Compilador
| Execução de Programa |
|---|
| Conceitos gerais |
| Tipos de código |
| Estratégia de compilação |
|
| Runtimes notáveis |
|
| Compiladores notáveis e toolchain |
|

Um compilador é um programa de computador (ou um grupo de programas) que, a partir de um código fonte escrito em uma linguagem compilada, cria um programa semanticamente equivalente, porém escrito em outra linguagem, código objeto.[1] Classicamente, um compilador traduz um programa de uma linguagem textual facilmente entendida por um ser humano para uma linguagem de máquina , específica para um processador e sistema operacional. Atualmente, porém, são comuns compiladores que geram código para uma máquina virtual que é, depois, interpretada por um interpretador. Ele é chamado compilador por razões históricas; nos primeiros anos da programação automática, existiam programas que percorriam bibliotecas de sub-rotinas e as reunia, ou compilava,[Nota 1] as subrotinas necessárias para executar uma determinada tarefa.[2][3]
O nome "compilador" é usado principalmente para os programas que traduzem o código fonte de uma linguagem de programação de alto nível para uma linguagem de programação de baixo nível (por exemplo, Assembly ou código de máquina). Contudo alguns autores citam exemplos de compiladores que traduzem para linguagens de alto nível como C.[4] Para alguns autores um programa que faz uma tradução entre linguagens de alto nível é normalmente chamado um tradutor, filtro[5] ou conversor de linguagem. Um programa que traduz uma linguagem de programação de baixo nível para uma linguagem de programação de alto nível é um descompilador.[6] Um programa que faz uma tradução entre uma linguagem de montagem e o código de máquina é denominado montador (assembler).[5] Um programa que faz uma tradução entre o código de máquina e uma linguagem de montagem é denominado desmontador (disassembler).[6] Se o programa compilado pode ser executado em um computador cuja CPU ou sistema operacional é diferente daquele em que o compilador é executado, o compilador é conhecido como um compilador cruzado.[7]
História
[editar | editar código-fonte]
Os softwares para os primeiros computadores foram escritos principalmente em linguagem assembly por muitos anos. As linguagens de alto nível de programação não foram inventadas até que os benefícios de ser capaz de reutilizar software em diferentes tipos de CPUs passassem a ser significativamente maiores do que o custo de se escrever um compilador. A capacidade de memória muito limitada dos primeiros computadores também criava muitos problemas técnicos na implementação de um compilador.
No final da década de 1950, as linguagens de programação independentes de máquina foram propostas. Posteriormente, vários compiladores experimentais foram desenvolvidos. O primeiro compilador foi escrito por Grace Hopper,[8] em 1952, para a linguagem de programação A-0.[9] Antes de 1957, foram desenvolvidos esforços e várias contribuições ao desenvolvimento de linguagens de alto nível foram feitas. Entre estes, o desenvolvimento da Short Code (UNIVAC), Speedcoding no IBM 701,[10][11] o Whirlwind, o BACAIC e o PRINT.[12] A equipe de desenvolvimento do FORTRAN liderada por John Backus na IBM é geralmente creditada como tendo introduzido o primeiro compilador completo em 1957 (embora tenha ocorrido simultaneamente o desenvolvimento do algebraic translator de Laning e Zierler[9]). O COBOL é um exemplo de uma linguagem da primeira geração que compilava em múltiplas arquiteturas, em 1960.[13]
Em muitos domínios de aplicação a ideia de usar uma linguagem de alto nível rapidamente ganhou força. Por causa da funcionalidade de expansão apoiada por linguagens de programação recentes e a complexidade crescente de arquiteturas de computadores, os compiladores tornaram-se mais e mais complexos.
Os primeiros compiladores foram escritos em linguagem assembly. O primeiro compilador de auto-hospedagem - capaz de compilar seu próprio código-fonte em uma linguagem de alto nível - foi criado para o Lisp por Tim Hart e Levin Mike no MIT em 1962.[14]
Características
[editar | editar código-fonte]
Normalmente, o código fonte é escrito em uma linguagem de programação de alto nível, com grande capacidade de abstração, e o código objeto é escrito em uma linguagem de baixo nível,[15] como uma sequência de instruções a ser executada pelo microprocessador.
O processo de compilação é composto de análise e síntese.[16] A análise tem como objetivo entender o código fonte e representá-lo em uma estrutura intermediária. A síntese constrói o código objecto a partir desta representação intermediária.
