
The Iris flower data set or Fisher's Iris data set is a multivariate data set introduced by the British statistician and biologist Ronald Fisher in his 1936 paper The use of multiple measurements in taxonomic problems as an example of linear discriminant analysis.
It is sometimes called Anderson's Iris data set because Edgar Anderson collected the data to quantify the morphologic variation of Iris flowers of three related species.
Two of the three species were collected in the Gaspé Peninsula "all from the same pasture, and picked on the same day and measured at the same time by the same person with the same apparatus". The data set consists of 50 samples from each of three species of Iris (Iris setosa, Iris virginica and Iris versicolor). Four features were measured from each sample: the length and the width of the sepals and petals, in centimetres. Based on the combination of these four features, Fisher developed a linear discriminant model to distinguish the species from each other.
Source: https://en.wikipedia.org/wiki/Iris_flower_data_set
This data sets consists of 3 different types of irises’ ( Setosa, Versicolour, and Virginica ) petal and sepal length, stored in a 150x4 numpy.ndarray
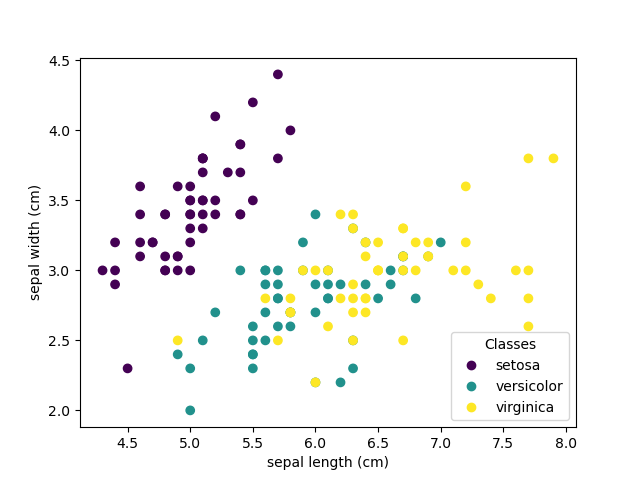
Two Dimensional View
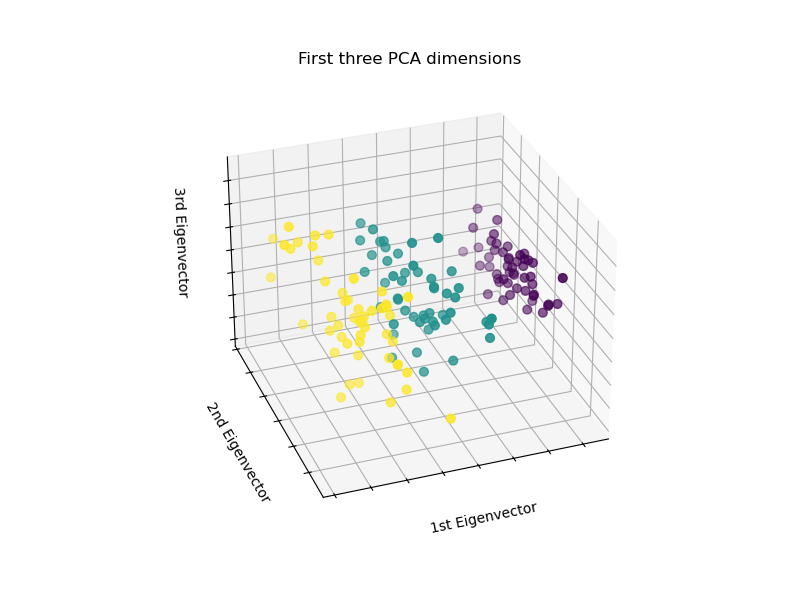
Three Dimensional View
The rows being the samples and the columns being: Sepal Length, Sepal Width, Petal Length and Petal Width
This is perhaps the best known database to be found in the pattern recognition literature. Fisher's paper is a classic in the field and is referenced frequently to this day. (See Duda & Hart, for example.) The data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant. One class is linearly separable from the other 2; the latter are NOT linearly separable from each other.
Class of iris plant.
This is an exceedingly simple domain. This data differs from the data presented in Fishers article (identified by Steve Chadwick, spchadwick '@' espeedaz.net ). The 35th sample should be: 4.9,3.1,1.5,0.2,"Iris-setosa" where the error is in the fourth feature. The 38th sample: 4.9,3.6,1.4,0.1,"Iris-setosa" where the errors are in the second and third features.
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class: -- Iris Setosa -- Iris Versicolour -- Iris Virginica
Source: https://archive.ics.uci.edu/ml/datasets/iris
Ben Hammer, IRIS Dataset.
*P.S. Though I have specifically given links to results / graphs after each line of code, all the results / graphs can be found here: https://tinyurl.com/y8usb5m7