🚀 Check out our new product DataChain (and give it a ⭐!) if you need to version and process a large number of files. Contact us at support@iterative.ai to discuss commercial solutions and support for AI reproducibility and data management scenarios.
Website • Docs • Blog • Tutorial • Related Technologies • How DVC works • VS Code Extension • Installation • Contributing • Community and Support







Data Version Control or DVC is a command line tool and VS Code Extension to help you develop reproducible machine learning projects:
- Version your data and models. Store them in your cloud storage but keep their version info in your Git repo.
- Iterate fast with lightweight pipelines. When you make changes, only run the steps impacted by those changes.
- Track experiments in your local Git repo (no servers needed).
- Compare any data, code, parameters, model, or performance plots.
- Share experiments and automatically reproduce anyone's experiment.
Please read our Command Reference for a complete list.
A common CLI workflow includes:
| Task | Terminal |
|---|---|
| Track data | $ git add train.py params.yaml$ dvc add images/ |
| Connect code and data | $ dvc stage add -n featurize -d images/ -o features/ python featurize.py$ dvc stage add -n train -d features/ -d train.py -o model.p -M metrics.json python train.py |
| Make changes and experiment | $ dvc exp run -n exp-baseline$ vi train.py$ dvc exp run -n exp-code-change |
| Compare and select experiments | $ dvc exp show$ dvc exp apply exp-baseline |