A análise pode ser subdividida ainda em análise léxica, análise sintática, análise semântica e geração de código intermediário. É também conhecida como front end.[16] A síntese pode ter mais variações de um compilador a outro, podendo ser composta pelas etapas de optimização de código e geração de código final (ou código de máquina), sendo somente esta última etapa é obrigatória. É também conhecida como back end.[16]
Em linguagens híbridas, o compilador tem o papel de converter o código fonte em um código chamado de byte code, que é uma linguagem de baixo nível. Um exemplo deste comportamento é o do compilador da linguagem Java que, em vez de gerar código da máquina hospedeira (onde se está executando o compilador), gera código chamado Java Bytecode.[17]
Um compilador é chamado de Just-in-time compiler (JIT) quando seu processo de compilação acontece apenas quando o código é chamado.[18] Um JIT pode fazer otimizações às instruções a medida que as compila.[18]
Muitos compiladores incluem um pré-processador. Que é um programa separado, ativado pelo compilador antes do início do processo de tradução.[19] Normalmente é responsável por mudanças no código fonte destinadas de acordo com decisões tomadas em tempo de compilação. Por exemplo, um programa em C permite instruções condicionais para o pré-processador que podem incluir ou não parte do código caso uma assertiva lógica seja verdadeira ou falsa, ou simplesmente um termo esteja definido ou não. Tecnicamente, pré-processadores são muito mais simples que compiladores e são vistos, pelos desenvolvedores, como programas à parte, apesar dessa visão não ser necessariamente compartilhada pelo usuário.
Outra parte separada do compilador que muitos usuários vêem como integrada é o linker, cuja função é unir vários programas já compilados de uma forma independente e unificá-los em um programa executável.[20] Isso inclui colocar o programa final em um formato compatível com as necessidades do sistema operacional para carregá-lo em memória e colocá-lo em execução.
Fases da compilação
[editar | editar código-fonte]Análise léxica
[editar | editar código-fonte]A análise léxica é a primeira fase do compilador.[21] A função do analisador léxico, também denominado scanner, é ler o código-fonte, caractere a caractere, buscando a separação e identificação dos elementos componentes do programa-fonte, denominados símbolos léxicos ou tokens.[22] É também de responsabilidade desta fase a eliminação de elementos "decorativos" do programa, tais como espaços em branco, marcas de formatação de texto e comentários.[23] Existem disponíveis uma série de geradores automáticos de analisadores léxicos, como por exemplo, o lex. O objetivo dos geradores automáticos é limitar o esforço de programação de um analisador léxico especificando-se apenas os tokens a ser reconhecidos.[24]
Análise sintática
[editar | editar código-fonte]A análise sintática, ou análise gramatical é o processo de se determinar se uma cadeia de símbolos léxicos pode ser gerada por uma gramática.[25] O analisador sintático é o cerne do compilador, responsável por verificar se os símbolos contidos no programa fonte formam um programa válido, ou não.[26] No caso de analisadores sintáticos top-down, temos a opção de escrevê-los à mão ou gerá-los de forma automática, mas os analisadores bottom-up só podem ser gerados automaticamente.[27] A maioria dos métodos de análise sintática, cai em uma dessas duas classes denominadas top-down e bottom-up.[28] Entre os métodos top-down os mais importantes são a análise sintática descendente recursiva e a análise sintática preditiva não-recursiva. Entre os métodos de análise sintática bottom-up os mais importantes são a análise sintática de precedência de operadores, análise sintática LR canônico, análise sintática LALR e análise sintática SLR.[25] Existem disponíveis uma série de geradores automáticos de analisadores sintáticos,[29] como por exemplo, o Yacc, o Bison e o JavaCC.
