You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Hi, I attempted to re-write this repo in Keras to migrate it to TF 2.0. In short, I need some help in terms of the training process. My attention loss goes up over time, which reflects on the quality of the Mel output. In the output, the attention line is scattered.
In the Text2Mel model, my attention loss goes up after 4-7 epochs, depending on the hyperparams.
Now the batch size in my model is 8 due to my GPU not being able to fit 32 in one go, but I did try the original model on B=4 and it was totally fine after 20 epochs. I doubt this is to do with Batch size.
Here was the attention loss (moving average) with 'vanilla' hyperparams, or exactly as found in the original repo (except for the Batch size as mentioned earlier). 1638 steps per epoch, 15 epochs, 2500 step 2-sided moving average chart.
Here is after I randomized the batch order between epochs AND increased the LR decay in the 'utils' file. 8 epochs, same moving average.
The increased decay makes the effect appear later in the training, but it still fairly deterministically goes up.
In the grand scheme of things, the overall loss goes down just fine, but this attention loss kind of screws up the output. Here is the total loss after 8 epochs (2nd model):
What results is an output like this (2nd model, 8 epochs). Below is the attention plot in the synthesis stage. Purposefully turned off mono attention for the sake of the visual.
And below are epochs 3,4,5 from the 1st model, which is roughly where it screws up.
Epoch 3:
Epoch 4:
Epoch 5:
What I would like to understand:
Did I copy the model 1 to 1?
What can I try to fix this?
Thanks in advance!
The text was updated successfully, but these errors were encountered:
Hi, I attempted to re-write this repo in Keras to migrate it to TF 2.0. In short, I need some help in terms of the training process. My attention loss goes up over time, which reflects on the quality of the Mel output. In the output, the attention line is scattered.
Here is the repo: https://github.com/dimasikson/dc_tts_keras
In the Text2Mel model, my attention loss goes up after 4-7 epochs, depending on the hyperparams.
Now the batch size in my model is 8 due to my GPU not being able to fit 32 in one go, but I did try the original model on B=4 and it was totally fine after 20 epochs. I doubt this is to do with Batch size.
Here was the attention loss (moving average) with 'vanilla' hyperparams, or exactly as found in the original repo (except for the Batch size as mentioned earlier). 1638 steps per epoch, 15 epochs, 2500 step 2-sided moving average chart.
Here is after I randomized the batch order between epochs AND increased the LR decay in the 'utils' file. 8 epochs, same moving average.
The increased decay makes the effect appear later in the training, but it still fairly deterministically goes up.
In the grand scheme of things, the overall loss goes down just fine, but this attention loss kind of screws up the output. Here is the total loss after 8 epochs (2nd model):
What results is an output like this (2nd model, 8 epochs). Below is the attention plot in the synthesis stage. Purposefully turned off mono attention for the sake of the visual.
And below are epochs 3,4,5 from the 1st model, which is roughly where it screws up.
Epoch 3:

Epoch 4:
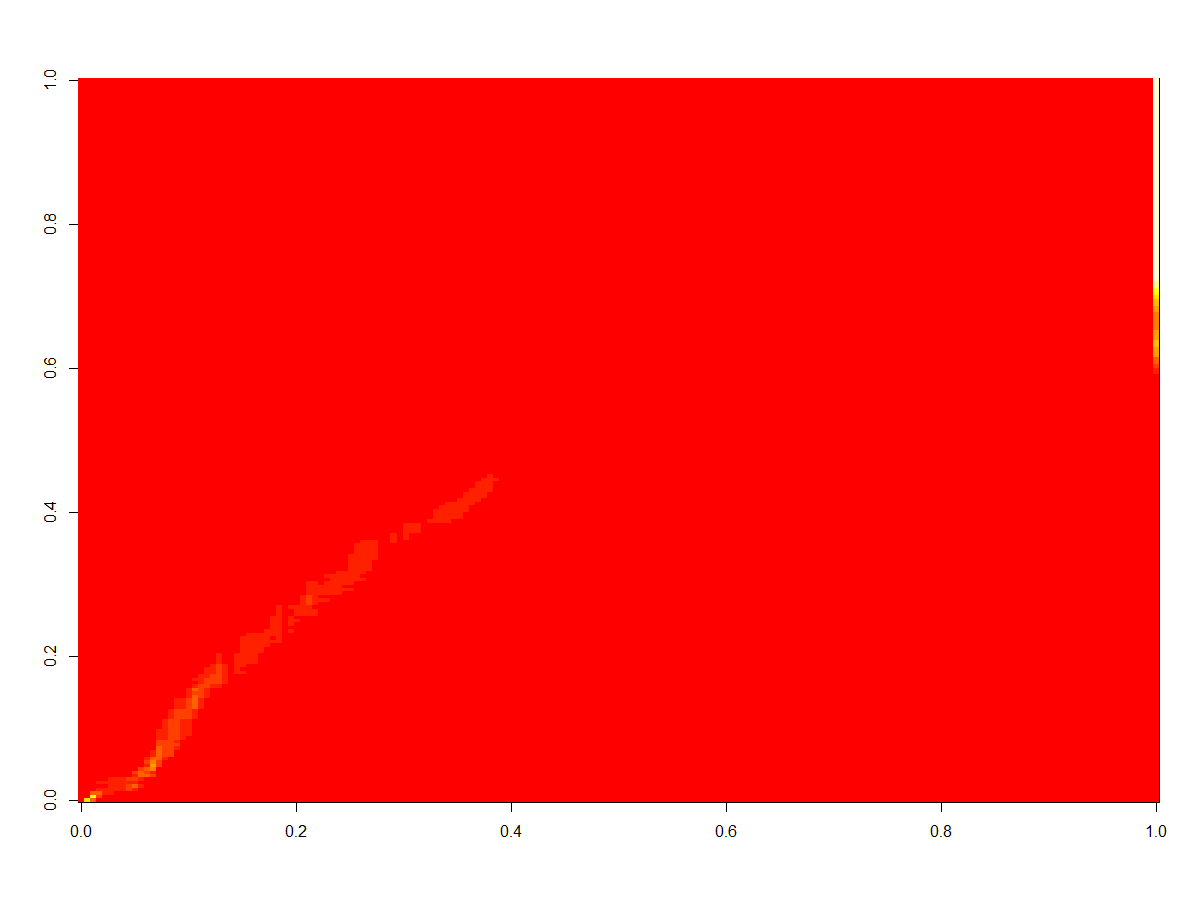
Epoch 5:

What I would like to understand:
Thanks in advance!
The text was updated successfully, but these errors were encountered: