World Wide Web


World Wide Web, gọi tắt là WWW, mạng lưới toàn cầu là một không gian thông tin toàn cầu mà mọi người có thể truy cập (đọc và viết) thông tin qua các thiết bị kết nối với mạng Internet; một hệ thống thông tin trên Internet cho phép các tài liệu được kết nối với các tài liệu khác bằng các liên kết siêu văn bản, cho phép người dùng tìm kiếm thông tin bằng cách di chuyển từ tài liệu này sang tài liệu khác. Thuật ngữ này thường được hiểu nhầm là từ đồng nghĩa với chính thuật ngữ Internet. Nhưng Web thực ra chỉ là một trong các dịch vụ chạy trên Internet, ngoài Web ra còn các dịch vụ khác như thư điện tử hoặc FTP.
Nhà khoa học người Anh: Tim Berners-Lee được cho là đã phát minh ra World Wide Web khi làm việc cho CERN vào tháng 3 năm 1989 bằng cách gửi Quản lý thông tin: Đề xuất[1] và viết trình duyệt web đầu tiên vào năm 1990.[2][3] Trình duyệt được phát hành bên ngoài CERN năm 1991, lần đầu tiên cho các tổ chức nghiên cứu khác bắt đầu vào tháng 1 năm 1991 và công chúng trên Internet vào tháng 8 năm 1991. World Wide Web là trung tâm cho sự phát triển của Thời đại Thông tin và là công cụ chính mà hàng tỷ người sử dụng để tương tác trên Internet.[4][5][6]
Tài nguyên web có thể là bất kỳ loại phương tiện có thể tải xuống nào, nhưng các trang web là phương tiện siêu văn bản đã được định dạng bằng Ngôn ngữ đánh dấu siêu văn bản (HTML).[7] Định dạng như vậy cho phép các siêu liên kết nhúng có chứa URL và cho phép người dùng dễ dàng điều hướng đến các tài nguyên web khác. Ngoài văn bản, các trang web có thể chứa các thành phần hình ảnh, video, âm thanh và phần mềm được hiển thị trong trình duyệt web của người dùng dưới dạng các trang kết hợp nội dung đa phương tiện.
Nhiều tài nguyên web với một chủ đề chung, một tên miền chung hoặc cả hai, tạo nên một trang web. Trang web được lưu trữ trong các máy tính đang chạy chương trình gọi là máy chủ web đáp ứng các yêu cầu được thực hiện qua Internet từ các trình duyệt web chạy trên máy tính của người dùng. Nội dung trang web có thể được cung cấp phần lớn bởi nhà xuất bản hoặc tương tác nơi người dùng đóng góp nội dung. Các trang web cung cấp nội dung với vô số lý do như thông tin, giải trí, thương mại, chính phủ hoặc phi chính phủ,...
Lịch sử
[sửa | sửa mã nguồn]

Tầm nhìn của Tim Berners-Lee về một hệ thống thông tin siêu liên kết toàn cầu đã trở thành một khả năng thực tế vào nửa cuối thập niên 1980.[8] Đến năm 1985, Internet toàn cầu bắt đầu phổ biến ở châu Âu và Hệ thống tên miền (trên đó Bộ định vị tài nguyên thống nhất được xây dựng) ra đời. Năm 1988, kết nối IP trực tiếp đầu tiên giữa châu Âu và Bắc Mỹ đã được thực hiện và Berners-Lee bắt đầu thảo luận cởi mở về khả năng của một hệ thống giống như web tại CERN.[9]
Khi làm việc tại CERN, Berners-Lee đã trở nên thất vọng với sự thiếu hiệu quả và khó khăn do tìm kiếm thông tin được lưu trữ trên các máy tính khác nhau.[10] Vào ngày 12 tháng 3 năm 1989, ông đã gửi một bản ghi nhớ, có tiêu đề "Information Management: A Proposal",[11] cho ban quản lý tại CERN cho một hệ thống có tên "Lưới" tham chiếu ENQUIRE, một dự án cơ sở dữ liệu và phần mềm mà ông đã xây dựng vào năm 1980, trong đó sử dụng thuật ngữ "web" và mô tả một hệ thống quản lý thông tin phức tạp hơn dựa trên các liên kết được nhúng trong văn bản có thể đọc được: "Hãy tưởng tượng, sau đó, các tài liệu tham khảo trong tài liệu này đều được liên kết với địa chỉ mạng của thứ mà chúng đề cập, do đó trong khi đọc tài liệu này, bạn có thể chuyển tới chúng bằng một cú click chuột." Một hệ thống như vậy, ông giải thích, có thể được truy cập đến bằng cách sử dụng một trong những ý nghĩa hiện có của từ siêu văn bản, một thuật ngữ mà ông nói đã được đặt ra trong những năm 1950. Đề xuất tiếp tục giải thích tại sao các liên kết siêu văn bản như vậy không thể bao gồm các tài liệu đa phương tiện bao gồm đồ họa, lời nói và video, do đó Berners-Lee đưa ra việc sử dụng thuật ngữ hypermedia.[12]
Với sự giúp đỡ từ đồng nghiệp và người say mê siêu văn bản Robert Cailliau, ông đã xuất bản một đề xuất chính thức hơn vào ngày 12 tháng 11 năm 1990 để xây dựng một "dự án siêu văn bản" có tên là "WorldWideWeb" (một từ) dưới dạng "web" của "tài liệu siêu văn bản" để xem "Trình duyệt" sử dụng kiến trúc máy chủ của khách hàng.[13] Tại thời điểm này, HTML và HTTP đã được phát triển được khoảng hai tháng và máy chủ Web đầu tiên còn khoảng một tháng để hoàn thành thử nghiệm thành công đầu tiên. Đề xuất này ước tính rằng một trang web chỉ đọc sẽ được phát triển trong vòng ba tháng và phải mất sáu tháng để đạt được "việc tạo ra các liên kết mới và tài liệu mới của độc giả, [để] quyền tác giả trở nên phổ biến" cũng như "tự động thông báo cho độc giả khi có tài liệu mới mà anh ấy/cô ấy quan tâm". Trong khi mục tiêu là thông tin chỉ đọc được đáp ứng, quyền tác giả có thể truy cập của nội dung web mất nhiều thời gian hơn để hoàn thiện, với khái niệm wiki, WebDAV, blog, Web 2.0 và RSS/Atom.[14]

Đề xuất này được mô phỏng theo phần mềm đọc SGML Dynatext của Electronic Book Technology, một phần phụ của Viện Nghiên cứu Thông tin và Học bổng tại Đại học Brown. Hệ thống Dynatext, được CERN cấp phép, là nhân tố chính trong việc mở rộng SGML ISO 8879: 1986 cho Hypermedia trong HyTime, nhưng nó được coi là quá đắt và có chính sách cấp phép không phù hợp để sử dụng trong cộng đồng vật lý năng lượng cao nói chung, cụ thể là lệ phí cho mỗi tài liệu và từng lần cập nhật tài liệu. Máy tính NeXT đã được Berners-Lee sử dụng làm máy chủ web đầu tiên trên thế giới và cũng để viết trình duyệt web đầu tiên, WorldWideWeb vào năm 1990. Vào Giáng sinh năm 1990, Berners-Lee đã xây dựng tất cả các công cụ cần thiết cho một Web hoạt động:[15] trình duyệt web đầu tiên (cũng là trình chỉnh sửa web) và máy chủ web đầu tiên. Trang web đầu tiên,[16] mô tả chính dự án, được xuất bản vào ngày 20 tháng 12 năm 1990.[17]
Trang web đầu tiên có thể bị mất, nhưng Paul Jones của UNC-Chapel Hill ở Bắc Carolina đã thông báo vào tháng 5 năm 2013 rằng Berners-Lee đã đưa cho Jones những gì ông nói là trang web lâu đời nhất được biết đến trong chuyến thăm năm 1991 đến UNC. Jones đã lưu nó trên một ổ đĩa quang từ và trên máy tính NeXT của mình.[18] Vào ngày 6 tháng 8 năm 1991, Berners-Lee đã xuất bản một bản tóm tắt ngắn về dự án World Wide Web trên nhóm tin alt.hypertext.[19] Ngày này đôi khi bị nhầm lẫn với lần xuất hiện công khai của các máy chủ web đầu tiên đã xảy ra vài tháng trước đó. Một ví dụ khác về sự nhầm lẫn như vậy, một số phương tiện truyền thông đã báo cáo rằng bức ảnh đầu tiên trên Web được Berners-Lee công bố vào năm 1992, một hình ảnh của ban nhạc nhà Cern Les Horribles Cernettes được chụp bởi Silvano de Gennaro; Gennaro đã từ chối câu chuyện này, viết rằng phương tiện truyền thông đã "hoàn toàn bóp méo lời nói của chúng tôi vì lợi ích của chủ nghĩa giật gân rẻ tiền".[20]
Các máy chủ đầu tiên bên ngoài châu Âu được lắp đặt tại Trung tâm Stanford Linear Accelerator (SLAC) ở Palo Alto, California, để lưu trữ các cơ sở dữ liệu Spires -HEP. Các nguồn khi nói đến ngày của sự kiện này có khác nhau đáng kể. Thời gian biểu của World Wide Web Consortium cho biết tháng 12 năm 1992,[21] trong khi chính SLAC tuyên bố tháng 12 năm 1991,[22][23] cũng như một tài liệu của W3C có tiêu đề A Little History of the World Wide Web.[24] Khái niệm cơ bản của siêu văn bản bắt nguồn từ các dự án trước đó từ những năm 1960, như Hệ thống chỉnh sửa siêu văn bản (HES) tại Đại học Brown, Dự án Xanadu của Ted Nelson và Hệ thống oN-Line (NLS) của Douglas Engelbart. Cả Nelson và Engelbart đã lần lượt lấy cảm hứng từ bản sao Bản ghi nhớ của Vannevar Bush, được mô tả trong luận văn năm 1945 'Như chúng ta có thể suy nghĩ'.