Análise semântica
[editar | editar código-fonte]As análises léxica e sintática não estão preocupadas com o significado ou semântica dos programas que elas processam. O papel do analisador semântico é prover métodos pelos quais as estruturas construídas pelo analisador sintático possam ser avaliadas ou executadas.[30] As gramáticas livres de contexto não são suficientemente poderosas para descrever uma série de construções das linguagens de programação, como por exemplo regras de escopo, regras de visibilidade e consistência de tipos.[31] É papel do analisador semântico assegurar que todas as regras sensíveis ao contexto da linguagem estejam analisadas e verificadas quanto à sua validade. Um exemplo de tarefa própria do analisador semântico é a checagem de tipos de variáveis em expressões.[32] Um dos mecanismos comumente utilizados por implementadores de compiladores é a Gramática de Atributos, que consiste em uma gramática livre de contexto acrescentada de um conjunto finito de atributos e um conjunto finito de predicados sobre estes atributos.[33]
Geração de código intermediário
[editar | editar código-fonte]
Na fase de geração de código intermediário, ocorre a transformação da árvore sintática em uma representação intermediária do código fonte. Esta linguagem intermediária é mais próxima da linguagem objeto do que o código fonte, mas ainda permite uma manipulação mais fácil do que se código assembly ou código de máquina fosse utilizado.[34] Um tipo popular de linguagem intermediária é conhecido como código de três endereços.[35] Neste tipo de código uma sentença típica tem a forma X := A op B, onde X, A e B são operandos e op uma operação qualquer. Uma forma prática de representar sentenças de três endereços é através do uso de quádruplas (operador, argumento 1, argumento 2 e, resultado). Este esquema de representação de código intermediário é preferido por diversos compiladores, principalmente aqueles que executam extensivas otimizações de código, uma vez que o código intermediário pode ser rearranjado de uma maneira conveniente com facilidade.[36] Outras representações de código intermediário comumente usadas são as triplas, (similares as quádruplas exceto pelo fato de que os resultados não são nomeados explicitamente) as árvores, os grafos acíclicos dirigidos(DAG) e a notação polonesa.[37]
Otimização de código
[editar | editar código-fonte]A otimização de código é a estratégia de examinar o código intermediário, produzido durante a fase de geração de código com objetivo de produzir, através de algumas técnicas, um código que execute com bastante eficiência.[32] O nome optimizador deve sempre ser encarado com cuidado, pois não se pode criar um programa que leia um programa P e gere um programa P´ equivalente sendo melhor possível segundo o critério adotado.[23] Várias técnicas e várias tarefas se reúnem sob o nome de Optimização. Estas técnicas consistem em detectar padrões dentro do código produzido e substituí-los por códigos mais eficientes.[36] Entre as técnicas usadas estão a substituição de expressões que podem ser avaliadas durante o tempo de compilação pelos seus valores calculados, eliminação de subexpressões redundantes, desmembramento de laços, substituição de operações (multiplicação por shifts), entre outras.[32] Uma das técnicas de optimização mais eficazes e independente de máquina é a otimização de laços, pois laços internos são bons candidatos para melhorias. Por exemplo, em caso de computações fixas dentro de laços, é possível mover estas computações para fora dos mesmos reduzindo processamento.[38]
Geração de código final
