्ध आकलनकर्ता (N − 1 का प्रयोग करके) के लिए प्रयोग में लाया जाता है। हर N − 1, अवशिष्ट के अदिश में स्वतंत्रता की डिग्री की संख्या है, .
अन्तःचतुर्थक श्रेणी के साथ
[संपादित करें]सांख्यिकी
(1.35 एक सन्निकटन है) जहां IQR, नमूने का अन्तःचतुर्थक श्रेणी है, σ का संगत आकलन है यदि जनसंख्या को सामान्य रूप से वितरित किया गया हो. अन्तःचतुर्थक श्रेणी IQR, डाटा के तीसरे चतुर्थक और प्रथम चतुर्थक का अंतर है। नमूना मानक विचलन से एक के संबंध में इस आकलनकर्ता की अनन्तस्पर्शी सापेक्ष दक्षता (ARE), 0.37 है। इसलिए सामान्य डाटा के लिए नमूना मानक विचलन से एक का प्रयोग करना बेहतर होता है; जब डाटा में अधिक जानकारी होती है तब यह आकलनकर्ता और अधिक कुशल हो सकता है।[4][not in citation given][संदिग्ध]
अन्य आकलनकर्ता
[संपादित करें]हालांकि σ के लिए एक निष्पक्ष आकलनकर्ता को ज्ञात किया जाता है जब यादृच्छिक परिवर्तनीय को सामान्य रूप से वितरित किया जाता है, सूत्र जटिल होता है और एक मामूली संशुद्धि की फलगणना करता है: अधिक जानकारी के लिए मानक विचलन का निष्पक्ष आकलन देखें. इसके अलावा, निष्पक्षता (शब्द के इस अर्थ में) हमेशा वांछनीय नहीं होता है: एक आकलनकर्ता का पक्षपात देखें.
मानक विचलन के गुण
[संपादित करें]स्थिरांक c और यादृच्छिक परिवर्तनीय X और Y के लिए:
जहां और क्रमशः प्रसरण और सहप्रसरण के प्रतीक हैं।
व्याख्या और अनुप्रयोग
[संपादित करें]एक बड़ा मानक विचलन इंगित करता है कि डाटा अंक मध्यमान से दूर होते हैं और एक लघु मानक विचलन इंगित करता है कि वे मध्यमान के चारों-तरफ़ काफी नज़दीकी से समूहीकृत होते हैं।
उदाहरण के लिए, तीन जनसंख्या {0, 0, 14, 14}, {0, 6, 8, 14} and {6, 6, 8, 8} में से प्रत्येक का मध्यमान 7 है। उनके मानक विचलन क्रमशः 7, 5 और 1 हैं। तीसरी जनसंख्या का मानक विचलन अन्य दो विचलनों की अपेक्षा कम होता है क्योंकि इनके सभी मान 7 के करीब हैं। एक अस्पष्ट अर्थ में, मानक विचलन हमें यह बताता है कि डाटा के अंक माध्यम से कितिनी दूर होने चाहिए. इसमें उतनी ही इकाइयां होगी जितनी स्वयं डाटा अंकों में होते हैं। उदाहरण के लिए, यदि डाटा सेट {0, 6, 8, 14} चार भाई-बहनों की की एक संख्या की आयु को वर्ष में प्रदर्शित करता है तो मानक विचलन 5 वर्ष होता है।
एक दूसरे उदाहरण के तौर पर, जनसंख्या {1000, 1006, 1008, 1014} चार एथलीटों द्वारा तय की गई दूरियों को मीटर में व्यक्त करता है। इसका मध्यमान 1007 मीटर है और मानक विचलन 5 मीटर है।
मानक विचलन, अनिश्चितता की एक माप के रूप में कार्य कर सकते हैं। उदाहरण के लिए, भौतिक विज्ञान में दोहराए गए मापन के एक समूह के प्रतिवेदित मानक विचलन को उन मापनों की सुस्पष्टता प्रदान करनी चाहिए. जब यह निश्चय किया जाता है कि क्या मापन, सैद्धांतिक भविष्यवाणी से सहमत है तब उन मापनों का मानक विचलन महत्त्व निर्णायक होता है: यदि मापन का मध्यमान भविष्यवाणी से बहुत दूर हो, तो परीक्षणमूलक सिद्धांत को संभवतः परिशोधित करने की आवश्यकता है। इससे यह अर्थ निकलता है कि वे मानों की श्रेणी से बाहर चले जाते हैं जिसके होने की उचित उम्मीद की जा सके यदि भविष्यवाणी सही होती और मानक विचलन मात्र को उचित ढंग से निर्धारित किया जाता. भविष्यवाणी अंतराल देखें.
अनुप्रयोग के उदाहरण
[संपादित करें]मानों के एक समूह के मानक विचलन को समझने का व्यवहारिक मान निर्धारण के अधीन है कि "औसत" (मध्यमान) से कितनी भिन्नता है।
मौसम
[संपादित करें]एक साधारण उदाहरण के रूप में, शहरों के औसत तापमान पर विचार करें. जबकि दो शहरों का औसत तापमान 15 °C हो सकता है, यह समझने में सहायक है कि समुद्र तट के पास के शहर की सीमा अंतर्देशीय शहरों की तुलना में छोटी है जो यह स्पष्ट करता है कि जबकि औसत समान है लेकिन समुद्र तट के समीप की अपेक्षा अंतर्देशीय भिन्नता के होने की अधिक सम्भावना है।
तो, एक शहर का औसत तापमान 15 होता है जिसका अधिकतम तापमान 25 °C और निम्न तापमान 5 °C हो और ऐसा दूसरे शहर के साथ भी होता है जिसका अधिकतम तापमान 18 और निम्न तापमान 12 हो. मानक विचलन हमें पहचानने की अनुमति प्रदान करता है कि व्यापक भिन्नता वाले शहर का औसत और इस प्रकार एक उच्च मानक विचलन तापमान का उतना विश्वसनीय भविष्यवाणी प्रदान नहीं करेगा जितना कम भिन्नता वाला और निम्न मानक विचलन वाला शहर का औसत प्रदान करेगा.
खेल
[संपादित करें]इसे समझने का एक दूसरा तरीका है कि हम खेल की टीमों पर विचार करें. किसी भी श्रेणी समूह में, ऐसे टीम होंगे जो कभी उच्च दर प्राप्त करेंगे तो कभी खराब। इसकी संभावना है कि जो टीम स्टैंडिंग में नेतृत्व करते हैं, वे ऐसी विपरीतता का प्रदर्शन नहीं करेंगे लेकिन अधिकांश श्रेणियों में वे अच्छा प्रदर्शन करेंगे. प्रत्येक श्रेणी में उनकी रेटिंग का मानक विचलन जितना कम होगा, वे उतना ही अधिक संतुलित और सुसंगत होंगे. जबकि उच्च मानक विचलन वाले टीम अधिक अपूर्वानुमेय होंगे. उदाहरण के लिए, एक टीम जो अधिकांश श्रेणियों में लगातार खराब है, उसमें निम्न मानक विचलन होगा. एक टीम जो ज्यादातर श्रेणियों में लगातार अच्छा है, उसमें भी निम्न मानक विचलन होगा. हालांकि, एक उच्च मानक विचलन वाला टीम उस प्रकार टीम हो सकता है जो बहुत स्कोर (सशक्त आक्रमण) बनाता है लेकिन बहुत छूट (कमज़ोर सुरक्षा) भी देते हैं, या एक दूसरे के विपरीत, जिसका आक्रमण ख़राब हो सकता है लेकिन स्कोर करने में मुश्किलें पैदा कर इसकी क्षतिपूर्ति करता है।
यह भविष्यवाणी करने की कोशिश करना कि किसी भी निर्धारित दिन को कौन सी टीम जीतेगी, इसके लिए टीम के विभिन्न "आंकड़ों" की रेटिंग के मानक विचलन पर ध्यान देना होगा जिसके अंतर्गत असंगति यह समझने की कोशिश में शक्ति बनाम कमजोरी का मिलान कर सकता है कि कौन से कारक अंतिम स्कोरिंग परिणाम के सशक्त संकेतकों के रूप में अभिभावी हो सकते हैं।
रेसिंग में, एक चालक को लगातार चक्कर लगाने के लिए समय प्रदान किया जाता है। चक्कर की संख्या के निम्न मानक विचलन वाला चालक, उच्च मानक विचलन वाले चालक की अपेक्षा अधिक अनुकूल होता है। इस जानकारी को यह समझने में मदद करने के लिए प्रयोग में लाया जा सकता है कि चक्करों की संख्या को घटाने के लिए अवसर कहां प्राप्त हो सकते हैं।
वित्त
[संपादित करें]वित्त में, मानक विचलन किसी प्रदत्त प्रतिभूति (शेयरों, बांडों, संपत्ति, आदि) से जुड़े जोख़िम या प्रतिभूतियों (सक्रिय रूप से प्रबंधित म्युचुअल फंड, इंडेक्स म्युचुअल फंड, या ETFs) के एक पोर्टफोलियो के जोख़िम का एक प्रदर्शन है। जोख़िम यह निर्धारित करने का एक महत्वपूर्ण कारक है कि किस तरह निवेश के पोर्टफोलियो का कुशलतापूर्वक प्रबंधन करना चाहिए क्योंकि यह आस्ति और/या पोर्टफोलियो के प्रतिफल की भिन्नता का निर्धारण करता है और निवेशकों को निवेश के फैसलों के लिए एक गणितीय आधार प्रदान करता है (जिसे मध्यमान-प्रसरण इष्टतमीकरण के रूप में जाना जाता है). जोख़िम की समग्र अवधारणा यह है कि जब इसमें वृद्धि होती है तो अर्जित जोख़िम प्रीमियम के परिणामस्वरूप आस्ति के प्रत्याशित लाभ में वृद्धि होगी – दूसरे शब्दों में, निवेशकों को निवेश पर अधिक प्रतिफल की उम्मीद करनी चाहिए जब कथित निवेश में उच्च स्तरीय जोख़िम हो या उस प्रतिफल की अनिश्चितता हो. निवेशों के मूल्यांकन के समय निवेशकों को प्रत्याशित प्रतिफल और भविष्यत् प्रतिफलों की अनिश्चितता दोनों का आकलन करना चाहिए. मानक विचलन, भविष्यत् प्रतिफलों की अनिश्चितता का एक परिमानित आकलन प्रदान करता है।
उदाहरण के लिए, मान लें कि किसी निवेशक को दोनों स्टॉक में से किसी एक का चयन करना था। स्टॉक A का पिछले 20 वर्षों से औसत प्रतिफल 10% था जिसका मानक विचलन 20 प्रतिशत अंक (pp) था और स्टॉक B का उसी समयावधि में औसत प्रतिफल का मान 12% था लेकिन उसके उच्च मानक विचलन का मान 30 pp था। जोख़िम और प्रतिफल के आधार पर, एक निवेशक निर्णय कर सकता है कि स्टॉक A अधिक सुरक्षित विकल्प है क्योंकि स्टॉक B के प्रतिफल के अतिरिक्त 2% अंक का अतिरिक्त 10 pp मानक विचलन (अधिक जोख़िम या प्रत्याशित प्रतिफल की अनिश्चितता) के सामने कोई मूल्य नहीं है। एक ही परिस्थितियों में स्टॉक A की अपेक्षा स्टॉक B के आरंभिक निवेश में कई बार कमी होने की संभावना होती है (लेकिन आरंभिक निवेश में वृद्धि होने की भी संभावना होती है) और औसतन केवल 2% अधिक प्रतिफल प्राप्त होने का आकलन किया जाता है। इस उदाहरण में, स्टॉक A में लगभग 10%, 20 pp अधिक या कम (30% से -10% की सीमा), भविष्यत् वर्ष के प्रतिफल का लगभग दो-तिहाई कमाने की उम्मीद है। भविष्य में अधिक से अधिक संभावित प्रतिफल या परिणाम पर विचार करने के समय, एक निवेशक को 10% अधिक या कम 60 pp, या 70% से (-)50% तक की सीमा तक के परिणाम की उम्मीद करनी चाहिए जिसमें औसत प्रतिफल (संभावित प्रतिफल का लगभग 99.7%) के तीन मानक विचलनों का परिणाम शामिल होता है।
एक प्रदत्त समयावधि के दौरान एक प्रतिभूति के औसत प्रतिफल (या अंकगणितीय मध्यमान) की गणना करने पर आस्ति का एक प्रत्याशित प्रतिफल उत्पन्न होगा. प्रत्येक अवधि के लिए, वास्तविक प्रतिफल से प्रत्याशित प्रतिफल को घटाने के फलस्वरूप प्रसरण की प्राप्ति होती है। आस्ति के समग्र जोख़िम के परिणाम के प्रभाव को ज्ञात करने के लिए प्रत्येक अवधि के प्रसरण का वर्ग निकालें. अवधि का प्रसरण जितना अधिक होता है, प्रतिभूति उतना ही अधिक जोख़िम वहन करता है। वर्गित प्रसरणों का औसत निकालने के परिणामस्वरूप आस्ति से जुड़े समग्र इकाइयों का माप प्राप्त होता है। इस प्रसरण का वर्गमूल ज्ञात करने के परिणामस्वरूप प्रश्नाधीन निवेश उपकरण का मानक विचलन प्राप्त होगा.
जनसंख्या मानक विचलन को बोलिंगर पट्टियों, व्यापक तौर पर अपनाए गए एक तकनीकी विश्लेषण उपकरण की चौड़ाई को निर्धारित करने के लिए प्रयोग किया जाता है। उदाहरण के लिए, ऊपरी बोलिंगर पट्टी को निम्न रूप में दिया जाता है:
ज्यामितीय व्याख्या
[संपादित करें]कुछ ज्यामितीय अंतर्दृष्टि प्राप्त करने के लिए, हमलोग तीन मानों, x 1, x 2, x 3 की एक जनसंख्या के साथ शुरू करेंगे. यह एक अंक P = R 3 में (x 1, x 2, x 3) को परिभाषित करता है। मान लें रेखा L = {({0}r, r, r) : R में r }. यही "मुख्य विकर्ण" है जो उत्पत्ति स्थल से होकर गुजरता है। यदि हमारे सभी तीनों प्रदत्त मान बराबर थे, तो मानक विचलन शून्य होगा और P, L पर अवस्थित होगा. यह मानना अनुचित नहीं है कि मानक विचलन, P से L की दूरी से संबंधित है। और वास्तव में यही विषय है। P से रेखा L तक लम्बवत रूप से जाने पर, एक बिंदु से टकराता है:
जिसका निर्देशांक उन मानों का मध्यमान है जिसे लेकर हमने शुरुआत की थी। बीजगणित से थोड़ा बहुत पता चलता है कि P और R के बीच की दूरी (जो P और रेखा L के बीच की दूरी के समान है) σ√3 द्वारा प्रदत्त है। एक अनुरूप सूत्र (3 को N द्वारा प्रतिस्थापित करके) N मानों की एक जनसंख्या के लिए भी वैध है; उसके बाद हमें R N में काम करना है। मानक विचलन
चेबीशेव की असमानता
[संपादित करें]एक अवलोकन शायद ही मध्यमान से दूर कुछ मानक विचलनों से अधिक होता है। चेबीशेव की असमानता, सभी वितरणों के लिए निम्नलिखित सीमा पर ज़ोर देता है जिसके लिए मानक विचलन को परिभाषित किया गया है।
- कम से कम मानों का 50%, मध्यमान से √2 मानक विचलनों के भीतर होते हैं।
- कम से कम मानों का 75%, मध्यमान से 2 मानक विचलनों के भीतर होते हैं।
- कम से कम मानों का 89%, मध्यमान से 3 मानक विचलनों के भीतर होते हैं।
- कम से कम मानों का 94%, मध्यमान से 4 मानक विचलनों के भीतर होते हैं।
- कम से कम मानों का 96%, मध्यमान से 5 मानक विचलनों के भीतर होते हैं।
- कम से कम मानों का 97%, मध्यमान से 6 मानक विचलनों के भीतर होते हैं।
- कम से कम मानों का 96%, मध्यमान से 5 मानक विचलनों के भीतर होते हैं।
- कम से कम मानों का 94%, मध्यमान से 4 मानक विचलनों के भीतर होते हैं।
- कम से कम मानों का 89%, मध्यमान से 3 मानक विचलनों के भीतर होते हैं।
- कम से कम मानों का 75%, मध्यमान से 2 मानक विचलनों के भीतर होते हैं।
और सामान्य तौर पर:
- कम से कम मानों का (1 − 1/k 2) × 100%, मध्यमान से k मानक विचलनों के भीतर होते हैं।[5]
सामान्य रूप से वितरित डाटा के नियम
[संपादित करें]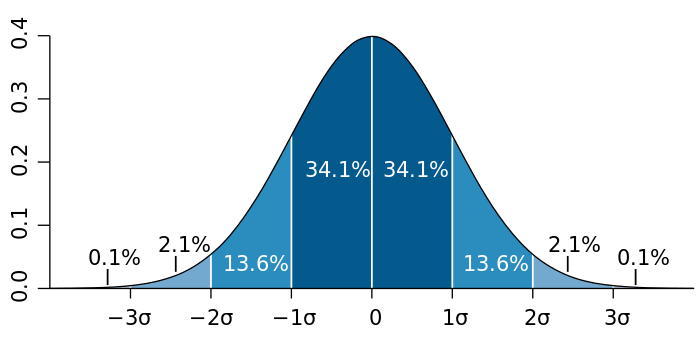
केंद्रीय सीमा प्रमेय का कहना है कि कई स्वतंत्र, समानतापूर्वक वितरित यादृच्छिक परिवर्तनीय के योगफल का वितरण, सामान्य वितरण की ओर जाता है। यदि कोई डाटा वितरण लगभग सामान्य है तो मानों का लगभग 68% मान, मध्यमान (गणित की दृष्टि से, μ ± σ, जहां μ अंकगणितीय मध्यमान है) के 1 मानक विचलन के भीतर, मानों का लगभग 95% मान, दो मानक विचलनों (μ ± 2σ) के भीतर और लगभग 99.7%, 3 मानक विचलनों (μ ± 3σ) के भीतर होते हैं। इसे 68-95-99.7 नियम या अनुभवजन्य नियम के रूप में जाना जाता है।
Z के विभिन्न मानों के लिए, मानों के प्रतिशत जिनके सममित अंतराल (−z σ, z σ) में और उसके बाहर होने की उम्मीद है, इस प्रकार है:
| z σ | CI के भीतर प्रतिशत | CI के बाहर प्रतिशत | CI के बाहर अनुपात |
|---|---|---|---|
| 1σ | 68.268949199% | 31.731050799% | 1 / 3.1514871 |
| 1.645σ | 90% | 10% | 1 / 10 |
| 1.960σ | 95% | 5% | 1 / 20 |
| 2σ | 95.4499736% | 4.550026399% | 1 / 21.977894 |
| 2.576σ | 99% | 1% | 1 / 100 |
| 3σ | 99.730020399% | 0.2699796% | 1 / 370.398 |
| 3.2906σ | 99.9% | 0.1% | 1 / 1000 |
| 4σ | 99.993666% | 0.006334% | 1 / 15,788 |
| 5σ | 99.999942669% | 0.000057330000% | 1 / 17,44,278 |
| 6σ | 99.999999802% | 0.000000197% | 1 / 506,800,000 |
| 7σ | 99.999 999 999 7440% | 0.000000000% | 1 / 3,90,60,00,00,000 |
सीमा के भीतर के प्रतिशत को सूत्र द्वारा परिभाषित किया गया है: %perc = erf(nσ / √2) × 50% + 50%
मानक विचलन और मध्यमान के बीच संबंध
[संपादित करें]डाटा के एक सेट के मध्यमान और मानक विचलन को आम तौर पर एक साथ प्रतिवेदित किया जाता है। एक खास मायने में, यदि डाटा के केंद्र को मध्यमान के सन्दर्भ में मापा जाता है तो मानक विचलन, सांख्यिकीय प्रकीर्णन का एक "स्वाभाविक" माप होता है। इसका कारण यह है कि मध्यमान का मानक विचलन, अन्य किसी बिंदु से कम होता है। सटीक विवरण निम्नलिखित है: मान लें x 1, ..., x n वास्तविक संख्याएं हैं और फलन को परिभाषित करें:
कलन का प्रयोग करने या वर्ग को पूरा करने पर, संभवतः यह पता चलता है कि σ(r) का मध्यमान अद्वितीय रूप से न्यूनतम है:
एक नमूने की भिन्नता का गुणांक, मानक विचलन और मध्यमान का अनुपात होता है। यह एक आयामरहित संख्या है जिसे एक दूसरे के समीप मध्यमानों वाले जनसंख्याओं की बीच के प्रसरण की राशि की तुलना करने के लिए प्रयोग में लाया जा सकता है। कारण यह है कि यदि आप एक ही मानक विचलन वाले लेकिन अलग-अलग मध्यमान वाले जनसंख्याओं की तुलना करते हैं तो भिन्नता का गुणांक, कम मध्यमान वाले जनसंख्या के लिए अधिक होगा. इस प्रकार डाटा की परिवर्तनीयता की तुलना करने में, भिन्नता के गुणांक को बड़ी सावधानी से प्रयोग किया जाना चाहिए और बेहतर होगा यदि इसे किसी दूसरी विधि की सहायता से प्रतिस्थापित किया जाए.
यदि हम वितरण के नमूने के द्वारा मध्यमान प्राप्त करना चाहते हैं तो मध्यमान का मानक विचलन निम्न द्वारा वितरण के मानक विचलन से संबंधित होता है
जहां N, मध्यमान का आकलन करने के लिए प्रयुक्त नमूने के अवलोकन की संख्या है।
तेज़ी से गणना करने के तरीके
[संपादित करें]निम्नलिखित दो सूत्र, एक चालू (सतत) मानक विचलन को प्रदर्शित कर सकते हैं। तीन घातों s 0,1,2 के योगफल के एक सेट को x k के रूप में चिह्नित, x के N मानों के एक सेट पर प्रत्येक का परिकलन किया जाता है।
ध्यान दें कि s 0, x को शून्य घात में विकसित कर देता है और चूंकि x 0 का मान हमेशा 1 होता है, इसलिए s 0, N का मूल्यांकन करता है।
इन तीन चालू योगफलों के परिणाम को देखते हुए, चालू मानक विचलन के मौजूदा मान का परिकलन करने के लिए मानों s 0,1,2 को कभी भी प्रयोग में लाया जा सकता है। s j की परिभाषा, दो अलग-अलग चरणों (योगफल परिकलन s j और गणना) को प्रदर्शित कर सकते हैं।
इसी प्रकार नमूना मानक विचलन के लिए,
एक कंप्यूटर कार्यान्वयन में, चूंकि तीन s j योगफल अधिक हो जाते हैं, इसलिए हमें राउंड-ऑफ त्रुटि, अंकगणित अतिप्रवाह और अंकगणित अनुप्रवाह पर विचार करने की आवश्यकता है। निम्न विधि कम राउंडिंग त्रुटियों वाले चालू योगफल विधि की गणना करता है:
जहां A, मध्यमान मान है।
या
नमूना प्रसरण:
मानक विचलन
भारित गणना
[संपादित करें]जब मान x i, को असमान भार wi के साथ भारित किया जाता है, तो घात योग s 0,1,2 में से प्रत्येक निम्न प्रकार से परिकलन किया जाता है:
और मानक विचलन समीकरण अपरिवर्तित रहते हैं। ध्यान दें कि s 0 अब भारों का योग है न कि N नमूनों की संख्या.
कम राउंडिंग त्रुटियों वाले वृद्धिशील विधि को भी कुछ अतिरिक्त जटिलता के साथ लागू किया जा सकता है।
भारों के एक चालू योग का अवश्य परिकलन किया जाना चाहिए:
और जिन जगहों में ऊपर 1/i का प्रयोग हुआ है, उन्हें अवश्य ही wi /Wi द्वारा प्रतिष्ठापित किया जाना चाहिए:
अंतिम विभाजन में,
और
जहां n, तत्वों की कुल संख्या है और 'n, गैर-शून्य भार वाले तत्वों की संख्या है। यदि भारों को 1 के समान मान लिया जाए तो उपरोक्त सूत्र, उपरोक्त प्रदत्त सरल सूत्रों के समान हो जाता है।
मानक विचलन का मेल
[संपादित करें]जनसंख्या आधारित सांख्यिकी
[संपादित करें]गैर-अतिव्यापी उप-जनसंख्याओं के मानक विचलनों को निम्न प्रकार से जोड़ सकते हैं यदि प्रत्येक का आकार (वास्तविक या एक-दूसरे के सापेक्ष) और मध्यमान ज्ञात हो:
और
जहां
उदाहरण के लिए, मान लें कि ज्ञात है कि औसत अमेरिकी पुरुष की मध्यमान ऊंचाई 70 इंच और मानक विचलन 3 इंच है और यह भी ज्ञात है कि औसत अमेरिकी महिला की मध्यमान ऊंचाई 65 इंच और मानक विचलन 2 इंच है। अमेरिकी वयस्कों के मध्यमान और मानक विचलन की निम्न प्रकार से गणना की जा सकती है:
XM के माध्यम से अधिक सामान्य M गैर-अतिव्यापी डाटा सेट्स X1 के लिए:
और
जहां
यदि दो अतिव्यापी जनसंख्याओं के आकार (वास्तविक या एक दूसरे के सापेक्ष), मध्यमान और मानक विचलन, जनसंख्याओं के साथ-साथ उनके प्रतिच्छेदन के लिए ज्ञात हों, तो सम्पूर्ण जनसंख्या के मानक विचलन की अभी भी निम्न प्रकार से गणना की जा सकती है:
और
नमूना आधारित सांख्यिकी
[संपादित करें]गैर-अतिव्यापी उप-नमूनों के मानक विचलनों को निम्न प्रकार से जोड़ सकते हैं यदि प्रत्येक का वास्तविक आकार और मध्यमान ज्ञात हो:
और
जहां
XM के माध्यम से अधिक सामान्य M गैर-अतिव्यापी डाटा सेट्स X1 के लिए:
और
जहां
यदि दो अतिव्यापी नमूनों के आकार, मध्यमान और मानक विचलन, नमूनों के साथ-साथ उनके प्रतिच्छेदन के लिए ज्ञात हों, तो नमूनों के मानक विचलन की अभी भी गणना की जा सकती है। सामान्य तौर पर,
और
इन्हें भी देखें
[संपादित करें]
|
| This article includes a list of references, but its sources remain unclear because it has insufficient inline citations. Please help to improve this article by introducing more precise citations where appropriate. (जनवरी 2010) |
सन्दर्भ
[संपादित करें]- ↑ Dodge, Yadolah (2003). The Oxford Dictionary of Statistical Terms. Oxford University Press. आई॰ऍस॰बी॰ऍन॰ 0-19-920613-9.
- ↑ Pearson, Karl (1894). "On the dissection of asymmetrical frequency curves". Phil. Trans. Roy. Soc. London, Series A. 185: 719–810.
- ↑ Miller, Jeff. "Earliest Known Uses of Some of the Words of Mathematics". मूल से 4 मार्च 2009 को पुरालेखित. अभिगमन तिथि 19 मार्च 2010.
- ↑ दासगुप्ता और हाफ़ (2006), "प्रसार के विभिन्न मापों के मध्य परस्पर संबंधों का अनन्तस्पर्शी विस्तार". जर्नल ऑफ़ स्टैटिस्टिकल प्लानिंग ऐंड इनफियरेंस . खंड 136, pp. 2197–2213
- ↑ ग़ाहरमानी, सईद (2000). फंडामेंटल्स ऑफ़ प्रोबैबिलिटी (द्वितीय संस्करण). प्रेंटिस हॉल: न्यू जर्सी. पृष्ठ 438.
बाहरी कड़ियाँ
[संपादित करें]- मानक विचलन को समझने और उसकी गणना करने का एक गाइड
- परस्पर संवादात्मक प्रदर्शन और मानक विचलन गणक
- मानक विचलन - बिना गणित की व्याख्या
- मानक विचलन, एक प्रारंभिक परिचय
- मानक विचलन, लेखकों और पत्रकारों के लिए एक सरल व्याख्या
- मानक विचलन गणक
- टेक्सास A&M मानक विचलन और आत्मविश्वास अंतराल गणक
[[श्रेणी:सांख्यिकी विचलन और प्रकीर्णन]] [[श्रेणी:सांख्यिकी सारांश]]