Bước đột phá của Berners-Lee là kết hôn với siêu văn bản trên Internet. Trong cuốn sách Weaving The Web, ông giải thích rằng ông đã nhiều lần đề xuất rằng một cuộc hôn nhân giữa hai công nghệ là có thể với các thành viên của cả hai cộng đồng kỹ thuật, nhưng khi không có ai nhận lời mời, cuối cùng ông đã tự nhận dự án. Trong quá trình đó, ông đã phát triển ba công nghệ thiết yếu:
- Một hệ thống các mã định danh duy nhất trên toàn cầu cho các tài nguyên trên Web và các nơi khác, định danh tài liệu chung (UDI), sau này được gọi là định vị tài nguyên thống nhất (URL) và định danh tài nguyên thống nhất (URI);
- Ngôn ngữ xuất bản HyperText Markup Language (HTML);
- Giao thức truyền siêu văn bản (HTTP).[25]
World Wide Web có một số khác biệt so với các hệ thống siêu văn bản khác có sẵn tại thời điểm đó. Web chỉ yêu cầu các liên kết đơn hướng chứ không phải liên kết hai chiều, khiến ai đó có thể liên kết đến tài nguyên khác mà không cần hành động của chủ sở hữu tài nguyên đó. Nó cũng làm giảm đáng kể khó khăn trong việc triển khai các máy chủ và trình duyệt web (so với các hệ thống trước đó), nhưng đến lượt nó lại đưa ra vấn đề kinh niên về liên kết hỏng. Không giống như các phiên bản tiền nhiệm như HyperCard, World Wide Web không độc quyền, cho phép phát triển máy chủ và máy khách một cách độc lập và thêm tiện ích mở rộng mà không bị hạn chế cấp phép. Vào ngày 30 tháng 4 năm 1993, Cern tuyên bố rằng World Wide Web sẽ là miễn phí cho mọi người.[26] Đến hai tháng sau khi thông báo rằng việc máy chủ thực hiện giao thức Gopher không còn miễn phí sử dụng, điều này đã tạo ra một sự thay đổi nhanh chóng từ bỏ Gopher và hướng tới Web. Một trình duyệt web phổ biến ban đầu là ViolaWWW cho Unix và X Window System.

Các học giả thường đồng ý rằng một bước ngoặt của World Wide Web đã bắt đầu bằng việc giới thiệu[27] trình duyệt web Mosaic[28] vào năm 1993, một trình duyệt đồ họa được phát triển bởi một nhóm tại Trung tâm Ứng dụng siêu máy tính tại Đại học Illinois tại Urbana mật Champaign (NCSA-UIUC), do Marc Andreessen lãnh đạo. Tài trợ cho Mosaic đến từ Sáng kiến Điện toán và Truyền thông hiệu suất cao của Hoa Kỳ và Đạo luật tính toán hiệu năng cao năm 1991, một trong một số phát triển điện toán do Thượng nghị sĩ Hoa Kỳ Al Gore khởi xướng.[29] Trước khi phát hành Mosaic, đồ họa thường không được trộn với văn bản trong trang web và phổ biến của web là ít hơn so với các giao thức cũ được sử dụng trên Internet, chẳng hạn như Gopher và Wide Area Information Servers (WAIS). Giao diện người dùng đồ họa của Mosaic cho phép Web trở thành giao thức Internet phổ biến nhất. World Wide Web Consortium (W3C) được Tim Berners-Lee thành lập sau khi ông rời Tổ chức nghiên cứu hạt nhân châu Âu (CERN) vào tháng 10 năm 1994. W3C được thành lập tại Viện Công nghệ Massachusetts Phòng thí nghiệm Khoa học máy tính (MIT / LCS) với sự hỗ trợ từ các dự án nghiên cứu nâng cao Cơ quan Quốc phòng (DARPA), vốn đã đi tiên phong trong Internet; một năm sau, một trang web thứ hai được thành lập tại INRIA (một phòng thí nghiệm nghiên cứu máy tính quốc gia của Pháp) với sự hỗ trợ của Ủy ban Châu Âu DG InfSo; và vào năm 1996, một trang web thứ ba đã được tạo ra tại Nhật Bản tại Đại học Keio. Đến cuối năm 1994, tổng số trang web vẫn còn tương đối ít, nhưng nhiều trang web đáng chú ý đã đi vào hoạt động, báo trước hoặc truyền cảm hứng cho các dịch vụ phổ biến nhất hiện nay.
Được kết nối bởi Internet, các trang web khác đã được tạo ra trên khắp thế giới. Điều này thúc đẩy phát triển tiêu chuẩn quốc tế cho các giao thức và định dạng. Berners-Lee tiếp tục tham gia vào việc hướng dẫn phát triển các tiêu chuẩn web, chẳng hạn như các ngôn ngữ đánh dấu để soạn các trang web và ông ủng hộ tầm nhìn của mình về Semantic Web. World Wide Web cho phép truyền bá thông tin qua Internet thông qua định dạng linh hoạt và dễ sử dụng. Do đó, nó đóng một vai trò quan trọng trong việc phổ biến sử dụng Internet.[30] Mặc dù hai thuật ngữ này đôi khi dùng lẫn nhau do được sử dụng phổ biến, World Wide Web là không đồng nghĩa với Internet.[31] Web là một không gian thông tin chứa các tài liệu siêu liên kết và các tài nguyên khác, được xác định bởi các URI của chúng.[32] Nó được triển khai như cả phần mềm máy khách và máy chủ sử dụng các giao thức Internet như TCP / IP và HTTP. Berners-Lee được Nữ hoàng Elizabeth II phong tước hiệp sĩ năm 2004 vì "các dịch vụ cho sự phát triển toàn cầu của Internet".[33][34] Ông không bao giờ xin cấp bằng sáng chế cho phát minh của mình.
Chức năng
[sửa | sửa mã nguồn]
Các thuật ngữ Internet và World Wide Web thường được sử dụng mà không có nhiều sự khác biệt. Tuy nhiên, hai thuật ngữ không có nghĩa giống nhau. Internet là một hệ thống toàn cầu của các mạng máy tính được kết nối với nhau. Ngược lại, World Wide Web là một tập hợp toàn cầu các tài liệu và các tài nguyên khác, được liên kết bởi các siêu liên kết và URI. Tài nguyên web được truy cập bằng HTTP hoặc HTTPS, là các giao thức Internet cấp ứng dụng sử dụng các giao thức truyền tải của Internet.[35]
Việc xem một trang web trên World Wide Web thường bắt đầu bằng cách nhập URL của trang vào trình duyệt web hoặc bằng cách theo một siêu liên kết đến trang hoặc tài nguyên đó. Trình duyệt web sau đó khởi tạo một loạt các thông báo truyền thông nền để tìm nạp và hiển thị trang được yêu cầu. Vào những năm 1990, sử dụng trình duyệt để xem các trang web, và chuyển từ trang này sang trang khác thông qua các siêu liên kết, được biết đến như là 'duyệt web,' 'lướt web' (sau khi lướt kênh) hoặc 'điều hướng Web'. Những nghiên cứu ban đầu về hành vi mới này đã điều tra các mẫu người dùng trong việc sử dụng trình duyệt web. Một nghiên cứu, ví dụ, đã tìm thấy năm mẫu người dùng: lướt web khám phá, lướt web cửa sổ, lướt phát triển, điều hướng giới hạn và điều hướng mục tiêu.[36]
Ví dụ sau đây cho thấy chức năng của trình duyệt web khi truy cập một trang tại URL http://www.example.org/home.html. Trình duyệt phân giải tên máy chủ của URL (www.example.org) thành địa chỉ Giao thức Internet bằng Hệ thống tên miền (DNS) được phân phối toàn cầu. Tra cứu này trả về một địa chỉ IP như 203.0.113.4 hoặc 2001: db8: 2e:: 7334. Trình duyệt sau đó yêu cầu tài nguyên bằng cách gửi yêu cầu HTTP qua Internet đến máy tính tại địa chỉ đó. Nó yêu cầu dịch vụ từ một số cổng TCP cụ thể nổi tiếng với dịch vụ HTTP, để máy chủ nhận có thể phân biệt yêu cầu HTTP với các giao thức mạng khác mà nó có thể đang phục vụ. Giao thức HTTP thường sử dụng số cổng 80 và đối với giao thức HTTPS, thông thường nó là số cổng 443. Nội dung của yêu cầu HTTP có thể đơn giản như hai dòng văn bản:
GET /home.html HTTP/1.1
Host: www.example.org
Máy tính nhận yêu cầu HTTP chuyển nó đến phần mềm máy chủ web lắng nghe yêu cầu trên cổng 80. Nếu máy chủ web có thể thực hiện yêu cầu, nó sẽ gửi phản hồi HTTP trở lại trình duyệt cho thấy thành công:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
tiếp theo là nội dung của trang được yêu cầu. Ngôn ngữ đánh dấu siêu văn bản (HTML) cho một trang web cơ bản có thể trông như thế này:
<html>
<head>
<title>www.Example.org – The World Wide Web</title>
</head>
<body>
<p>The World Wide Web, abbreviated as WWW and commonly known...</p>
<u> WWW
</u>
</body>
</html>
Trình duyệt web phân tích cú pháp HTML và diễn giải đánh dấu (<title>, <p> cho đoạn văn,v.v...) bao quanh các từ để định dạng văn bản trên màn hình. Nhiều trang web sử dụng HTML để tham chiếu các URL của các tài nguyên khác như hình ảnh, phương tiện được nhúng khác, tập lệnh ảnh hưởng đến hành vi của trang và Biểu định kiểu xếp chồng ảnh hưởng đến bố cục trang. Trình duyệt thực hiện các yêu cầu HTTP bổ sung cho máy chủ web cho các loại phương tiện Internet khác. Khi nhận được nội dung của họ từ máy chủ web, trình duyệt sẽ dần dần hiển thị trang lên màn hình theo quy định của HTML và các tài nguyên bổ sung này.
HTML
[sửa | sửa mã nguồn]Ngôn ngữ đánh dấu siêu văn bản (HTML) là ngôn ngữ đánh dấu tiêu chuẩn để tạo các trang web và ứng dụng web. Với Cascading Style Sheets (CSS) và JavaScript, nó tạo thành một bộ ba công nghệ nền tảng cho World Wide Web.[37]
Trình duyệt web nhận tài liệu HTML từ máy chủ web hoặc từ bộ nhớ cục bộ và hiển thị tài liệu vào các trang web đa phương tiện. HTML mô tả cấu trúc của một trang web về mặt ngữ nghĩa và ban đầu bao gồm các tín hiệu cho sự xuất hiện của tài liệu.
Các phần tử HTML là các khối xây dựng của các trang HTML. Với cấu trúc HTML, hình ảnh và các đối tượng khác như biểu mẫu tương tác có thể được nhúng vào trang được hiển thị. HTML cung cấp một phương tiện để tạo các tài liệu có cấu trúc bằng cách biểu thị ngữ nghĩa cấu trúc cho văn bản như tiêu đề, đoạn văn, danh sách, liên kết, trích dẫn và các mục khác. Các phần tử HTML được mô tả bằng các thẻ, được viết bằng dấu ngoặc nhọn. Các thẻ như <img /> và <input /> trực tiếp giới thiệu nội dung vào trang. Các thẻ khác, chẳng hạn như <p> bao quanh và cung cấp thông tin về văn bản tài liệu và có thể bao gồm các thẻ khác làm thành phần phụ. Các trình duyệt không hiển thị các thẻ HTML, nhưng sử dụng chúng để diễn giải nội dung của trang.
HTML có thể nhúng các chương trình được viết bằng ngôn ngữ script như JavaScript, ảnh hưởng đến hành vi và nội dung của các trang web. Bao gồm CSS xác định giao diện và bố cục nội dung. World Wide Web Consortium (W3C), người duy trì cả hai tiêu chuẩn HTML và CSS, đã khuyến khích sử dụng CSS trên HTML trình bày rõ ràng.Tính đến năm 1997[cập nhật][38]
Liên kết
[sửa | sửa mã nguồn]Hầu hết các trang web chứa siêu liên kết đến các trang liên quan khác và có lẽ các tệp có thể tải xuống, tài liệu nguồn, định nghĩa và các tài nguyên web khác. Trong HTML cơ bản, một siêu liên kết trông như thế này:
<a href="http://www.example.org/home.html">www.Example.org Homepage</a>
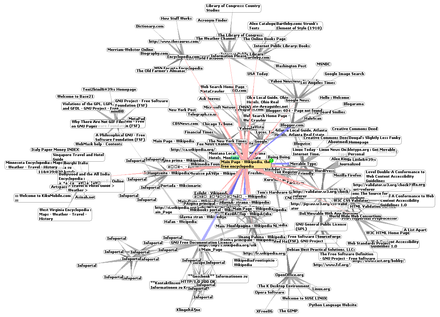
Một tập hợp các tài nguyên hữu ích, có liên quan, được kết nối với nhau thông qua các liên kết siêu văn bản được mệnh danh là một mạng lưới thông tin. Xuất bản trên Internet tạo ra thứ mà Tim Berners-Lee gọi là WorldWideWeb (trong CamelCase ban đầu, sau đó đã bị loại bỏ) vào tháng 11 năm 1990.[13]
Cấu trúc siêu liên kết của WWW được mô tả bởi webgraph: các nút của biểu đồ web tương ứng với các trang web (hoặc URL) các cạnh được định hướng giữa chúng với các siêu liên kết. Theo thời gian, nhiều tài nguyên web được chỉ ra bởi các siêu liên kết biến mất, di dời hoặc được thay thế bằng các nội dung khác nhau. Điều này làm cho các siêu liên kết trở nên lỗi thời, một hiện tượng được gọi trong một số vòng tròn là thối liên kết và các siêu liên kết bị ảnh hưởng bởi nó thường được gọi là liên kết chết. Bản chất bất ổn của Web đã thúc đẩy nhiều nỗ lực lưu trữ các trang web. Internet Archive, hoạt động từ năm 1996, được biết đến nhiều nhất với những nỗ lực như vậy.
Tiền tố WWW
[sửa | sửa mã nguồn]Nhiều tên máy chủ được sử dụng cho World Wide Web bắt đầu bằng www vì thông lệ đặt tên máy chủ Internet lâu dài theo các dịch vụ mà chúng cung cấp. Tên máy chủ của máy chủ web thường là www, giống như cách mà nó có thể là ftp cho máy chủ FTP và tin tức hoặc nntp cho máy chủ tin tức Usenet. Các tên máy chủ này xuất hiện dưới dạng Hệ thống tên miền (DNS) hoặc tên miền phụ, như trong www.example.com. Việc sử dụng www không được yêu cầu bởi bất kỳ tiêu chuẩn kỹ thuật hoặc chính sách nào và nhiều trang web không sử dụng nó; máy chủ web đầu tiên là nxoc01.cern.ch.[39] Theo Paolo Palazzi,[40] người từng làm việc tại CERN cùng với Tim Berners-Lee, việc sử dụng phổ biến www làm tên miền phụ là tình cờ; trang dự án World Wide Web dự định được xuất bản tại www.cern.ch trong khi info.cern.ch được dự định là trang chủ của Cern, tuy nhiên các bản ghi DNS không bao giờ được chuyển đổi và việc thực hành trả trước www vào trang web của tổ chức tên miền sau đó đã được sao chép. Nhiều trang web được thiết lập vẫn sử dụng tiền tố hoặc họ sử dụng các tên miền phụ khác như www2, an toàn hoặc en cho các mục đích đặc biệt. Nhiều máy chủ web như vậy được thiết lập sao cho cả tên miền chính (ví dụ: example.com) và tên miền phụ www (ví dụ: www.example.com) đề cập đến cùng một trang web; những người khác yêu cầu một hình thức này hoặc hình thức khác, hoặc họ có thể ánh xạ đến các trang web khác nhau. Việc sử dụng tên miền phụ rất hữu ích để tải cân bằng lưu lượng truy cập web đến bằng cách tạo bản ghi CNAME trỏ đến một cụm máy chủ web. Vì hiện tại, chỉ có một tên miền phụ có thể được sử dụng trong CNAME, kết quả tương tự không thể đạt được bằng cách sử dụng mở tên miền gốc.[41]
Khi người dùng gửi một tên miền chưa hoàn chỉnh cho trình duyệt web trong nhập thanh địa chỉ đầu vào của nó, một số trình duyệt web sẽ tự động thử thêm tiền tố "www" vào đầu của nó và có thể là ".com", ".org" và ".net "Ở cuối, tùy thuộc vào những gì có thể thiếu. Ví dụ: nhập ' microsoft ' có thể được chuyển đổi thành http://www.microsoft.com/ và 'openoffice' thành http://www.openoffice.org. Tính năng này bắt đầu xuất hiện trong các phiên bản đầu tiên của Firefox, khi nó vẫn có tiêu đề hoạt động 'Firebird' vào đầu năm 2003, từ một thực tiễn trước đó trong các trình duyệt như Lynx.[42] ] Có thông tin rằng Microsoft đã được cấp bằng sáng chế của Hoa Kỳ cho ý tưởng tương tự vào năm 2008, nhưng chỉ dành cho thiết bị di động.[43]
Trong tiếng Anh, www thường được đọc là double-u double-u double-u.[44] Một số người dùng phát âm nó dub-dub-dub, đặc biệt là ở New Zealand. Stephen Fry, trong loạt podcast "Podgrams" của mình, phát âm nó là wuh wuh wuh.[45] Nhà văn người Anh Douglas Adams đã từng châm biếm trong tờ Độc lập vào Chủ nhật (1999): "World Wide Web là điều duy nhất tôi biết về hình thức rút gọn của nó mất nhiều thời gian hơn ba lần để nói ngắn hơn"[46] Trong tiếng Quan Thoại, World Wide Web thường được dịch qua liên kết ngữ nghĩa thành Wan wǎng Wei (万维网), thỏa mãn www và nghĩa đen là "mạng vô số chiều",[47] một bản dịch phản ánh khái niệm thiết kế và phổ biến của World Wide Web. Không gian web của Tim Berners-Lee tuyên bố rằng World Wide Web được chính thức đánh vần là ba từ riêng biệt, mỗi từ viết hoa, không có dấu gạch ngang.[48] Việc sử dụng tiền tố www đã giảm dần, đặc biệt là khi các ứng dụng web Web 2.0 tìm cách tạo thương hiệu cho tên miền của chúng và làm cho chúng dễ phát âm.[49] Khi Web di động ngày càng phổ biến, các dịch vụ như Gmail.com, Outlook.com, Myspace.com, Facebook.com và Twitter.com thường được đề cập nhất mà không cần thêm "www." (hoặc, thực sự, ".com") cho tên miền.
Sơ đồ mô tả
[sửa | sửa mã nguồn]Các chỉ định lược đồ http:// và https:// khi bắt đầu URI web tương ứng với Giao thức truyền siêu văn bản hoặc Bảo mật HTTP. Họ chỉ định giao thức truyền thông để sử dụng cho yêu cầu và phản hồi. Giao thức HTTP là nền tảng cho hoạt động của World Wide Web và lớp mã hóa được thêm vào trong HTTPS là điều cần thiết khi trình duyệt gửi hoặc truy xuất dữ liệu bí mật, như mật khẩu hoặc thông tin ngân hàng. Các trình duyệt web thường tự động thêm http: // vào các URI do người dùng nhập, nếu bị bỏ qua.
Trang web
[sửa | sửa mã nguồn]
Một trang web (cũng được viết dưới dạng trang web) là một tài liệu phù hợp với World Wide Web và các trình duyệt web. Trình duyệt web hiển thị một trang web trên màn hình hoặc thiết bị di động.
Thuật ngữ trang web thường đề cập đến những gì có thể nhìn thấy, nhưng cũng có thể đề cập đến nội dung của chính tệp máy tính, thường là tệp văn bản chứa siêu văn bản được viết bằng HTML hoặc ngôn ngữ đánh dấu so sánh. Các trang web điển hình cung cấp siêu văn bản để duyệt đến các trang web khác thông qua các siêu liên kết, thường được gọi là các liên kết. Các trình duyệt web sẽ thường xuyên phải truy cập nhiều yếu tố tài nguyên web, chẳng hạn như đọc biểu định kiểu, tập lệnh và hình ảnh, trong khi trình bày từng trang web.
Trên mạng, trình duyệt web có thể truy xuất trang web từ máy chủ web từ xa. Máy chủ web có thể hạn chế quyền truy cập vào một mạng riêng như mạng nội bộ của công ty. Trình duyệt web sử dụng Giao thức truyền siêu văn bản (HTTP) để thực hiện các yêu cầu như vậy đến máy chủ web.
Một trang web tĩnh được phân phối chính xác như được lưu trữ, như nội dung web trong hệ thống tệp của máy chủ web. Ngược lại, một trang web động được tạo bởi một ứng dụng web, thường được điều khiển bởi phần mềm phía máy chủ. Các trang web động giúp trình duyệt (máy khách) cải thiện trang web thông qua đầu vào của người dùng đến máy chủ.
Trang web tĩnh
[sửa | sửa mã nguồn]Trang web tĩnh (đôi khi được gọi là trang phẳng/trang cố định) là trang web được phân phối cho người dùng chính xác như được lưu trữ, trái ngược với các trang web động được tạo bởi ứng dụng web.
Do đó, một trang web tĩnh hiển thị cùng một thông tin cho tất cả người dùng, từ mọi bối cảnh, tùy thuộc vào khả năng hiện đại của máy chủ web để đàm phán loại nội dung hoặc ngôn ngữ của tài liệu có sẵn các phiên bản đó và máy chủ được cấu hình để làm như vậy.
Trang web động
[sửa | sửa mã nguồn]
Trang web động phía máy chủ là trang web có cấu trúc được điều khiển bởi máy chủ ứng dụng xử lý các tập lệnh phía máy chủ. Trong kịch bản phía máy chủ, các tham số xác định cách tiến hành lắp ráp mỗi trang web mới, bao gồm cả việc thiết lập xử lý phía máy khách nhiều hơn.
Một trang web động phía máy khách xử lý trang web bằng cách sử dụng tập lệnh HTML chạy trong trình duyệt khi tải. JavaScript và các ngôn ngữ kịch bản lệnh khác xác định cách HTML trong trang nhận được được phân tích cú pháp vào Mô hình đối tượng tài liệu hoặc DOM, đại diện cho trang web được tải. Các kỹ thuật phía máy khách tương tự sau đó có thể tự động cập nhật hoặc thay đổi DOM theo cùng một cách.
Sau đó, một trang web động được tải lại bởi người dùng hoặc bởi một chương trình máy tính để thay đổi một số nội dung biến. Thông tin cập nhật có thể đến từ máy chủ hoặc từ các thay đổi được thực hiện cho DOM của trang đó. Điều này có thể hoặc không thể cắt bớt lịch sử duyệt web hoặc tạo một phiên bản đã lưu để quay lại, nhưng một bản cập nhật trang web động bằng công nghệ Ajax sẽ không tạo ra một trang để quay lại, cũng không cắt bớt lịch sử duyệt web về phía trước của trang được hiển thị. Sử dụng các công nghệ Ajax, người dùng cuối sẽ có một trang động được quản lý dưới dạng một trang trong trình duyệt web trong khi nội dung web thực tế được hiển thị trên trang đó có thể khác nhau. Máy Ajax định vị trên trình duyệt yêu cầu các bộ phận DOM của nó, DOM, cho khách hàng của mình từ một máy chủ ứng dụng.
DHTML là thuật ngữ chung cho các công nghệ và phương pháp được sử dụng để tạo các trang web không phải là trang web tĩnh, mặc dù nó đã không được sử dụng phổ biến kể từ khi phổ biến AJAX, một thuật ngữ mà hiện nay nó hiếm khi được sử dụng. Kịch bản phía máy khách, kịch bản phía máy chủ hoặc kết hợp những thứ này tạo nên trải nghiệm web động trong trình duyệt.
JavaScript là ngôn ngữ kịch bản được phát triển lần đầu tiên vào năm 1995 bởi Brendan Eich, sau đó là Netscape, để sử dụng trong các trang web.[50] Phiên bản tiêu chuẩn là ECMAScript.[50] Để làm cho các trang web tương tác nhiều hơn, một số ứng dụng web cũng sử dụng các kỹ thuật JavaScript như Ajax (JavaScript không đồng bộ và XML). Tập lệnh phía máy khách được phân phối cùng với trang có thể thực hiện các yêu cầu HTTP bổ sung cho máy chủ, để đáp ứng với các hành động của người dùng như di chuyển chuột hoặc nhấp chuột hoặc dựa trên thời gian đã trôi qua. Phản hồi của máy chủ được sử dụng để sửa đổi trang hiện tại thay vì tạo một trang mới với mỗi phản hồi, do đó máy chủ chỉ cần cung cấp thông tin gia tăng, giới hạn. Nhiều yêu cầu Ajax có thể được xử lý cùng một lúc và người dùng có thể tương tác với trang trong khi dữ liệu được truy xuất. Các trang web cũng có thể thường xuyên thăm dò máy chủ để kiểm tra xem thông tin mới có sẵn hay không.[51]
Trang web
[sửa | sửa mã nguồn]
Trang web [52] là tập hợp các tài nguyên web liên quan bao gồm các trang web, nội dung đa phương tiện, thường được xác định bằng một tên miền chung và được xuất bản trên ít nhất một máy chủ web. Ví dụ đáng chú ý là wikipedia.org, google.com và amazon.com.
Một trang web có thể được truy cập thông qua mạng Giao thức Internet (IP) công cộng, chẳng hạn như Internet hoặc mạng cục bộ riêng (LAN), bằng cách tham chiếu một trình định vị tài nguyên thống nhất (URL) xác định trang web.
Trang web có thể có nhiều chức năng và có thể được sử dụng trong nhiều thời trang khác nhau; một trang web có thể là một trang web cá nhân, một trang web công ty cho một công ty, một trang web của chính phủ, một trang web của tổ chức,v.v... Các trang web thường dành riêng cho một chủ đề hoặc mục đích cụ thể, từ giải trí và mạng xã hội đến cung cấp tin tức và giáo dục. Tất cả các trang web có thể truy cập công khai cùng nhau tạo thành World Wide Web, trong khi các trang web riêng, chẳng hạn như trang web của công ty dành cho nhân viên, thường là một phần của mạng nội bộ.
Các trang web, là các khối xây dựng của trang web, là các tài liệu, thường được soạn thảo bằng văn bản thuần túy xen kẽ với các hướng dẫn định dạng của Ngôn ngữ đánh dấu siêu văn bản (HTML, XHTML). Họ có thể kết hợp các yếu tố từ các trang web khác với các neo đánh dấu phù hợp. Các trang web được truy cập và vận chuyển với Giao thức truyền siêu văn bản (HTTP), có thể tùy chọn sử dụng mã hóa (HTTP Secure, HTTPS) để cung cấp bảo mật và quyền riêng tư cho người dùng. Ứng dụng của người dùng, thường là trình duyệt web, hiển thị nội dung trang theo hướng dẫn đánh dấu HTML của nó lên thiết bị đầu cuối hiển thị.
Siêu liên kết giữa các trang web chuyển đến người đọc cấu trúc trang web và hướng dẫn điều hướng của trang web, thường bắt đầu bằng một trang chủ chứa một thư mục của nội dung trang web. Một số trang web yêu cầu đăng ký người dùng hoặc đăng ký để truy cập nội dung. Ví dụ về các trang web đăng ký bao gồm nhiều trang web kinh doanh, trang web tin tức, trang web tạp chí học thuật, trang web trò chơi, trang web chia sẻ tệp, bảng tin, email dựa trên web, trang web mạng xã hội, trang web cung cấp dữ liệu thị trường chứng khoán theo thời gian thực, cũng như các trang web cung cấp dịch vụ khác nhau. Người dùng cuối có thể truy cập các trang web trên một loạt thiết bị, bao gồm máy tính để bàn và máy tính xách tay, máy tính bảng, điện thoại thông minh và TV thông minh.
Trình duyệt web
[sửa | sửa mã nguồn]Trình duyệt web (thường được gọi là trình duyệt) là tác nhân người dùng phần mềm để truy cập thông tin trên World Wide Web. Để kết nối với máy chủ của trang web và hiển thị các trang của nó, người dùng cần phải có chương trình trình duyệt web. Đây là chương trình mà người dùng chạy để tải xuống, định dạng và hiển thị một trang web trên máy tính của người dùng.[53]
Ngoài việc cho phép người dùng tìm, hiển thị và di chuyển giữa các trang web, trình duyệt web thường sẽ có các tính năng như giữ dấu trang, ghi lịch sử, quản lý cookie (xem bên dưới) và trang chủ và có thể có phương tiện để ghi lại mật khẩu để đăng nhập vào trang web.
Các trình duyệt phổ biến nhất là Chrome, Firefox, Safari, Internet Explorer và Edge.
Máy chủ web
[sửa | sửa mã nguồn]
Máy chủ Web là phần mềm máy chủ hoặc phần cứng dành riêng để chạy phần mềm nói trên, có thể đáp ứng các yêu cầu máy khách World Wide Web. Nói chung, một máy chủ web có thể chứa một hoặc nhiều trang web. Một máy chủ web xử lý các yêu cầu mạng đến qua HTTP và một số giao thức liên quan khác.[54]
Chức năng chính của máy chủ web là lưu trữ, xử lý và phân phối các trang web cho người truy cập.[55] Giao tiếp giữa máy khách và máy chủ diễn ra bằng Giao thức truyền siêu văn bản (HTTP). Các trang được phân phối thường xuyên nhất là các tài liệu HTML, có thể bao gồm hình ảnh, biểu định kiểu và tập lệnh ngoài nội dung văn bản.

Tác nhân người dùng, thường là trình duyệt web hoặc trình thu thập dữ liệu web, bắt đầu giao tiếp bằng cách yêu cầu một tài nguyên cụ thể bằng HTTP và máy chủ phản hồi với nội dung của tài nguyên đó hoặc thông báo lỗi nếu không thể thực hiện được. Tài nguyên thường là một tệp thực trên bộ lưu trữ thứ cấp của máy chủ, nhưng điều này không nhất thiết phải như vậy và phụ thuộc vào cách máy chủ web được triển khai.
Mặc dù chức năng chính là phục vụ nội dung, nhưng việc triển khai HTTP đầy đủ cũng bao gồm các cách nhận nội dung từ khách hàng. Tính năng này được sử dụng để gửi biểu mẫu web, bao gồm việc tải lên tập tin.
Nhiều máy chủ web chung cũng hỗ trợ tập lệnh phía máy chủ bằng Active Server Pages (ASP), PHP (Bộ xử lý siêu văn bản) hoặc các ngôn ngữ tập lệnh khác. Điều này có nghĩa là hành vi của máy chủ web có thể được viết thành kịch bản trong các tệp riêng biệt, trong khi phần mềm máy chủ thực tế vẫn không thay đổi. Thông thường, chức năng này được sử dụng để tạo các tài liệu HTML một cách linh hoạt ("đang hoạt động") thay vì trả lại các tài liệu tĩnh. Cái trước chủ yếu được sử dụng để lấy hoặc sửa đổi thông tin từ cơ sở dữ liệu. Cái sau thường nhanh hơn nhiều và dễ dàng lưu vào bộ nhớ cache hơn nhưng không thể cung cấp nội dung động.
Máy chủ web cũng có thể thường xuyên được tìm thấy được nhúng trong các thiết bị như máy in, bộ định tuyến, webcam và chỉ phục vụ một mạng cục bộ. Sau đó, máy chủ web có thể được sử dụng như một phần của hệ thống để theo dõi hoặc quản trị thiết bị được đề cập. Điều này thường có nghĩa là không có phần mềm bổ sung nào phải được cài đặt trên máy khách vì chỉ cần một trình duyệt web (hiện đã có trong hầu hết các hệ điều hành).
Cookie web
[sửa | sửa mã nguồn]Cookie HTTP (còn được gọi là cookie web, Internet cookie, cookie trình duyệt hoặc đơn giản là cookie) là một phần nhỏ dữ liệu được gửi từ một trang web và được trình duyệt web của người dùng lưu trữ trên máy tính của người dùng trong khi người dùng đang duyệt. Cookies được thiết kế để trở thành một cơ chế đáng tin cậy để các trang web ghi nhớ thông tin trạng thái (như các mục được thêm vào giỏ hàng trong cửa hàng trực tuyến) hoặc để ghi lại hoạt động duyệt của người dùng (bao gồm nhấp vào nút cụ thể, đăng nhập hoặc ghi lại trang nào đã được truy cập trong quá khứ). Chúng cũng có thể được sử dụng để ghi nhớ các mẩu thông tin tùy ý mà người dùng trước đây đã nhập vào các trường mẫu như tên, địa chỉ, mật khẩu và số thẻ tín dụng.