[editar | editar código-fonte]A fase de geração de código final é a última fase da compilação. A geração de um bom código objeto é difícil devido aos detalhes particulares das máquinas para os quais o código é gerado. Contudo, é uma fase importante, pois uma boa geração de código pode ser, por exemplo, duas vezes mais rápida que um algoritmo de geração de código ineficiente.[36] Nem todas as técnicas de optimização são independentes da arquitetura da máquina-alvo. Optimizações dependentes da máquina necessitam de informações tais como os limites e os recursos especiais da máquina-alvo a fim de produzir um código mais compacto e eficiente. O código produzido pelo compilador deve se aproveitar dos recursos especiais de cada máquina-alvo.[32] Segundo Aho, o código objeto pode ser uma sequência de instruções absolutas de máquina, uma sequência de instruções de máquina relocáveis, um programa em linguagem assembly ou um programa em outra linguagem.[39]
Tratamento de erros
[editar | editar código-fonte]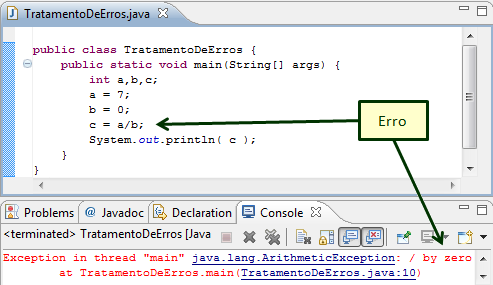
O tratamento de erros está voltado a falhas devido a muitas causas: erros no compilador, erros na elaboração do programa a ser compilado, erros no ambiente (hardware, sistema operacional), dados incorretos, etc. As tarefas relacionadas ao tratamento de erros consistem em detectar cada erro, reportá-lo ao usuário e possivelmente fazer algum reparo para que o processamento possa continuar.[40]
Os erros podem ser classificados em erros léxicos, erros sintáticos, erros não independentes de contexto (semânticos), erros de execução e erros de limite.[41] Os erros léxicos ocorrem quando um token identificado não pertence a gramática da linguagem fonte. Os erros sintáticos ocorrem quando alguma estrutura de frase não está de acordo com a gramática, como por exemplo parênteses sem correspondência. Os erros não independentes de contexto em geral são associados a não declaração de objetos como variáveis e erros de tipos. Os erros de execução ocorrem após a compilação, quando o programa já está sendo executado. Um exemplo típico é o da divisão por zero. Os erros de limite, ocorrem durante a execução e estão relacionados as características da máquina na qual o programa está sendo executado, como por exemplo, estouro de pilha.[41]
Alguns compiladores encerram o processo de tradução logo ao encontrar o primeiro erro do programa-fonte. Esta é uma política de fácil implementação. Compiladores mais sofisticados, porém, detectam o maior número possível de erros visando diminuir o número de compilações.[42]
A recuperação de erros em analisadores sintáticos top-down é mais fácil de implementar do que em analisadores bottom-up.[43] O problema é que diferente de um analisador top-down, este último não sabe quais símbolos são esperados na entrada, somente os que já foram processados. Pode-se usar neste caso técnicas como, por exemplo, a técnica de panic-mode que procura em tabelas sintáticas em busca de símbolos válidos na entrada.[43] Nesta técnica se descartam símbolos da entrada até que um delimitador (como um ponto e vírgula, por exemplo) seja encontrado. O analisador apaga as entradas da pilha até que encontre uma entrada que permita que o processo de análise prossiga em diante.[44]
Ver também
[editar | editar código-fonte]- Ciência da computação
- Compilador Just in Time (JIT)
- Linguagens formais
- Linguagem de programação
- Interpretador
- Linker
Notas
[editar | editar código-fonte]- ↑ Em português, "compilar" significa, por exemplo: reunir obras literárias, documentos, escritos de vários autores, entre outros, compondo uma obra com esse material. Larousse (1992). Dicionário da Língua Portuguesa (em inglês). [S.l.]: Nova Cultural. ISBN 85-85222-23-9
- ↑ Aho, Alfred V.; Ullman, Jeffrey D. (1977). Principles of Compiler Design (em inglês). Reading, Massachusetts, EUA: Addison-Wesley. p. 1. 604 páginas. ISBN 0-201-00022-9
- ↑ Parsons, Thomas W. (1992). Introduction to Compiler Construction (em inglês). Nova Iorque, EUA: Computer Science Press. p. 1. 359 páginas. ISBN 0-7167-8261-8
- ↑ Appel, Andrew W. (1998). Modern Compiler Implementation in Java (em inglês). Cambridge: Cambridge University Press. p. 3. 548 páginas. ISBN 0-521-58388-8
- ↑ Cooper, Torczon (2003). Engineering a Compiler (em inglês). San Francisco: Morgan Kaufmann. p. 2. ISBN 1-55860-698-X
