Secuencia Kozak
A secuencia Kozak, secuencia consenso Kozak ou consenso Kozak é unha secuencia que aparece no ARNm de eucariotas, ten a secuencia consenso (gcc)gccRccAUGG, e xoga un importante papel na iniciación da tradución de proteínas.[1] Recibe o seu nome de Marilyn Kozak, que deu a coñecer a secuencia.
A secuencia identifícase pola notación (gcc)gccRccAUGG, que resume os datos analizados por Kozak dunha ampla variedade de fontes (699 en total)[2] da seguinte maneira:
- Unha letra en minúscula denota a base nitroxenada máis común nunha posición na que a base pode variar;
- As letras maiúsculas indican bases moi conservadas, é dicir, a secuencia 'AUGG' é constante ou só cambia moi raramente, coa excepción do código 'R' de ambigüidade da IUPAC[3], que indica que nesa posición unha purina (adenina ou guanina) sempre se conserva (e segundo Kozak a adenina é a purina máis frecuente alí).
- A secuencia entre parénteses ((gcc)) ten un significado incerto.
A publicación de Kozak ofrecía datos que se limitaban a un conxunto de vertebrados, como humanos, vacas, gatos, cans, pitos, coellos de indias, hámsteres, ratos, porcos, coellos, ovellas e o anfibio Xenopus.
Introdución
[editar | editar a fonte]Esta secuencia dos ARNm eucarióticos é recoñecida polo ribosoma como o sitio de inicio da tradución, a partir do cal a proteína está codificada no ARNm. O ribosoma necesita esta secuencia (ou unha variación dela) para iniciar a tradución de proteínas. A secuencia Kozak non debe confundirse co sitio de unión ao ribosoma (RBS), que pode ser o extremo 5' cap do ARNm ou un sitio de entrada ao ribosoma interno (IRES).
In vivo, este sitio a miúdo non coincide exactamente en distintos ARNms e a cantidade de proteína sintetizada a partir dun determinado ARNm depende da forza coa que se une a secuencia Kozak.[4] Algúns nucleótidos desta secuencia son máis importantes que outros: o codón AUG é o máis importante porque é o codón de iniciación real, que codifica o aminoácido metionina no extremo N-terminal da proteína. (Máis raramente, o CUG pode usarse como un codón de iniciación, que codifica unha leucina en vez da típica metionina). Ao nucleótido A do codón "AUG" dáselle o número 1. Para que haxa unha secuencia consenso forte, os nucleótidos nas posicións +4 (é dicir G no consenso) e -3 (é dicir, A ou G no consenso) en relación co nucleótido número 1 deben ambas coincidir co consenso (non hai posición 0). Un consenso adecuado ten só un destes sitios, mentres que un consenso feble non ten ningún. O cc en -1 e -2 non están conservados, pero contribúen á forza global da secuencia.[5] Hai tamén evidencias de que unha G na posición -6 é importante na iniciación da tradución.[1]
Hai exemplos in vivo de cada un destes tipos de secuencia Kozak, e problemente evolucionaron como outro mecanismo de regulación xenética. Lmx1b é un exemplo de xene cunha secuencia consenso Kozak feble.[6] Para a iniciación da tradución dese sitio, requírense outras características na secuencia do ARNm para que o ribosoma recoñeza o codón de iniciación.
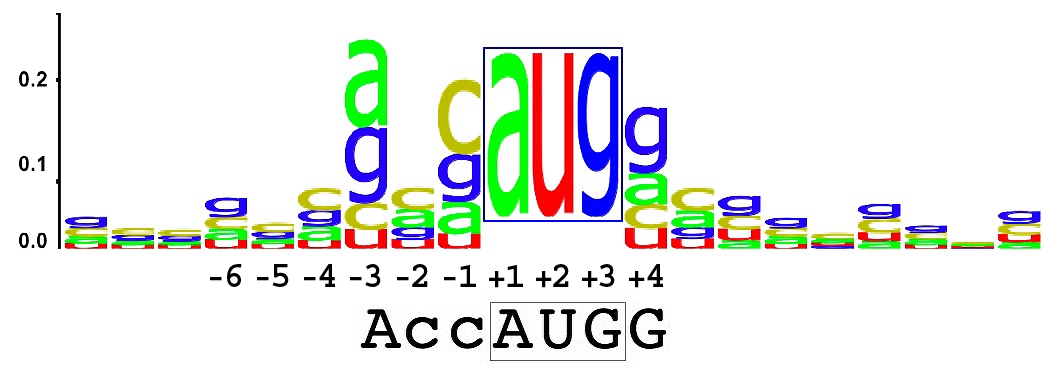
Mutacións
[editar | editar a fonte]As mutacións G—>C na posición -6 do xene da β-globina (β+45; humana) alteran a función fenotípica hematolóxica e biosintética. Esta foi a primeira mutación que se detectou na secuencia Kozak, que se atopou nunha familia do sur de Italia que sufría talasemia intermedia.[1]
Variacións da secuencia consenso
[editar | editar a fonte](gcc)gccRccAUGG
AGNNAUGN
ANNAUGG
ACCAUGG
GACACCAUGG
| Biota | Filo | Secuencias consenso |
|---|---|---|
| Vertebrados | gccRccATGG[2] | |
| mosca da froita (Drosophila spp.) | Artrópodos | cAAaATG[7] |
| Lévedo (Saccharomyces cerevisiae) | Ascomycota | aAaAaAATGTCt[8] |
| Dictyostelium discoideum | Amebozoos | aaaAAAATGRna[9] |
| Ciliados | Cilióforos | nTaAAAATGRct[9] |
| Protozoos da malaria (Plasmodium spp.) | Apicomplexos | taaAAAATGAan[9] |
| Toxoplasma (Toxoplasma gondii) | Apicomplexos | gncAaaATGg[10] |
| Tripanosomátidos | Euglenozoos | nnnAnnATGnC[9] |
| Plantas terrestres | AACAATGGC[11] |
Notas
[editar | editar a fonte]- ↑ 1,0 1,1 1,2 De Angioletti M, Lacerra G, Sabato V, Carestia C (2004). "Beta+45 G --> C: a novel silent beta-thalassaemia mutation, the first in the Kozak sequence". Br J Haematol 124 (2): 224–31. PMID 14687034. doi:10.1046/j.1365-2141.2003.04754.x.