| Share code | $ git add .$ git commit -m 'The baseline model'$ git push |
| Share data and ML models | $ dvc remote add myremote -d s3://mybucket/image_cnn$ dvc push |
We encourage you to read our Get Started docs to better understand what DVC does and how it can fit your scenarios.
The closest analogies to describe the main DVC features are these:
- Git for data: Store and share data artifacts (like Git-LFS but without a server) and models, connecting them with a Git repository. Data management meets GitOps!
- Makefiles for ML: Describes how data or model artifacts are built from other data and code in a standard format. Now you can version your data pipelines with Git.
- Local experiment tracking: Turn your machine into an ML experiment management platform, and collaborate with others using existing Git hosting (Github, Gitlab, etc.).
Git is employed as usual to store and version code (including DVC meta-files as placeholders for data). DVC stores data and model files seamlessly in a cache outside of Git, while preserving almost the same user experience as if they were in the repo. To share and back up the data cache, DVC supports multiple remote storage platforms - any cloud (S3, Azure, Google Cloud, etc.) or on-premise network storage (via SSH, for example).
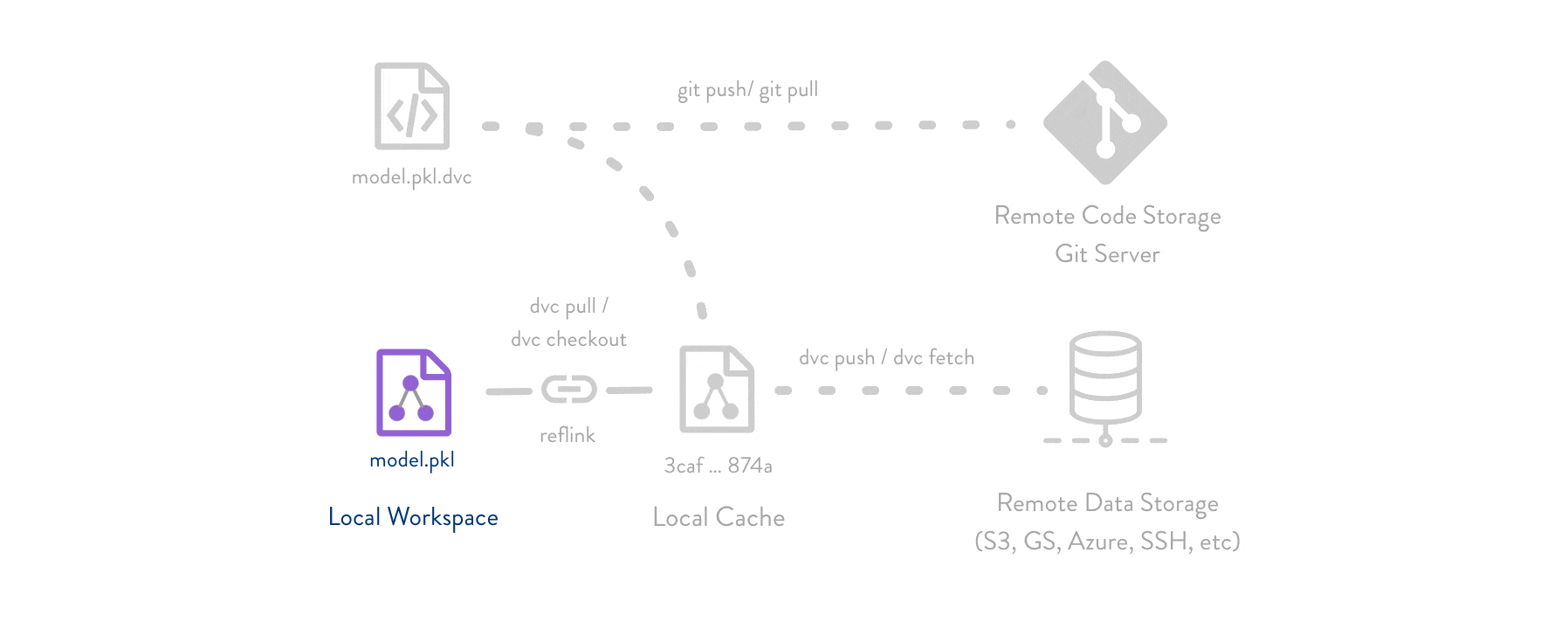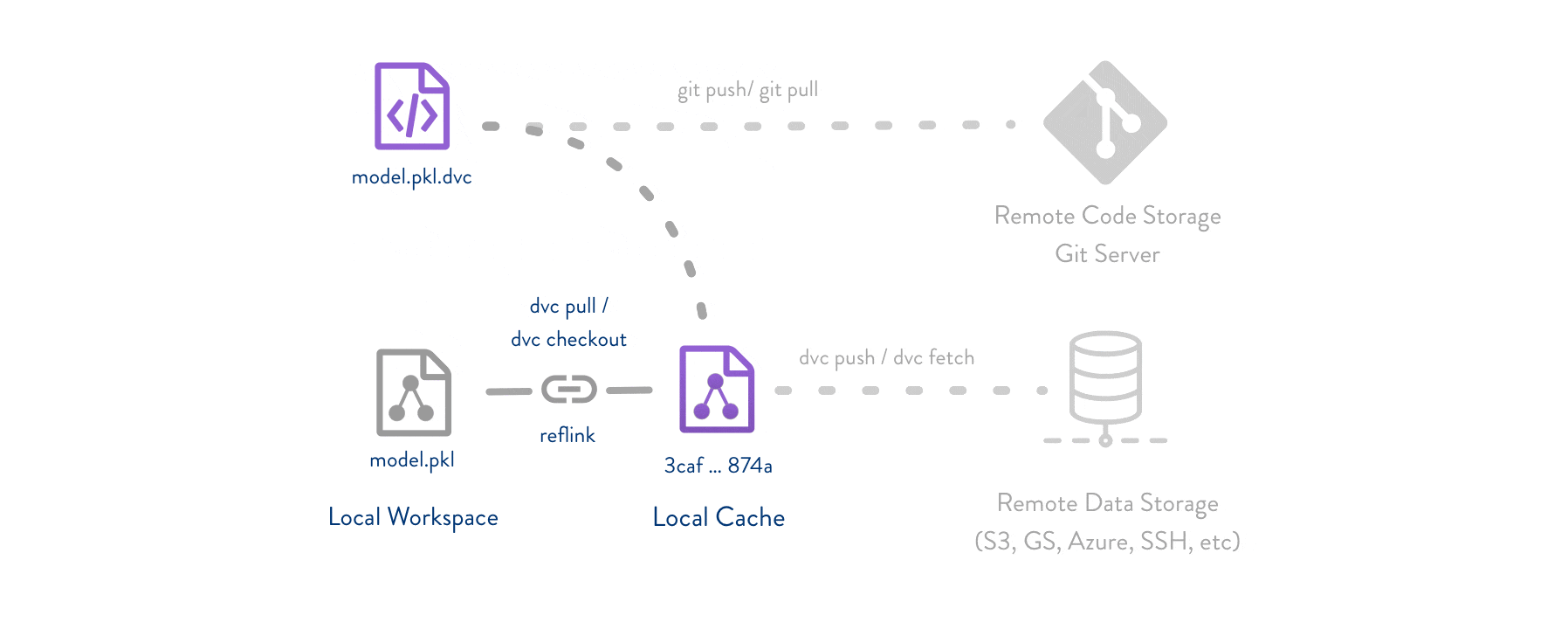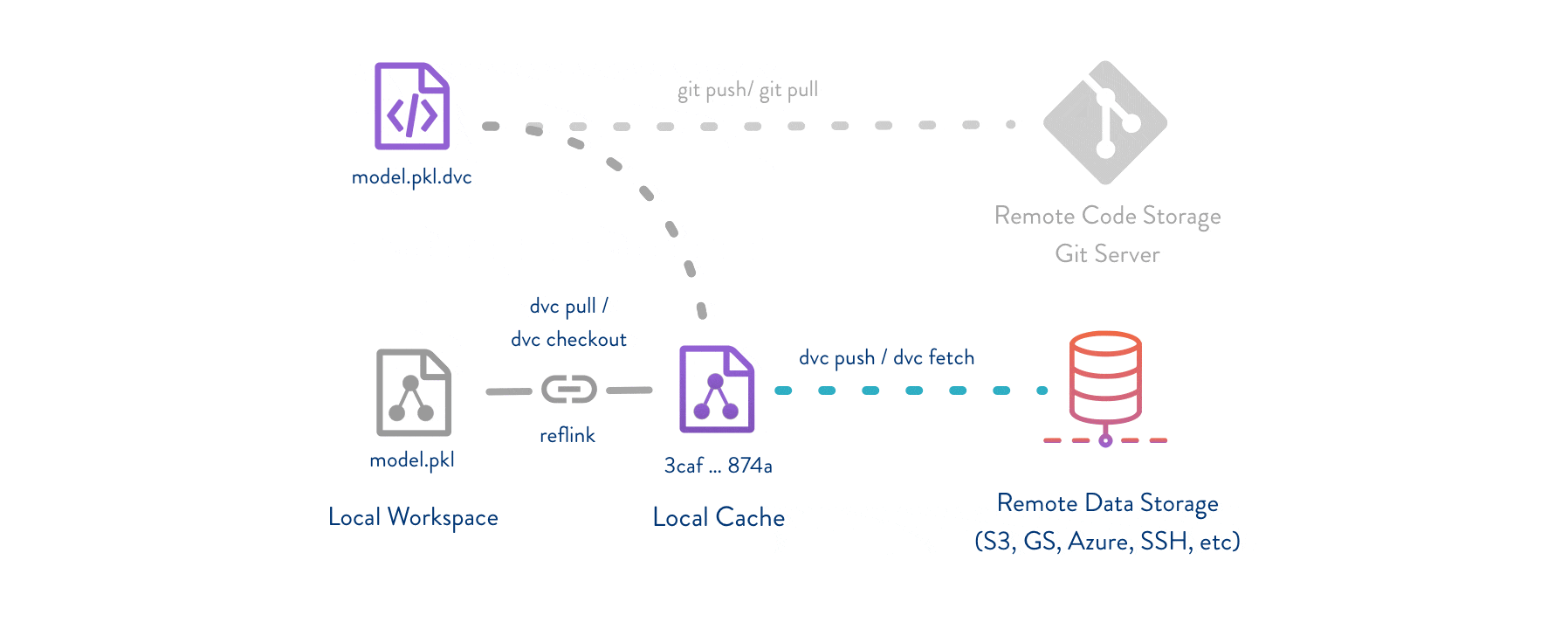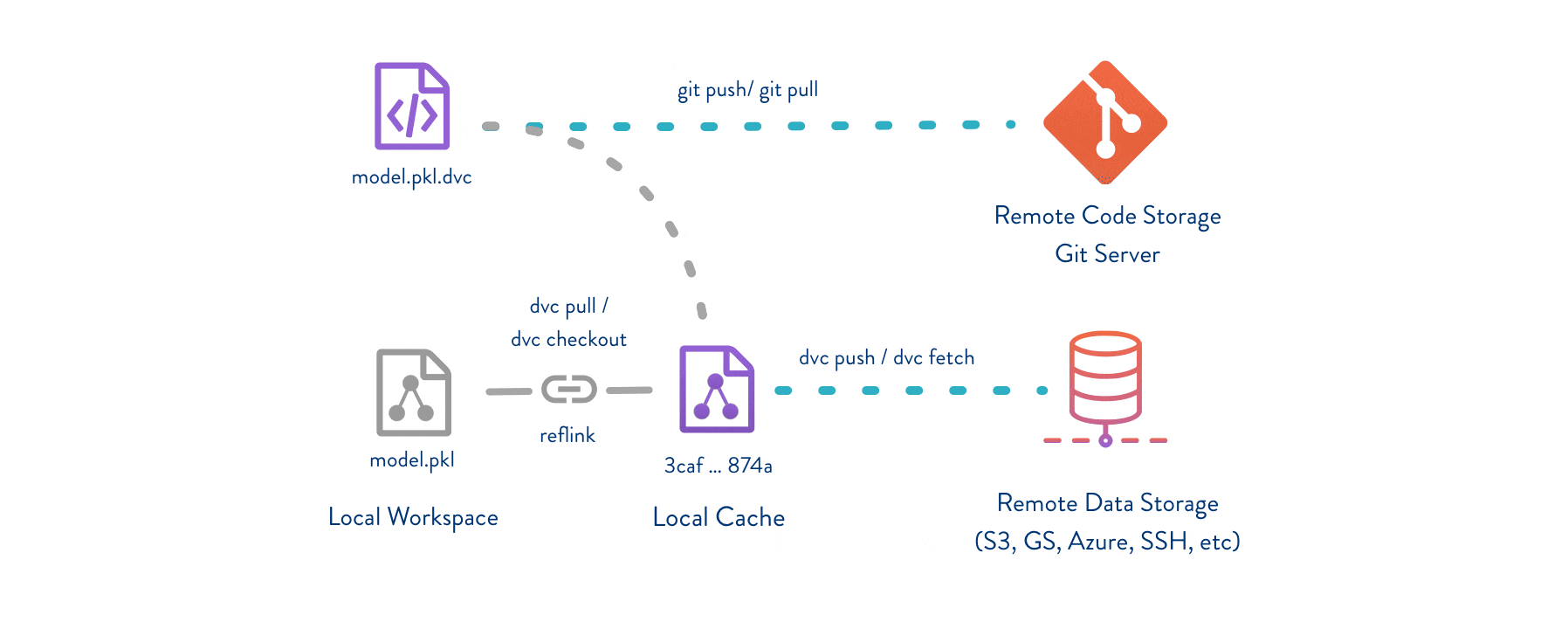
DVC pipelines (computational graphs) connect code and data together. They specify all steps required to produce a model: input dependencies including code, data, commands to run; and output information to be saved.
Last but not least, DVC Experiment Versioning lets you prepare and run a large number of experiments. Their results can be filtered and compared based on hyperparameters and metrics, and visualized with multiple plots.
To use DVC as a GUI right from your VS Code IDE, install the DVC Extension from the Marketplace. It currently features experiment tracking and data management, and more features (data pipeline support, etc.) are coming soon!
Note: You'll have to install core DVC on your system separately (as detailed below). The Extension will guide you if needed.
There are several ways to install DVC: in VS Code; using snap, choco, brew, conda, pip; or with an OS-specific package.
Full instructions are available here.
snap install dvc --classicThis corresponds to the latest tagged release.
Add --beta for the latest tagged release candidate, or --edge for the latest main version.
choco install dvcbrew install dvcconda install -c conda-forge mamba # installs much faster than conda
mamba install -c conda-forge dvcDepending on the remote storage type you plan to use to keep and share your data, you might need to install optional dependencies: dvc-s3, dvc-azure, dvc-gdrive, dvc-gs, dvc-oss, dvc-ssh.
pip install dvcDepending on the remote storage type you plan to use to keep and share your data, you might need to specify one of the optional dependencies: s3, gs, azure, oss, ssh. Or all to include them all.