Các loại cookie khác thực hiện các chức năng thiết yếu trong web hiện đại. Có lẽ quan trọng nhất, cookie xác thực là phương pháp phổ biến nhất được sử dụng bởi các máy chủ web để biết liệu người dùng có đăng nhập hay không và họ đăng nhập vào tài khoản nào. Nếu không có cơ chế như vậy, trang web sẽ không biết nên gửi một trang có chứa thông tin nhạy cảm hay yêu cầu người dùng tự xác thực bằng cách đăng nhập. Tính bảo mật của cookie xác thực thường phụ thuộc vào bảo mật của trang web phát hành và trình duyệt web của người dùng và vào việc dữ liệu cookie có được mã hóa hay không. Các lỗ hổng bảo mật có thể cho phép hacker đọc dữ liệu của cookie, được sử dụng để có quyền truy cập vào dữ liệu người dùng hoặc được sử dụng để có quyền truy cập (với thông tin xác thực của người dùng) vào trang web có cookie (xem kịch bản chéo và chéo trang trang web yêu cầu giả mạo).[56]
Cookie theo dõi, và đặc biệt là cookie theo dõi của bên thứ ba, thường được sử dụng làm cách để lập hồ sơ dài hạn về lịch sử duyệt web của cá nhân – mối lo ngại về quyền riêng tư khiến Châu Âu[57] và các nhà lập pháp Hoa Kỳ phải hành động vào năm 2011.[58][59] Luật pháp châu Âu yêu cầu tất cả các trang web nhắm mục tiêu đến các quốc gia thành viên Liên minh châu Âu phải có được "sự đồng ý" từ người dùng trước khi lưu trữ cookie không cần thiết trên thiết bị của họ.
Nhà nghiên cứu của Google Project Zero, Jann Horn mô tả cách các cookie có thể được đọc bởi một bên trung gian, như nhà cung cấp điểm truy cập Wi-Fi. Ông khuyến nghị sử dụng trình duyệt ở chế độ ẩn danh trong những trường hợp như vậy.[60]
Công cụ tìm kiếm
[sửa | sửa mã nguồn]
Công cụ tìm kiếm web hoặc công cụ tìm kiếm Internet là một hệ thống phần mềm được thiết kế để thực hiện tìm kiếm trên web (tìm kiếm Internet), có nghĩa là tìm kiếm World Wide Web theo cách có hệ thống để biết thông tin cụ thể được chỉ định trong truy vấn tìm kiếm trên web. Các kết quả tìm kiếm thường được trình bày trong một dòng kết quả, thường được gọi là các trang kết quả của công cụ tìm kiếm (SERPs). Thông tin có thể là một hỗn hợp của các trang web, hình ảnh, video, infographics, bài viết, tài liệu nghiên cứu và các loại tệp khác. Một số công cụ tìm kiếm cũng khai thác dữ liệu có sẵn trong cơ sở dữ liệu hoặc thư mục mở. Không giống như các thư mục web, được duy trì bởi các biên tập viên của con người, các công cụ tìm kiếm cũng duy trì thông tin theo thời gian thực bằng cách chạy một thuật toán trên trình thu thập dữ liệu web. Nội dung Internet không có khả năng được tìm kiếm bởi một công cụ tìm kiếm web thường được mô tả là Web chìm.
Deep web
[sửa | sửa mã nguồn]Web chìm,[61] web vô hình,[62] hoặc web ẩn[63] là một phần của World Wide Web có nội dung không được lập chỉ mục bởi các công cụ tìm kiếm web tiêu chuẩn. Thuật ngữ ngược lại với web sâu là web bề mặt, có thể truy cập được đối với bất kỳ ai sử dụng Internet.[64] Nhà khoa học máy tính Michael K. Bergman được cho là đã đặt ra thuật ngữ deep web vào năm 2001 như một thuật ngữ lập chỉ mục tìm kiếm.[65]
Nội dung của web sâu được ẩn đằng sau các biểu mẫu HTTP,[66][67] và bao gồm nhiều cách sử dụng rất phổ biến như thư trên web, ngân hàng trực tuyến và các dịch vụ mà người dùng phải trả tiền và được bảo vệ bởi một Paywall, video theo yêu cầu, một số tạp chí và báo trực tuyến, trong số những loại khác.
Nội dung của web sâu có thể được định vị và truy cập bằng một địa chỉ URL hoặc IP trực tiếp và có thể yêu cầu mật khẩu hoặc quyền truy cập bảo mật khác qua trang web công cộng.
Bảo mật web
[sửa | sửa mã nguồn]Đối với tội phạm, Web đã trở thành một địa điểm để phát tán phần mềm độc hại và tham gia vào một loạt các tội phạm mạng, bao gồm trộm cắp danh tính, lừa đảo, gián điệp và thu thập thông tin tình báo.[68] Các lỗ hổng dựa trên web hiện vượt xa các mối lo ngại về bảo mật máy tính truyền thống,[69][70] và theo đo lường của Google, khoảng một trong mười trang web có thể chứa mã độc.[71] Hầu hết các cuộc tấn công dựa trên web diễn ra trên các trang web hợp pháp và hầu hết, được đo lường bởi Sophos, được lưu trữ tại Hoa Kỳ, Trung Quốc và Nga.[72] Phổ biến nhất trong tất cả các mối đe dọa phần mềm độc hại là các cuộc tấn công tiêm nhiễm SQL vào các trang web.[73] Thông qua HTML và URI, Web dễ bị tấn công như kịch bản chéo trang (XSS) đi kèm với việc giới thiệu JavaScript[74] và bị thiết kế web Web 2.0 và Ajax làm cho việc sử dụng các tập lệnh bị trầm trọng hơn[75] Ngày nay theo một ước tính, 70% tất cả các trang web được mở cho các cuộc tấn công XSS vào người dùng của họ.[76] Lừa đảo là một mối đe dọa phổ biến khác đối với Web. Vào tháng 2 năm 2013, RSA (bộ phận bảo mật của EMC) ước tính thiệt hại toàn cầu từ lừa đảo ở mức 1,5 tỷ đô la vào năm 2012.[77] Hai trong số các phương thức lừa đảo nổi tiếng là Covert Redirect và Open Redirect.
Các công ty đã đề xuất các giải pháp khác nhau. Các công ty bảo mật lớn như McAfee đã thiết kế các bộ quản trị và tuân thủ để đáp ứng các quy định sau ngày 11/9,[78] và một số, như Finjan đã khuyến nghị kiểm tra mã lập trình theo thời gian thực và tất cả nội dung bất kể nguồn gốc của nó là gì.[68] Một số người lập luận rằng các doanh nghiệp coi bảo mật Web là cơ hội kinh doanh chứ không phải là trung tâm chi phí,[79] trong khi những người khác kêu gọi "quản lý quyền kỹ thuật số luôn luôn phổ biến" được thi hành trong cơ sở hạ tầng để thay thế hàng trăm công ty bảo mật dữ liệu và mạng.[80] Jonathan Zittrain đã nói rằng người dùng chia sẻ trách nhiệm về an toàn điện toán là tốt hơn nhiều so với việc khóa Internet.[81]
Tính riêng tư
[sửa | sửa mã nguồn]Mỗi khi khách hàng yêu cầu một trang web, máy chủ có thể xác định địa chỉ IP của yêu cầu và thường ghi nhật ký. Ngoài ra, trừ khi được đặt không làm như vậy, hầu hết các trình duyệt web ghi lại các trang web được yêu cầu trong một tính năng lịch sử có thể xem được và thường lưu trữ nhiều nội dung cục bộ. Trừ khi giao tiếp trên trình duyệt máy chủ sử dụng mã hóa HTTPS, các yêu cầu và phản hồi web truyền đi trong văn bản thuần túy trên Internet và có thể được xem, ghi lại và lưu trữ bởi các hệ thống trung gian. Khi một trang web yêu cầu và người dùng cung cấp, thông tin nhận dạng cá nhân của Wapsuch là tên thật, địa chỉ, địa chỉ email,v.v...các thực thể dựa trên web có thể liên kết lưu lượng truy cập web hiện tại với cá nhân đó. Nếu trang web sử dụng cookie HTTP, xác thực tên người dùng và mật khẩu hoặc các kỹ thuật theo dõi khác, nó có thể liên quan đến các lượt truy cập web khác, trước và sau với thông tin nhận dạng được cung cấp. Theo cách này, một tổ chức dựa trên web có thể phát triển và xây dựng hồ sơ của từng người sử dụng trang web hoặc trang web của mình. Nó có thể có thể xây dựng một hồ sơ cho một cá nhân bao gồm thông tin về các hoạt động giải trí, sở thích mua sắm, nghề nghiệp của họ và các khía cạnh khác trong hồ sơ nhân khẩu học của họ. Những hồ sơ này rõ ràng là mối quan tâm tiềm năng cho các nhà tiếp thị, nhà quảng cáo và những người khác. Tùy thuộc vào các điều khoản và điều kiện của trang web và luật pháp địa phương áp dụng thông tin từ các hồ sơ này có thể được bán, chia sẻ hoặc chuyển cho các tổ chức khác mà không cần thông báo cho người dùng. Đối với nhiều người bình thường, điều này có nghĩa ít hơn một số e-mail bất ngờ trong hộp của họ hoặc một số quảng cáo có liên quan không đáng có trên một trang web trong tương lai. Đối với những người khác, điều đó có thể có nghĩa là thời gian dành cho một mối quan tâm bất thường có thể dẫn đến một sự tiếp thị mục tiêu tiếp theo có thể không được chào đón. Thực thi pháp luật, chống khủng bố và các cơ quan gián điệp cũng có thể xác định, nhắm mục tiêu và theo dõi các cá nhân dựa trên lợi ích hoặc thông tin của họ trên Web.