- ↑ a b Neto, João José (1987). Introdução à Compilação. Rio de Janeiro: LTC. 222 páginas. ISBN 978-85-216-0483-9
- ↑ a b Watt, David A.; Brown, Deryck F. (2000). Programming Language Processors in Java (em inglês). Harlow, England: Prentice Hall. p. 27. 436 páginas. ISBN 0-130-25786-9
- ↑ Elder, John (1994). Compiler Conctruction. A Recursive Descent Model (em inglês). 1. Englewood Cliffs, Nova Jersey, EUA: Prentice Hall. p. 7-8. 437 páginas. ISBN 0-13-291139-6
- ↑ Lemone, Karen A. (1992). Fundamentals of Compilers. An Introduction to Computer Language Translation (em inglês). Boca Raton: CRC. 184 páginas. ISBN 0-8493-7341-7
- ↑ a b Wexelblat, Richard L.(Editor) (1981). History of Programming Languages. New York: Academic Press. p. 6-15. 758 páginas. ISBN 0-12-745040-8
- ↑ Bashe, Charles J.; Johnson, Lyle R.; Palmer, John H.; Pugh, Emerson W. (1986). IBM´s Early Computers. Cambridge: MIT Press. p. 333. 716 páginas. ISBN 0-262-02225-7
- ↑ McClelland, William F (abril 1983). «Programming». Annals of The History of Computing (em inglês). 5 (2). Arlington, VA: American Federation of Information Processing Societies. pp. 135–139. ISSN 1058-6180
- ↑ Sammet, Jean E (1969). Programming Languages: History and Fundamentals. Englewood Cliffs, New Jersey: Prentice Hall. p. 5. 785 páginas. ISBN 0-13-729988-5
- ↑ «IP: Os primeiros compiladores COBOL do mundo». interesting-people.org. 12 de Junho de 1997. Consultado em 21 de dezembro de 2011. Arquivado do original em 20 de fevereiro de 2012
- ↑ T. Hart and M. Levin. «O novo compilador, AIM-39 - CSAIL Digital Archive - Artificial Intelligence Laboratory Series» (PDF). publications.ai.mit.edu[ligação inativa]
- ↑ Mak, Ronald (1996). Writing Compilers and Interpreters. An Applied Approach Using C++ (em inglês). Nova Iorque: John Wiley and Sons. p. 1. 838 páginas. ISBN 0-471-11353-0
- ↑ a b c Holmes, Jim (1995). Object-Oriented Compiler Construction (em inglês). Englewood Cliffs, Nova Jersey: Prentice Hall. p. 2-3. 483 páginas. ISBN 0-13-630740-X
- ↑ Sebesta, Robert (2010). Conceitos de Linguagens de Programação 9ª ed. Porto Alegre: Bookman. p. 49-50. 792 páginas. ISBN 978-85-7780-791-8
- ↑ a b Engel, Joshua (1999). Programming for the Java Virtual Machine (em inglês). Reading, Massachusetts: Addison & Wesley. p. 355. 488 páginas. ISBN 0-201-30972-6
- ↑ Louden, Kenneth C. (2004). Compiladores. Princípios e Práticas. São Paulo: Pioneira Thompson Learning. p. 5. 569 páginas. ISBN 85-221-0422-0
- ↑ Levine, John R. (2000). Linkers & Loaders (em inglês). San Francisco: Morgan Kaufmann Publishers. p. 1-3. 256 páginas. ISBN 1-55860-496-0
- ↑ Aho, Alfred V.; Ullman, Jeffrey D. (1972). The Theory of Parsing, Translation, and Compiling, Vol. 1, Parsing (em inglês). 1. Englewood Cliffs, Nova Jersey, EUA: Prentice Hall. p. 59. 542 páginas. ISBN 0-13-914556-7
- ↑ Price, Ana M. A.; Toscano, Simão Sirineo (2000). Implementação de Linguagens de Programação: Compiladores. Série de Livros Didáticos Número 9. Porto Alegre: Sagra Luzzatto. 195 páginas. ISBN 978-85-241-0639-2
- ↑ a b «Compiladores - Página de José Lucas Mourão Rangel Netto». PUC-Rio. Consultado em 21 de junho de 2009. Arquivado do original em 12 de abril de 2009
- ↑ Fischer, Charles N.; LeBlanc, Jr, Richard J. (1991). Crafting a Compiler with C (em inglês). Redwood City, California: Benjamin Cummings Publishing. p. 50. 812 páginas. ISBN 0-8053-2166-7
- ↑ a b Aho, Alfred V.; Sethi, Ravi; Ullman, Jeffrey D. (1986). Compilers: Principles, Techniques and Tools (em inglês). Reading, Massachusetts, EUA: Addison-Wesley. 796 páginas. ISBN 978-0-201-10088-4
- ↑ Delamaro, Marcio (2004). Como Construir um Compilador Utilizando Ferramentas Java. São Paulo: Novatec. p. 4. 308 páginas. ISBN 85-7522-055-1
- ↑ Grune, Dick; Bal, Henri E.; Jacobs, Ceriel J. H.; Langendoen, Koen G (2001). Projeto Moderno de Compiladores. Rio de Janeiro: Campus. ISBN 978-85-352-0876-4
- ↑ Lewis II, P. M.; Rosenkrantz, D,J.; Stearns, R.E. (1978). Compiler Design Theory (em inglês). Reading, Massachusetts: Addison-Wesley. p. 227. 647 páginas. ISBN 0-201-14455-7