The command should look like this: pip install 'dvc[s3]' (in this case AWS S3 dependencies such as boto3 will be installed automatically).
To install the development version, run:
pip install git+git://github.com/iterative/dvcSelf-contained packages for Linux, Windows, and Mac are available. The latest version of the packages can be found on the GitHub releases page.
sudo wget https://dvc.org/deb/dvc.list -O /etc/apt/sources.list.d/dvc.list
wget -qO - https://dvc.org/deb/iterative.asc | sudo apt-key add -
sudo apt update
sudo apt install dvcsudo wget https://dvc.org/rpm/dvc.repo -O /etc/yum.repos.d/dvc.repo
sudo rpm --import https://dvc.org/rpm/iterative.asc
sudo yum update
sudo yum install dvc
Contributions are welcome! Please see our Contributing Guide for more details. Thanks to all our contributors!
This project is distributed under the Apache license version 2.0 (see the LICENSE file in the project root).
By submitting a pull request to this project, you agree to license your contribution under the Apache license version 2.0 to this project.
Iterative, DVC: Data Version Control - Git for Data & Models (2020) DOI:10.5281/zenodo.012345.
Barrak, A., Eghan, E.E. and Adams, B. On the Co-evolution of ML Pipelines and Source Code - Empirical Study of DVC Projects , in Proceedings of the 28th IEEE International Conference on Software Analysis, Evolution, and Reengineering, SANER 2021. Hawaii, USA.