Dịch vụ mạng xã hội cố gắng khiến người dùng sử dụng tên thật, sở thích và địa điểm của họ, thay vì bút danh, vì giám đốc điều hành của họ tin rằng điều này làm cho trải nghiệm mạng xã hội hấp dẫn hơn đối với người dùng. Mặt khác, các bức ảnh được tải lên hoặc các tuyên bố không được bảo vệ có thể được xác định cho một cá nhân, người có thể hối tiếc về sự phơi bày này. Nhà tuyển dụng, trường học, phụ huynh và người thân khác có thể bị ảnh hưởng bởi các khía cạnh của hồ sơ mạng xã hội, chẳng hạn như bài đăng văn bản hoặc ảnh kỹ thuật số, rằng cá nhân đăng bài không có ý định cho những khán giả này. Những kẻ bắt nạt trực tuyến có thể sử dụng thông tin cá nhân để quấy rối hoặc theo dõi người dùng. Các trang web mạng xã hội hiện đại cho phép kiểm soát chi tiết các cài đặt quyền riêng tư cho từng bài đăng riêng lẻ, nhưng chúng có thể phức tạp và không dễ tìm hoặc sử dụng, đặc biệt là cho người mới bắt đầu.[82] Hình ảnh và video được đăng lên các trang web đã gây ra các vấn đề cụ thể, vì chúng có thể thêm khuôn mặt của một người vào hồ sơ trực tuyến. Với công nghệ nhận dạng khuôn mặt hiện đại và tiềm năng, sau đó có thể liên kết khuôn mặt đó với các hình ảnh, sự kiện và tình huống ẩn danh khác trước đây đã được chụp lại ở nơi khác. Do bộ nhớ đệm hình ảnh, bản sao mirror và sao chép, rất khó để xóa hình ảnh khỏi World Wide Web.
Tiêu chuẩn
[sửa | sửa mã nguồn]Các tiêu chuẩn web bao gồm nhiều tiêu chuẩn và thông số kỹ thuật phụ thuộc lẫn nhau, một số trong đó chi phối các khía cạnh của Internet, không chỉ World Wide Web. Ngay cả khi không tập trung vào web, các tiêu chuẩn như vậy trực tiếp hoặc gián tiếp ảnh hưởng đến sự phát triển và quản trị của các trang web và dịch vụ web. Cân nhắc bao gồm khả năng tương tác, khả năng truy cập và khả năng sử dụng của các trang web và trang web.
Các tiêu chuẩn web, theo nghĩa rộng hơn, bao gồm những chuẩn sau đây:
- Các khuyến nghị được công bố bởi World Wide Web Consortium (W3C) [83]
- "Mức sống" được thực hiện bởi Nhóm làm việc về công nghệ ứng dụng siêu văn bản Web (WHATWG)
- Tài liệu Yêu cầu Nhận xét (RFC) do Lực lượng đặc nhiệm Kỹ thuật Internet (IETF) xuất bản [84]
- Các tiêu chuẩn được công bố bởi Tổ chức tiêu chuẩn hóa quốc tế (ISO) [85]
- Các tiêu chuẩn được công bố bởi Ecma International (trước đây là ECMA) [86]
- Tiêu chuẩn Unicode và các báo cáo kỹ thuật Unicode (UTR) khác nhau được công bố bởi Hiệp hội Unicode [87]
- Các cơ quan đăng ký tên và số được duy trì bởi Cơ quan cấp số được gán Internet (IANA) [88]
Các tiêu chuẩn web không phải là các bộ quy tắc cố định, mà là một bộ liên tục phát triển các thông số kỹ thuật hoàn thiện của các công nghệ web.[89] Các tiêu chuẩn web được phát triển bởi các tổ chức tiêu chuẩn Nhóm nhóm của các bên quan tâm và thường cạnh tranh với nhiệm vụ tiêu chuẩn hóa không phải là công nghệ được phát triển và tuyên bố là tiêu chuẩn của một cá nhân hoặc công ty. Điều rất quan trọng để phân biệt các thông số kỹ thuật đang được phát triển với các thông số kỹ thuật đã đạt đến trạng thái phát triển cuối cùng (trong trường hợp thông số kỹ thuật của W3C, mức trưởng thành cao nhất).
Khả năng tiếp cận
[sửa | sửa mã nguồn]Có các phương pháp để truy cập Web theo các phương tiện và định dạng thay thế để tạo điều kiện cho những người khuyết tật sử dụng. Những khuyết tật này có thể là thị giác, thính giác, thể chất, liên quan đến lời nói, nhận thức, thần kinh hoặc một số kết hợp. Các tính năng trợ năng cũng giúp những người khuyết tật tạm thời, như gãy tay hoặc người dùng già khi khả năng của họ thay đổi.[90] Web nhận thông tin cũng như cung cấp thông tin và tương tác với xã hội. World Wide Web Consortium tuyên bố rằng điều cần thiết là Web có thể truy cập được, vì vậy nó có thể cung cấp quyền truy cập như nhau và cơ hội bình đẳng cho người khuyết tật.[91] Tim Berners-Lee từng lưu ý: "Sức mạnh của Web nằm ở tính phổ quát của nó. Truy cập bởi mọi người bất kể khuyết tật là một khía cạnh thiết yếu."[90] Nhiều quốc gia quy định khả năng truy cập web như một yêu cầu cho các trang web.[92] Hợp tác quốc tế trong Sáng kiến Khả năng truy cập Web của W3C đã dẫn đến các hướng dẫn đơn giản mà các tác giả nội dung web cũng như nhà phát triển phần mềm có thể sử dụng để làm cho Web có thể truy cập được đối với những người có thể hoặc không thể sử dụng công nghệ hỗ trợ.[90][93]
Quốc tế hóa
[sửa | sửa mã nguồn]Hoạt động quốc tế hóa W3C đảm bảo rằng công nghệ web hoạt động trong tất cả các ngôn ngữ, chữ viết và văn hóa.[94] Bắt đầu vào năm 2004 hoặc 2005, Unicode đã có được chỗ đứng và cuối cùng vào tháng 12 năm 2007 đã vượt qua cả ASCII và Tây Âu là mã hóa ký tự được sử dụng thường xuyên nhất trên Web.[95] Ban đầu RFC 3986 cho phép các tài nguyên được xác định bởi URI trong một tập hợp con của US-ASCII. RFC 3987 cho phép nhiều ký tự hơn nữa, bất kỳ ký tự nào trong Bộ ký tự phổ quát, và bây giờ tài nguyên có thể được IRI xác định bằng bất kỳ ngôn ngữ nào.
Bộ nhớ đệm web
[sửa | sửa mã nguồn]Bộ đệm web là một máy tính được đặt trên Internet công cộng hoặc trong một doanh nghiệp lưu trữ các trang web được truy cập gần đây để cải thiện thời gian phản hồi cho người dùng khi cùng một nội dung được yêu cầu trong một thời gian nhất định sau yêu cầu ban đầu. Hầu hết các trình duyệt web cũng triển khai bộ đệm của trình duyệt bằng cách ghi dữ liệu thu được gần đây vào thiết bị lưu trữ dữ liệu cục bộ. Các yêu cầu HTTP của trình duyệt chỉ có thể yêu cầu dữ liệu đã thay đổi kể từ lần truy cập cuối cùng. Các trang web và tài nguyên có thể chứa thông tin hết hạn để kiểm soát bộ nhớ đệm để bảo mật dữ liệu nhạy cảm, như trong ngân hàng trực tuyến hoặc để tạo điều kiện cho các trang web được cập nhật thường xuyên, như phương tiện tin tức. Ngay cả các trang web có nội dung rất năng động đôi khi cũng có thể cho phép các tài nguyên cơ bản được làm mới. Các nhà thiết kế trang web thấy đáng để đối chiếu các tài nguyên như dữ liệu CSS và JavaScript thành một vài tệp trên toàn trang web để chúng có thể được lưu trữ hiệu quả. Tường lửa doanh nghiệp thường lưu trữ tài nguyên web được yêu cầu bởi một người dùng vì lợi ích của nhiều người dùng. Một số công cụ tìm kiếm lưu trữ nội dung lưu trữ của các trang web thường xuyên truy cập.
Xem thêm
[sửa | sửa mã nguồn]Đọc thêm
[sửa | sửa mã nguồn]- Berners-Lee, Tim; Bray, Tim; Connolly, Dan; Cotton, Paul; Fielding, Roy; Jeckle, Mario; Lilley, Chris; Mendelsohn, Noah; Orchard, David; Walsh, Norman; Williams, Stuart (ngày 15 tháng 12 năm 2004). “Architecture of the World Wide Web, Volume One”. Version 20041215. W3C. Chú thích journal cần
|journal=(trợ giúp)Quản lý CS1: nhiều tên: danh sách tác giả (liên kết) - Fielding, R.; Gettys, J.; Mogul, J.; Frystyk, H.; Masinter, L.; Leach, P.; Berners-Lee, T. (tháng 6 năm 1999). “Hypertext Transfer Protocol – HTTP/1.1”. Request For Comments 2616. Information Sciences Institute. Chú thích journal cần
|journal=(trợ giúp)Quản lý CS1: nhiều tên: danh sách tác giả (liên kết) - Niels Brügger, ed. Web History (2010) 362 pages; Historical perspective on the World Wide Web, including issues of culture, content, and preservation.
- Polo, Luciano (2003). “World Wide Web Technology Architecture: A Conceptual Analysis”. New Devices.
|url=trống hay bị thiếu (trợ giúp) - Skau, H.O. (tháng 3 năm 1990). “The World Wide Web and Health Information”. New Devices.
|url=trống hay bị thiếu (trợ giúp)
Liên kết ngoài
[sửa | sửa mã nguồn]- The first website[96]
- Early archive of the first Web site
- Internet Statistics: Growth and Usage of the Web and the Internet
- Living Internet Lưu trữ 2009-01-07 tại Wayback Machine A comprehensive history of the Internet, including the World Wide Web.
- Web Design and Development trên DMOZ
- World Wide Web Consortium (W3C)
- W3C Recommendations Reduce "World Wide Wait"
- World Wide Web Size Daily estimated size of the World Wide Web.
- Antonio A. Casilli, Some Elements for a Sociology of Online Interactions Lưu trữ 2011-05-01 tại Wayback Machine
- The Erdős Webgraph Server Lưu trữ 2021-03-01 tại Wayback Machine offers weekly updated graph representation of a constantly increasing fraction of the WWW.
Tham khảo
[sửa | sửa mã nguồn]- ^ https://www.w3.org/History/1989/proposed.html
- ^ McPherson, Stephanie Sammartino (2009). Tim Berners-Lee: Inventor of the World Wide Web. Twenty-First Century Books. ISBN 978-0-8225-7273-2. Lưu trữ bản gốc ngày 15 tháng 4 năm 2016.
- ^ Quittner, Joshua (ngày 29 tháng 3 năm 1999). “Network Designer Tim Berners-Lee”. Time Magazine. Lưu trữ bản gốc ngày 15 tháng 8 năm 2007. Truy cập ngày 17 tháng 5 năm 2010.
He wove the World Wide Web and created a mass medium for the 21st century. The World Wide Web is Berners-Lee's alone. He designed it. He loosed it on the world. And he more than anyone else has fought to keep it open, nonproprietary and free.
[cần số trang] - ^ “World Wide Web Timeline”. Pew Research Center. ngày 11 tháng 3 năm 2014. Lưu trữ bản gốc ngày 29 tháng 7 năm 2015. Truy cập ngày 1 tháng 8 năm 2015.
