Estimation par noyau
Pour les articles homonymes, voir Parzen et KDE (homonymie).
En statistique, l’estimation par noyau (ou encore méthode de Parzen-Rosenblatt ; en anglais, kernel density estimation ou KDE) est une méthode non-paramétrique d’estimation de la densité de probabilité d’une variable aléatoire. Elle se base sur un échantillon d’une population statistique et permet d’estimer la densité en tout point du support. En ce sens, cette méthode généralise astucieusement la méthode d’estimation par un histogramme.
Définition
modifierSi x1, x2, ..., xN ~ f est un échantillon i.i.d. d'une variable aléatoire, alors l'estimateur non-paramétrique par la méthode du noyau de la densité est :
où K est un noyau (kernel en anglais) et h un paramètre nommé fenêtre, qui régit le degré de lissage de l'estimation. Bien souvent, K est choisi comme la densité d'une fonction gaussienne standard (espérance nulle et variance unitaire) :
Intuition
modifierLa méthode de Parzen est une généralisation de la méthode d'estimation par histogramme. Dans un histogramme, la densité en un point x est estimée par la proportion d'observations x1, x2, ..., xN qui se trouvent à proximité de x. Pour cela, on trace une boîte en x et dont la largeur est gouvernée par un paramètre de lissage h ; on compte ensuite le nombre d'observations qui appartiennent à cette boîte. Cette estimation, qui dépend du paramètre de lissage h, présente de bonnes propriétés statistiques mais est par construction non-continue.
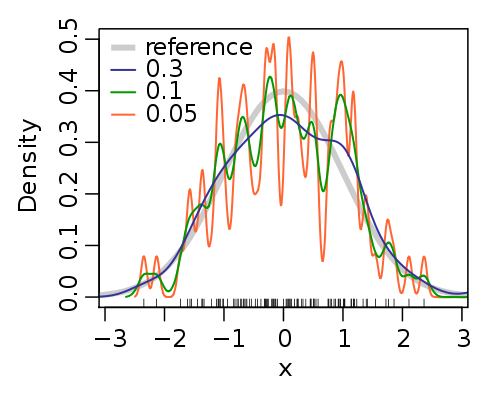
La méthode du noyau consiste à retrouver la continuité : pour cela, on remplace la boîte centrée en x et de largeur h par une gaussienne centrée en x. Plus une observation est proche du point de support x plus la courbe en cloche lui donnera une valeur numérique importante. À l'inverse, les observations trop éloignées de x se voient affecter une valeur numérique négligeable. L'estimateur est formé par la somme (ou plutôt la moyenne) des courbes en cloche. Comme indiqué sur l'image suivante, il est clairement continu.
Propriétés
modifierLa vitesse de convergence de l'erreur quadratique moyenne intégrée, n−4/5 est plus faible que la vitesse typique des méthodes paramétriques, généralement n−1.
L'utilisation pratique de cette méthode requiert deux choses :
- le noyau K (généralement la densité d'une loi statistique) ;
- le paramètre de lissage h.
Si le choix du noyau est réputé comme peu influent sur l'estimateur, il n'en est pas de même pour le paramètre de lissage. Un paramètre trop faible provoque l'apparition de détails artificiels apparaissant sur le graphe de l'estimateur ; à l'inverse, pour une valeur de h trop grande, la majorité des caractéristiques est au contraire effacée. Le choix de h est donc une question centrale dans l'estimation de la densité.
Une façon répandue d'obtenir une valeur de h est de supposer que l'échantillon est distribué selon une loi paramétrique donnée, par exemple selon la loi normale . Alors, on peut prendre : Malheureusement, l'estimation gaussienne n'est pas toujours efficace, par exemple lorsque n est petit.
Une autre façon d'opérer est de chercher à fixer h de manière optimale. Soit R(f , f̂(x)) la fonction de risque de l'espace L2 pour f. Sous des hypothèses faibles sur f et K,
où
La fenêtre optimale est obtenue en minimisant la fonction de risque et vaut :
où
Le paramètre h est toujours proportionnel à n−1/5 : c'est la constante que l'on doit rechercher. La méthode précédente n'est pas opérante dans le sens où c3 dépend de la densité f elle-même, qui est justement inconnue.
Il existe dans la littérature différentes méthodes plus sophistiquées (voir méthode de la validation croisée introduite par Rudemo (1982) et Bowman (1984), qui utilise l'estimateur "leave-one-out").
Implémentations en informatique
modifier- MATLAB : la méthode est codée par la fonction
ksdensity; - R (logiciel) : la méthode est codée par les scripts
densityetkde2det dans le package btb[1] par la fonctionkernelSmoothing; - SAS : il faut utiliser
proc kdepour les densités univariée ou bivariée. - Python : la fonction
gaussian_kdedu packagescipy(modulestats) permet le calcul de densités multi-dimensionnelles. - Apache Spark : la classe
KernelDensity()de la librairie MLlib[2]
Notes et références
modifier- « Btb : Beyond the Border - Kernel Density Estimation for Urban Geography », sur project.org, Comprehensive R Archive Network (CRAN) (consulté le ).
- « Basic Statistics - RDD-based API », sur apache.org (consulté le ).
Bibliographie
modifier- Parzen E. (1962). On estimation of a probability density function and mode, Ann. Math. Stat. 33, pp. 1065-1076.
- (en) Richard O. Duda, Peter E. Hart, David G. Stork, Pattern Classification, Wiley-interscience, (ISBN 0-471-05669-3) [détail des éditions]
- Wasserman, L. (2005). All of statistics : a concise course in statistical inference, Springer Texts in Statistics.
- B.W. Silverman. Density Estimation. London: Chapman and Hall, 1986.