Modello di Markov nascosto
Un modello di Markov nascosto (Hidden Markov Model - HMM) è una catena di Markov in cui gli stati non sono osservabili direttamente. Più precisamente:
- la catena ha un certo numero di stati
- gli stati evolvono secondo una catena di Markov
- ogni stato genera un evento con una certa distribuzione di probabilità che dipende solo dallo stato
- l'evento è osservabile ma lo stato no
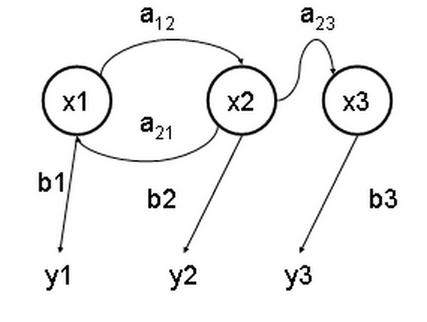
x — stato nascosto
y — uscita osservabile
a — probabilità di transizione
b — probabilità di uscita
I modelli nascosti di Markov sono conosciuti particolarmente per le loro applicazioni nel riconoscimento dello schema temporale dei discorsi parlati, della scrittura a mano, nel riconoscimento di texture e la bioinformatica (per esempio HMMer).
Come usare il modello di Markov nascosto
modificaCi sono 3 problemi canonici connessi con gli HMM:
- Dati i parametri del modello, calcolare la probabilità di una sequenza particolare dell'uscita. Questo problema è risolto dall'algoritmo di forward.
- Dati i parametri del modello, trovare la sequenza più probabile che potrebbe generare una data sequenza dell'uscita. Questo problema è risolto dall'algoritmo di Viterbi (Andrea Viterbi).
- Data una sequenza dell'uscita o un insieme di tali sequenze, trovare l'insieme più probabile per il quale si possano dichiarare le probabilità dell'uscita e di transizione. Questo significa "addestrare" i parametri dell'HMM dato mediante il gruppo dei dati relativi alle sequenze. Questo problema è risolto dall'algoritmo di Baum-Welch.
Esempio concreto
modificaSi considerino due amici, Alice e Bob, che vivono lontani e quotidianamente parlano al telefono di ciò che hanno fatto in giornata. Bob fa tre sole attività: cammina nel parco, fa shopping e pulisce il suo appartamento. La scelta di cosa fare è determinata esclusivamente dal tempo atmosferico. Alice non sa che tempo fa da Bob quando lo chiama, ma sa cosa fa Bob ogni giorno. Sulla base di quello che Bob fa, Alice cerca di indovinare che tempo c'è stato dove vive Bob.
Ci sono due stati, "pioggia" e "sole", ma Alice non può osservarli direttamente, ovvero sono nascosti. Ogni giorno, c'è una certa probabilità che Bob faccia una delle seguenti attività, a seconda del tempo: camminare, fare shopping o pulire. Dato che Bob parla ad Alice delle sue attività, queste sono le osservazioni. L'intero sistema è quello di un modello nascosto di Markov.
Alice sa qual è l'andamento generale del tempo dove vive Bob e quello che piace fare a Bob in media. In altre parole sono noti i parametri del HMM, che possono essere rappresentati come segue nel linguaggio di programmazione Python:
stati = ('Pioggia', 'Sole')
osservazioni = ('camminare', 'shopping', 'pulire')
probabilità_iniziale = {'Pioggia': 0.6, 'Sole': 0.4}
probabilità_transizione = {
'Pioggia' : {'Pioggia': 0.7, 'Sole': 0.3},
'Sole' : {'Pioggia': 0.4, 'Sole': 0.6},
}
probabilità_emissione = {
'Pioggia' : {'camminare': 0.1, 'shopping': 0.4, 'pulire': 0.5},
'Sole' : {'camminare': 0.6, 'shopping': 0.3, 'pulire': 0.1},
}
dove probabilità_iniziale rappresenta la probabilità di ciascuno dei due stati dell'HMM pioggia/sole, quando Bob la chiama (sa, in sostanza, che dove vive Bob il clima è piovoso: al 60%). probabilità_di_transizione rappresenta la probabilità che domani piova/ci sia il sole condizionata dal fatto che oggi piove/c'è il sole. In questo esempio, c'è il 30% di possibilità che il giorno successivo ci sarà il sole se oggi piove. probabilità_di_emissione rappresenta la probabilità che Bob faccia una certa attività delle tre possibili. Se piove, c'è il 50% di probabilità che stia pulendo il suo appartamento; se c'è il sole, c'è il 60% di probabilità che sia fuori a camminare.
Alice può calcolare la sequenza più probabile di stati nascosti in giorni successivi, conoscendo questi tre dati, moltiplicando la probabilità di transizione per la probabilità di emissione di ciascun giorno e sommando i valori.
dove è l'insieme ordinato degli eventi e è l'insieme ordinato degli stati nascosti.
Applicazioni dei modelli nascosti di Markov
modifica- Riconoscimento della parola, di texture e di movimento del corpo, lettura ottica dei caratteri
- Sintesi vocale
- Bioinformatica e studio del genoma
- Predizione delle regioni codificanti nella sequenza del genoma
- Modellizzazione delle famiglie di proteine o delle famiglie geniche
- Previsione degli elementi secondari della struttura dalle sequenze primarie della proteina
Storia
modificaI modelli nascosti di Markov sono stati descritti per la prima volta in una serie di studi statistici di Leonard E. Baum ed altri autori nella seconda metà degli anni sessanta. Una delle prime applicazioni degli HMM era il riconoscimento della parola, a partire dagli anni settanta.
Nella seconda metà degli anni ottanta, si è cominciato ad applicare gli HMM all'analisi delle sequenze biologiche, in particolare quella del DNA. Da allora, questa metodologia è diventata di grande aiuto nel campo della bioinformatica.
Bibliografia
modifica- Stuart J. Russell, Peter Norvig, Capitolo 15 Ragionamento probabilistico nel tempo, in S. Gaburri (a cura di), Intelligenza artificiale. Un approccio moderno (2), 2ª edizione, Pearson Education Italia, 2005, ISBN 978-88-7192-229-4. URL consultato il 1º febbraio 2010.
- (EN) Lawrence R. Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE, 77 (2), p. 257–286, febbraio 1989.
- (EN) Bartolucci F., Farcomeni A. and Pennoni F., Latent Markov Models for Longitudinal Data, Chapman and Hall/CRC, 2013, ISBN 978-14-3981-708-7.
Voci correlate
modificaAltri progetti
modificaWikimedia Commons contiene immagini o altri file sul modello di Markov nascosto
Collegamenti esterni
modifica- Claudia Bertonati, Modello nascosto di Markov, in Enciclopedia della scienza e della tecnica, Istituto dell'Enciclopedia Italiana, 2007-2008.
| Controllo di autorità | LCCN (EN) sh2007000125 · GND (DE) 4352479-5 · J9U (EN, HE) 987007544695605171 |
|---|