- ^ Dewey, Caitlin (ngày 12 tháng 3 năm 2014). “36 Ways the Web Has Changed Us”. The Washington Post. Lưu trữ bản gốc ngày 9 tháng 9 năm 2015. Truy cập ngày 1 tháng 8 năm 2015.
- ^ “Internet Live Stats”. Lưu trữ bản gốc ngày 2 tháng 7 năm 2015. Truy cập ngày 1 tháng 8 năm 2015.
- ^ Joseph Adamski; Kathy Finnegan (2007). New Perspectives on Microsoft Office Access 2007, Comprehensive. Cengage Learning. tr. 390. ISBN 978-1-4239-0589-9.
- ^ Enzer, Larry (ngày 31 tháng 8 năm 2018). “The Evolution of the World Wide Web”. Monmouth Web Developers. Bản gốc lưu trữ ngày 18 tháng 11 năm 2018. Truy cập ngày 31 tháng 8 năm 2018.
- ^ “Archived copy” (PDF). Bản gốc (PDF) lưu trữ ngày 17 tháng 11 năm 2015. Truy cập ngày 26 tháng 8 năm 2015.Quản lý CS1: bản lưu trữ là tiêu đề (liên kết)
- ^ May, Ashley (ngày 12 tháng 3 năm 2019). “Happy 30th birthday, World Wide Web. Inventor outlines plan to combat hacking, hate speech”. USA Today (bằng tiếng Anh). Truy cập ngày 12 tháng 3 năm 2019.
- ^ Aja Romano (ngày 12 tháng 3 năm 2019). “The World Wide Web — not the internet — turns 30 years old”. Vox.com.
- ^ Berners-Lee, Tim (tháng 3 năm 1989). “Information Management: A Proposal”. W3C. Lưu trữ bản gốc ngày 15 tháng 3 năm 2009. Truy cập ngày 27 tháng 7 năm 2009.
- ^ a b Berners-Lee, Tim; Cailliau, Robert (ngày 12 tháng 11 năm 1990). “WorldWideWeb: Proposal for a HyperText Project”. Lưu trữ bản gốc ngày 2 tháng 5 năm 2015. Truy cập ngày 12 tháng 5 năm 2015.
- ^ “Tim Berners-Lee's original World Wide Web browser”. Lưu trữ bản gốc ngày 17 tháng 7 năm 2011.
With recent phenomena like blogs and wikis, the Web is beginning to develop the kind of collaborative nature that its inventor envisaged from the start.
- ^ “Tim Berners-Lee: client”. W3.org. Lưu trữ bản gốc ngày 21 tháng 7 năm 2009. Truy cập ngày 27 tháng 7 năm 2009.
- ^ “First Web pages”. W3.org. Lưu trữ bản gốc ngày 31 tháng 1 năm 2010. Truy cập ngày 27 tháng 7 năm 2009.
- ^ “The birth of the web”. CERN. Lưu trữ bản gốc ngày 24 tháng 12 năm 2015. Truy cập ngày 23 tháng 12 năm 2015.
- ^ Murawski, John (ngày 24 tháng 5 năm 2013). “Hunt for world's oldest WWW page leads to UNC Chapel Hill”. News & Observer. Bản gốc lưu trữ ngày 8 tháng 6 năm 2013.
- ^ “Short summary of the World Wide Web project”. ngày 6 tháng 8 năm 1991. Truy cập ngày 27 tháng 7 năm 2009.
- ^ “Silvano de Gennaro disclaims 'the first photo on the Web'”. Lưu trữ bản gốc ngày 4 tháng 8 năm 2012. Truy cập ngày 27 tháng 7 năm 2012.
If you read well our website, it says that it was, to our knowledge, the 'first photo of a band'. Dozens of media are totally distorting our words for the sake of cheap sensationalism. Nobody knows which was the first photo on the Web.
- ^ “W3C timeline”. Lưu trữ bản gốc ngày 31 tháng 3 năm 2010. Truy cập ngày 30 tháng 3 năm 2010.
- ^ “The Early World Wide Web at SLAC”. Lưu trữ bản gốc ngày 24 tháng 11 năm 2005.
- ^ “About SPIRES”. Lưu trữ bản gốc ngày 12 tháng 2 năm 2010. Truy cập ngày 30 tháng 3 năm 2010.
- ^ “A Little History of the World Wide Web”. Lưu trữ bản gốc ngày 6 tháng 5 năm 2013.
- ^ “Inventor of the Week Archive: The World Wide Web”. Massachusetts Institute of Technology: MIT School of Engineering. Bản gốc lưu trữ ngày 8 tháng 6 năm 2010. Truy cập ngày 23 tháng 7 năm 2009.
- ^ “Ten Years Public Domain for the Original Web Software”. Tenyears-www.web.cern.ch. ngày 30 tháng 4 năm 2003. Lưu trữ bản gốc ngày 13 tháng 8 năm 2009. Truy cập ngày 27 tháng 7 năm 2009.
- ^ “Mosaic Web Browser History – NCSA, Marc Andreessen, Eric Bina”. Livinginternet.com. Bản gốc lưu trữ ngày 18 tháng 5 năm 2010. Truy cập ngày 27 tháng 7 năm 2009.
- ^ “NCSA Mosaic – ngày 10 tháng 9 năm 1993 Demo”. Totic.org. Truy cập ngày 27 tháng 7 năm 2009.
- ^ “Vice President Al Gore's ENIAC Anniversary Speech”. Cs.washington.edu. ngày 14 tháng 2 năm 1996. Lưu trữ bản gốc ngày 20 tháng 2 năm 2009. Truy cập ngày 27 tháng 7 năm 2009.
- ^ “Internet legal definition of Internet”. West's Encyclopedia of American Law, edition 2. Free Online Law Dictionary. ngày 15 tháng 7 năm 2009. Truy cập ngày 25 tháng 11 năm 2008.
- ^ “WWW (World Wide Web) Definition”. TechTerms. Lưu trữ bản gốc ngày 11 tháng 5 năm 2009. Truy cập ngày 19 tháng 2 năm 2010.
- ^ Jacobs, Ian; Walsh, Norman (ngày 15 tháng 12 năm 2004). “Architecture of the World Wide Web, Volume One”. Introduction: W3C. Lưu trữ bản gốc ngày 9 tháng 2 năm 2015. Truy cập ngày 11 tháng 2 năm 2015.
- ^ “Supplement no.1, Diplomatic and Overseas List, K.B.E.” (PDF). thegazette.co.uk. The Gazette. ngày 31 tháng 12 năm 2003. Lưu trữ (PDF) bản gốc ngày 3 tháng 2 năm 2016. Truy cập ngày 7 tháng 2 năm 2016.
- ^ “Web's inventor gets a knighthood”. BBC. ngày 31 tháng 12 năm 2003. Lưu trữ bản gốc ngày 23 tháng 12 năm 2007. Truy cập ngày 25 tháng 5 năm 2008.
- ^ “What is the difference between the Web and the Internet?”. World Wide Web Consortium. Lưu trữ bản gốc ngày 22 tháng 4 năm 2016. Truy cập ngày 18 tháng 4 năm 2016.
- ^ Muylle, Steve; Rudy Moenaert; Marc Despont (1999). “A grounded theory of World Wide Web search behaviour”. Journal of Marketing Communications. 5 (3): 143. doi:10.1080/135272699345644. ISSN 1352-7266. Lưu trữ bản gốc ngày 20 tháng 10 năm 2014.
- ^ Flanagan, David. JavaScript – The definitive guide (ấn bản thứ 6). tr. 1.
JavaScript is part of the triad of technologies that all Web developers must learn: HTML to specify the content of web pages, CSS to specify the presentation of web pages, and JavaScript to specify the behaviour of web pages.
- ^ “HTML 4.0 Specification — W3C Recommendation — Conformance: requirements and recommendations”. World Wide Web Consortium. ngày 18 tháng 12 năm 1997. Truy cập ngày 6 tháng 7 năm 2015.
- ^ Berners-Lee, Tim. “Frequently asked questions by the Press”. W3C. Lưu trữ bản gốc ngày 2 tháng 8 năm 2009. Truy cập ngày 27 tháng 7 năm 2009.
- ^ Palazzi, P (2011) 'The Early Days of the WWW at CERN' Lưu trữ 2012-07-23 tại Wayback Machine
- ^ Dominic Fraser (ngày 13 tháng 5 năm 2018). “Why a domain's root can't be a CNAME — and other tidbits about the DNS”. FreeCodeCamp.
- ^ “automatically adding www.___.com”. mozillaZine. ngày 16 tháng 5 năm 2003. Lưu trữ bản gốc ngày 27 tháng 6 năm 2009. Truy cập ngày 27 tháng 5 năm 2009.
- ^ Masnick, Mike (ngày 7 tháng 7 năm 2008). “Microsoft Patents Adding 'www.' And '.com' To Text”. Techdirt. Lưu trữ bản gốc ngày 27 tháng 6 năm 2009. Truy cập ngày 27 tháng 5 năm 2009.
- ^ “Audible pronunciation of 'WWW'”. Oxford University Press. Lưu trữ bản gốc ngày 25 tháng 5 năm 2014. Truy cập ngày 25 tháng 5 năm 2014.
- ^ “Stephen Fry's pronunciation of 'WWW'”. Podcasts.com. Lưu trữ bản gốc ngày 4 tháng 4 năm 2017.
- ^ Simonite, Tom (ngày 22 tháng 7 năm 2008). “Help us find a better way to pronounce www”. newscientist.com. New Scientist, Technology. Lưu trữ bản gốc ngày 13 tháng 3 năm 2016. Truy cập ngày 7 tháng 2 năm 2016.
- ^ “MDBG Chinese-English dictionary – Translate”. Lưu trữ bản gốc ngày 12 tháng 11 năm 2008. Truy cập ngày 27 tháng 7 năm 2009.
- ^ “Frequently asked questions by the Press – Tim BL”. W3.org. Lưu trữ bản gốc ngày 2 tháng 8 năm 2009. Truy cập ngày 27 tháng 7 năm 2009.
- ^ Castelluccio, Michael (2010). “It's not your grandfather's Internet”. thefreelibrary.com. Institute of Management Accountants. Truy cập ngày 7 tháng 2 năm 2016.
- ^ a b Hamilton, Naomi (ngày 31 tháng 7 năm 2008). “The A-Z of Programming Languages: JavaScript”. Computerworld. IDG. Lưu trữ bản gốc ngày 24 tháng 5 năm 2009. Truy cập ngày 12 tháng 5 năm 2009.
- ^ Buntin, Seth (ngày 23 tháng 9 năm 2008). “jQuery Polling plugin”. Bản gốc lưu trữ ngày 13 tháng 8 năm 2009. Truy cập ngày 22 tháng 8 năm 2009.