- ↑ Alblas, Henk; Nymeyer, Albert (1996). Practice and Principles of Compiler Building with C (em inglês). London: Prentice Hall. p. 30. 427 páginas. ISBN 0-13-349267-2
- ↑ Watson, Des (1989). High-Level Languages and Their Compilers (em inglês). Wokingham, Reino Unido: Addison-Wesley. 337 páginas. ISBN 0-201-18489-3
- ↑ Wilhelm, Reinhard; Maurer, Dieter (1995). Compiler Design (em inglês). Harlow, England: Addison-Wesley. 606 páginas. ISBN 0-201-42290-5
- ↑ a b c d Tremblay, Jean-Paul; Sorenson, Paul G. (1989). The Theory and Practice of Compiler Writing (em inglês). Nova Iorque: McGraw-Hill. 796 páginas. ISBN 0-07-065161-2
- ↑ Pittman, Thomas; Peters, James (1992). The Art of Compiler Design. Theory and Practice (em inglês). Englewood Cliffs, Nova Jersey, EUA: Prentice Hall. 419 páginas. ISBN 0-13-048190-4
- ↑ Pyster, Arthur B. (1988). Compiler Design and Construction. Tools and Techniques (em inglês). Nova Iorque, EUA: Van Nostrand Reinhold Company. p. 8. 267 páginas. ISBN 0-442-27536-6
- ↑ Crespo, Rui Gustavo (1998). Processadores de Linguagens. da Concepção à Implementação. Lisboa, Portugal: IST Press. p. 247. 435 páginas. ISBN 972-8469-01-2
- ↑ a b c Aho, Alfred V.; Ullman, Jeffrey D. (1977). Principles of Compiler Design (em inglês). Reading, Massachusetts, EUA: Addison-Wesley. 604 páginas. ISBN 0-201-00022-9
- ↑ Muchnick, Steven S. (1997). Advanced Compiler Design Implementation (em inglês). San Francisco, California: Morgan Kaufmann Publishers. p. 96. 856 páginas. ISBN 1-55860-320-4
- ↑ Kakde, O. G. (2003). Algorithms for Compiler Design (em inglês). Hingham: Charles River media. 334 páginas. ISBN 1-58450100-6
- ↑ Aho, Alfred V.; Ullman, Jeffrey D. (1972). The Theory of Parsing, Translation, and Compiling, Vol. 2, Compiling (em inglês). 2. Englewood Cliffs, Nova Jersey, EUA: Prentice Hall. p. 720. ISBN 0-13914564-8
- ↑ Waite, William M.; Goos, Gerhard (1984). Compiler Construction. Nova Iorque: Springer-Verlag. p. 302. 446 páginas. ISBN 0-387-90821-8
- ↑ a b Hunter, Robin (1987). Compiladores. Sua Concepção e Programação em Pascal. Lisboa: Presença. p. 259-275. 323 páginas. Depósito legal nº 16057/87
- ↑ Kowaltowski, Tomasz (1983). Implementação de Linguagens de Programação. Rio de Janeiro: Guanabara Dois. p. 170-171. 189 páginas. ISBN 85-7030-009-3
- ↑ a b Holub, Allen I. (1990). Compiler Design in C (em inglês). Englewood Cliffs, Nova Jersey: Prentice Hall. p. 201;348. 924 páginas. ISBN 0-13-155045-4
- ↑ Kakde, O. G. (2003). Algorithms for Compiler Design (em inglês). Hingham: Charles River media. p. 261. 334 páginas. ISBN 1-58450100-6
Bibliografia
[editar | editar código-fonte]- Appel, Andrew W. (1997). Modern Compiler Implementation in C. Basic Techiques (em inglês). [S.l.]: Cambridge University Press. 398 páginas. ISBN 0-521-58653-4
- Brown, P. J. (1979). Writing Interactive Compilers and Interpreters (em inglês). Chichester: John Wiley & Sons. 265 páginas. ISBN 0-471-27609-X
- Kaplan, Randy M. (1994). Constructing Language Processors for Little Languages (em inglês). Nova Iorque: John Wiley & Sons. 452 páginas. ISBN 0-471-59754-6
- Lee, John A. N. (1967). The Anatomy of a Compiler (em inglês). Nova Iorque: Reinhold Publishing Company. 275 páginas. Library of Congress Catalog Card Number: 67-29207
- Metsker, Steven John (2001). Building Parsers with Java (em inglês). Boston: Addison-Wesley. 371 páginas. ISBN 0-201-71962-2
- Ricarte, Ivan (2008). Introdução à Compilação. Rio de Janeiro: Campus, Elsevier. 264 páginas. ISBN 978-85-352-3067-3
- Terry, Patrick D. (1986). Programming Language Translation. A Practical Approach (em inglês). Wokingham: Addison-Wesley. 443 páginas. ISBN 0-201-18040-5
- Wirth, Niklaus (1996). Compiler Construction (em inglês). [S.l.]: Addison-Wesley. ISBN 0-201-40353-6. Consultado em 17 de março de 2007. Arquivado do original em 5 de fevereiro de 2007
Ligações externas
[editar | editar código-fonte]
- «Compilador Educativo Verto»
- «Compiladores livres» (em inglês)