- ↑ 2,0 2,1 Kozak M (1987). "An analysis of 5'-noncoding sequences from 699 vertebrate messenger RNAs". Nucleic Acids Res. 15 (20): 8125–8148. PMC 306349. PMID 3313277. doi:10.1093/nar/15.20.8125.
- ↑ Nomenclature for Incompletely Specified Bases in Nucleic Acid Sequences, NC-IUB, 1984.
- ↑ Kozak M (1984). "Point mutations close to the AUG initiator codon affect the efficiency of translation of rat preproinsulin in vivo". Nature 308 (5956): 241–246. PMID 6700727. doi:10.1038/308241a0.
- ↑ Kozak M (1986). "Point mutations define a sequence flanking the AUG initiator codon that modulates translation by eukaryotic ribosomes". Cell 44 (2): 283–92. PMID 3943125. doi:10.1016/0092-8674(86)90762-2.
- ↑ Dunston JA, Hamlington JD, Zaveri J; et al. (2004). "The human LMX1B gene: transcription unit, promoter, and pathogenic mutations". Genomics 84 (3): 565–76. PMID 15498463. doi:10.1016/j.ygeno.2004.06.002.
- ↑ Cavener DR (1987). "Comparison of the consensus sequence flanking translational start sites in Drosophila and vertebrates". Nucleic Acids Res. 15 (4): 1353–61. PMC 340553. PMID 3822832. doi:10.1093/nar/15.4.1353.
- ↑ Hamilton R, Watanabe CK, de Boer HA (1987). "Compilation and comparison of the sequence context around the AUG startcodons in Saccharomyces cerevisiae mRNAs". Nucleic Acids Res. 15 (8): 3581–93. PMC 340751. PMID 3554144. doi:10.1093/nar/15.8.3581.
- ↑ 9,0 9,1 9,2 9,3 Yamauchi K (1991). "The sequence flanking translational initiation site in protozoa". Nucleic Acids Res. 19 (10): 2715–20. PMC 328191. PMID 2041747. doi:10.1093/nar/19.10.2715.
- ↑ Seeber, F. (1997). "Consensus sequence of translational initiation sites from Toxoplasma gondii genes". Parasitology Research 83 (3): 309–311. PMID 9089733. doi:10.1007/s004360050254.
- ↑ Lütcke HA, Chow KC, Mickel FS, Moss KA, Kern HF, Scheele GA (1987). "Selection of AUG initiation codons differs in plants and animals". EMBO J. 6 (1): 43–8. PMC 553354. PMID 3556162.
Véxase tamén
[editar | editar a fonte]Outros artigos
[editar | editar a fonte]- Secuencia Shine-Dalgarno, sitio de unión ribosómico en ARNm de procariotas
Bibliografía
[editar | editar a fonte]- Kozak M (1990). "Downstream secondary structure facilitates recognition of initiator codons by eukaryotic ribosomes". Proc. Natl. Acad. Sci. U.S.A. 87 (21): 8301–5. PMC 54943. PMID 2236042. doi:10.1073/pnas.87.21.8301.
- Kozak M (1991). "An analysis of vertebrate mRNA sequences: intimations of translational control". J. Cell Biol. 115 (4): 887–903. PMC 2289952. PMID 1955461. doi:10.1083/jcb.115.4.887.
- Kozak M (2002). "Pushing the limits of the scanning mechanism for initiation of translation". Gene 299 (1–2): 1–34. PMID 12459250. doi:10.1016/S0378-1119(02)01056-9.