- ^ “website”. TheFreeDictionary.com. Truy cập ngày 2 tháng 7 năm 2011.
- ^ “Difference Between Search Engine and Browser”.
- ^ “What is web server?'”. webdevelopersnotes. ngày 23 tháng 11 năm 2010. Truy cập ngày 1 tháng 2 năm 2019.
- ^ Patrick, Killelea (2002). Web performance tuning (ấn bản thứ 2). Beijing: O'Reilly. tr. 264. ISBN 978-0596001728. OCLC 49502686.
- ^ Vamosi, Robert (ngày 14 tháng 4 năm 2008). “Gmail cookie stolen via Google Spreadsheets”. News.cnet.com. Bản gốc lưu trữ ngày 9 tháng 12 năm 2013. Truy cập ngày 19 tháng 10 năm 2017.
- ^ “What about the "EU Cookie Directive"?”. WebCookies.org. 2013. Bản gốc lưu trữ ngày 11 tháng 10 năm 2017. Truy cập ngày 19 tháng 10 năm 2017.
- ^ “New net rules set to make cookies crumble”. BBC. ngày 8 tháng 3 năm 2011.
- ^ “Sen. Rockefeller: Get Ready for a Real Do-Not-Track Bill for Online Advertising”. Adage.com. ngày 6 tháng 5 năm 2011.
- ^ Bạn muốn sử dụng wifi của tôi?, Jann Horn, truy cập 2018-01-05.
- ^ Hamilton, Nigel. “The Mechanics of a Deep Net Metasearch Engine”. CiteSeerX 10.1.1.90.5847. Chú thích journal cần
|journal=(trợ giúp) - ^ Devine, Jane; Egger-Sider, Francine (tháng 7 năm 2004). “Beyond google: the invisible web in the academic library”. The Journal of Academic Librarianship. 30 (4): 265–269. doi:10.1016/j.acalib.2004.04.010.
- ^ Raghavan, Sriram; Garcia-Molina, Hector (September 11–14, 2001). “Crawling the Hidden Web”. 27th International Conference on Very Large Data Bases.
- ^ “Surface Web”. Computer Hope. Truy cập ngày 20 tháng 6 năm 2018.
- ^ Wright, Alex (2009-2-22). "Khám phá một 'Deep Web' mà Google không thể nắm bắt được". Thời báo New York . Truy cập 2009-02-23.
- ^ Madhavan, J., Ko, D., Kot, Ł., Ganapathy, V., Rasmussen, A., & Halevy, A. (2008). Thu thập dữ liệu web sâu của Google. Thủ tục tố tụng của VLDB, 1 (2), 1241 Tiết52.
- ^ Shedden, Sam (ngày 8 tháng 6 năm 2014). “How Do You Want Me to Do It? Does It Have to Look like an Accident? – an Assassin Selling a Hit on the Net; Revealed Inside the Deep Web”. Bản gốc lưu trữ ngày 1 tháng 3 năm 2020. Truy cập ngày 5 tháng 5 năm 2017 – qua Questia.
- ^ a b Ben-Itzhak, Yuval (ngày 18 tháng 4 năm 2008). “Infosecurity 2008 – New defence strategy in battle against e-crime”. ComputerWeekly. Reed Business Information. Lưu trữ bản gốc ngày 4 tháng 6 năm 2008. Truy cập ngày 20 tháng 4 năm 2008.
- ^ Christey, Steve & Martin, Robert A. (ngày 22 tháng 5 năm 2007). “Vulnerability Type Distributions in CVE (version 1.1)”. MITRE Corporation. Lưu trữ bản gốc ngày 15 tháng 4 năm 2013. Truy cập ngày 7 tháng 6 năm 2008.
- ^ “Symantec Internet Security Threat Report: Trends for July–December 2007 (Executive Summary)” (PDF). XIII. Symantec Corp. tháng 4 năm 2008: 1–2. Lưu trữ (PDF) bản gốc ngày 25 tháng 6 năm 2008. Truy cập ngày 11 tháng 5 năm 2008. Chú thích journal cần
|journal=(trợ giúp) - ^ “Google searches web's dark side”. BBC News. ngày 11 tháng 5 năm 2007. Lưu trữ bản gốc ngày 7 tháng 3 năm 2008. Truy cập ngày 26 tháng 4 năm 2008.
- ^ “Security Threat Report (Q1 2008)” (PDF). Sophos. Lưu trữ (PDF) bản gốc ngày 15 tháng 4 năm 2013. Truy cập ngày 24 tháng 4 năm 2008.
- ^ “Security threat report” (PDF). Sophos. tháng 7 năm 2008. Lưu trữ (PDF) bản gốc ngày 15 tháng 4 năm 2013. Truy cập ngày 24 tháng 8 năm 2008.
- ^ Fogie, Seth, Jeremiah Grossman, Robert Hansen, and Anton Rager (2007). Cross Site Scripting Attacks: XSS Exploits and Defense (PDF). Syngress, Elsevier Science & Technology. tr. 68–69, 127. ISBN 978-1-59749-154-9. Bản gốc (PDF) lưu trữ ngày 25 tháng 6 năm 2008. Truy cập ngày 6 tháng 6 năm 2008.Quản lý CS1: nhiều tên: danh sách tác giả (liên kết)
- ^ O'Reilly, Tim (ngày 30 tháng 9 năm 2005). “What Is Web 2.0”. O'Reilly Media. tr. 4–5. Lưu trữ bản gốc ngày 15 tháng 4 năm 2013. Truy cập ngày 4 tháng 6 năm 2008. and AJAX web applications can introduce security vulnerabilities like "client-side security controls, increased attack surfaces, and new possibilities for Cross-Site Scripting (XSS)", in Ritchie, Paul (tháng 3 năm 2007). “The security risks of AJAX/web 2.0 applications” (PDF). Infosecurity. Bản gốc (PDF) lưu trữ ngày 25 tháng 6 năm 2008. Truy cập ngày 6 tháng 6 năm 2008. which cites Hayre, Jaswinder S. & Kelath, Jayasankar (ngày 22 tháng 6 năm 2006). “Ajax Security Basics”. SecurityFocus. Lưu trữ bản gốc ngày 15 tháng 5 năm 2008. Truy cập ngày 6 tháng 6 năm 2008.
- ^ Berinato, Scott (ngày 1 tháng 1 năm 2007). “Software Vulnerability Disclosure: The Chilling Effect”. CSO. CXO Media. tr. 7. Bản gốc lưu trữ ngày 18 tháng 4 năm 2008. Truy cập ngày 7 tháng 6 năm 2008.
- ^ “2012 Global Losses From phishing Estimated At $1.5 Bn”. FirstPost. ngày 20 tháng 2 năm 2013. Lưu trữ bản gốc ngày 21 tháng 12 năm 2014. Truy cập ngày 25 tháng 1 năm 2019.
- ^ Prince, Brian (ngày 9 tháng 4 năm 2008). “McAfee Governance, Risk and Compliance Business Unit”. eWEEK. Ziff Davis Enterprise Holdings. Truy cập ngày 25 tháng 4 năm 2008.
- ^ Preston, Rob (ngày 12 tháng 4 năm 2008). “Down To Business: It's Past Time To Elevate The Infosec Conversation”. InformationWeek. United Business Media. Lưu trữ bản gốc ngày 14 tháng 4 năm 2008. Truy cập ngày 25 tháng 4 năm 2008.
- ^ Claburn, Thomas (ngày 6 tháng 2 năm 2007). “RSA's Coviello Predicts Security Consolidation”. InformationWeek. United Business Media. Lưu trữ bản gốc ngày 7 tháng 2 năm 2009. Truy cập ngày 25 tháng 4 năm 2008.
- ^ Duffy Marsan, Carolyn (ngày 9 tháng 4 năm 2008). “How the iPhone is killing the 'Net”. Network World. IDG. Bản gốc lưu trữ ngày 14 tháng 4 năm 2008. Truy cập ngày 17 tháng 4 năm 2008.
- ^ boyd, danah; Hargittai, Eszter (tháng 7 năm 2010). “Facebook privacy settings: Who cares?”. First Monday. 15 (8). doi:10.5210/fm.v15i8.3086.
- ^ “W3C Technical Reports and Publications”. W3C. Truy cập ngày 19 tháng 1 năm 2009.
- ^ “IETF RFC page”. IETF. Truy cập ngày 19 tháng 1 năm 2009.
- ^ “Search for World Wide Web in ISO standards”. ISO. Truy cập ngày 19 tháng 1 năm 2009.
- ^ “Ecma formal publications”. Ecma. Truy cập ngày 19 tháng 1 năm 2009.
- ^ “Unicode Technical Reports”. Unicode Consortium. Truy cập ngày 19 tháng 1 năm 2009.
- ^ “IANA home page”. IANA. Truy cập ngày 19 tháng 1 năm 2009.
- ^ Leslie Sikos (2011). Web standards - Mastering HTML5, CSS3, and XML. Apress. ISBN 978-1-4302-4041-9. Bản gốc lưu trữ ngày 2 tháng 4 năm 2015. Truy cập ngày 13 tháng 3 năm 2019.
- ^ a b c “Web Accessibility Initiative (WAI)”. World Wide Web Consortium. Bản gốc lưu trữ ngày 2 tháng 4 năm 2009. Truy cập ngày 7 tháng 4 năm 2009.
- ^ “Developing a Web Accessibility Business Case for Your Organization: Overview”. World Wide Web Consortium. Lưu trữ bản gốc ngày 14 tháng 4 năm 2009. Truy cập ngày 7 tháng 4 năm 2009.
- ^ “Legal and Policy Factors in Developing a Web Accessibility Business Case for Your Organization”. World Wide Web Consortium. Lưu trữ bản gốc ngày 5 tháng 4 năm 2009. Truy cập ngày 7 tháng 4 năm 2009.
- ^ “Web Content Accessibility Guidelines (WCAG) Overview”. World Wide Web Consortium. Lưu trữ bản gốc ngày 1 tháng 4 năm 2009. Truy cập ngày 7 tháng 4 năm 2009.
- ^ “Internationalization (I18n) Activity”. World Wide Web Consortium. Lưu trữ bản gốc ngày 16 tháng 4 năm 2009. Truy cập ngày 10 tháng 4 năm 2009.
- ^ Davis, Mark (ngày 5 tháng 4 năm 2008). “Moving to Unicode 5.1”. Google. Lưu trữ bản gốc ngày 21 tháng 5 năm 2009. Truy cập ngày 10 tháng 4 năm 2009.
- ^ “http://info.cern.ch - home of the first website”. CERN. Truy cập ngày 12 tháng 6 năm 2014. Liên kết ngoài trong
|title=(trợ giúp)