Modelo oculto de Márkov
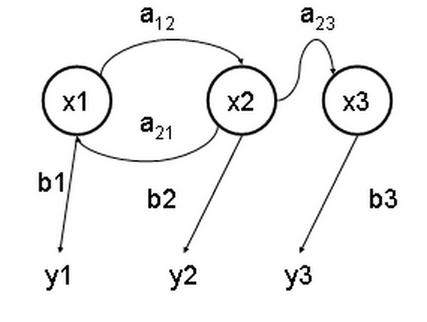
x — estados ocultos
y — salidas observables
a — probabilidades de transición
b — probabilidades de salida
Un modelo oculto de Márkov o HMM (por sus siglas del inglés, Hidden Markov Model) es un modelo estadístico en el que se asume que el sistema a modelar es un proceso de Márkov de parámetros desconocidos. El objetivo es determinar los parámetros desconocidos (u ocultos, de ahí el nombre) de dicha cadena a partir de los parámetros observables. Los parámetros extraídos se pueden emplear para llevar a cabo sucesivos análisis, por ejemplo en aplicaciones de reconocimiento de patrones. Un HMM se puede considerar como la red bayesiana dinámica más simple.
En un modelo de Márkov normal, el estado es visible directamente para el observador, por lo que las probabilidades de transición entre estados son los únicos parámetros. En un modelo oculto de Márkov, el estado no es visible directamente, sino que sólo lo son las variables influidas por el estado. Cada estado tiene una distribución de probabilidad sobre los posibles símbolos de salida. Consecuentemente, la secuencia de símbolos generada por un HMM proporciona cierta información acerca de la secuencia de estados.
Los modelos ocultos de Márkov son especialmente aplicados a reconocimiento de formas temporales, como reconocimiento del habla, de escritura manual, de gestos, etiquetado gramatical o en bioinformática. En el reconocimiento de voz se emplea para modelar una frase completa, una palabra, un fonema o trifonema en el modelo acústico. Por ejemplo la palabra "gato" puede estar formada por dos HMM para los dos trifonemas que la componen /gat/ y /ato/
Historia
[editar]Los modelos ocultos de Markov fueron descritos por primera vez en una serie de artículos estadísticos por Leonard E. Baum y otros autores en la segunda mitad de la década de 1960. Una de las primeras aplicaciones de HMM fue reconocimiento del habla, comenzando en la mitad de la década de 1970.[1]
En la segunda mitad de la década de 1980, los HMMs comenzaron a ser aplicados al análisis de secuencias biológicas, en particular de ADN. Desde entonces, se han hecho ubicuos en el campo de la bioinformática.[2]
Arquitectura de un modelo oculto de Márkov
[editar]El diagrama que se encuentra más abajo muestra la arquitectura general de un HMM. Cada óvalo representa una variable aleatoria que puede tomar determinados valores. La variable aleatoria es el valor de la variable oculta en el instante de tiempo . La variable aleatoria es el valor de la variable observada en el mismo instante de tiempo . Las flechas indican dependencias condicionales.
Del diagrama queda claro que el valor de la variable oculta (en el instante ) solo depende del valor de la variable oculta (en el instante ). A esto se le llama propiedad de Márkov. De forma similar, el valor de la variable observada solo depende del valor de la variable oculta (ambas en el instante ).
Probabilidad de una secuencia observada
[editar]La probabilidad de observar la secuencia de longitud está dada por
donde la sumatoria se extiende sobre todas las secuencias de nodos ocultos El cálculo por fuerza bruta de es impráctico para la mayoría de los problemas reales, dado que el número de secuencias de nodos ocultos será extremadamente alto en tal caso. Sin embargo, el cálculo puede acelerarse notoriamente usando un algoritmo conocido como el procedimiento de avance-retroceso.[3]
Definición formal de un Modelo Oculto de Márkov
[editar]Una notación habitual de un MOM es la representación como una tupla :
- El conjunto de estados . El estado inicial se denota como . En el caso de la etiquetación categorial, cada valor de hace referencia a la posición de la palabra en la oración.
- El conjunto de posibles valores observables en cada estado. es el número de palabras posibles y cada hace referencia a una palabra diferente.
- Las probabilidades iniciales , donde es la probabilidad de que el primer estado sea el estado .
- El conjunto de probabilidades de transiciones entre estados.
- , es decir, es la probabilidad de estar en el estado en el instante si en el instante anterior se estaba en el estado .
- El conjunto de probabilidades de las observaciones.
- , es decir, la probabilidad de observar cuando se está en el estado en el instante .
La secuencia de observables se denota como un conjunto .
Uso de modelos ocultos de Márkov
[editar]Existen tres problemas canónicos asociados con HMM:
- Dados los parámetros del modelo, compútese la probabilidad de una secuencia de salida en particular. Este problema se resuelve con el algoritmo de avance-retroceso.
- Dados los parámetros del modelo, encuéntrese la secuencia más probable de estados ocultos que puedan haber generado una secuencia de salida dada. Este problema se resuelve con el algoritmo de Viterbi.
- Dada una secuencia de salida o un conjunto de tales secuencias, encuéntrese el conjunto de estados de transición y probabilidades de salida más probables. En otras palabras, entrénense a los parámetros del HMM dada una secuencia de datos. Este problema se resuelve con el algoritmo de Baum-Welch.
Ejemplo de utilización
[editar]Imagínese que tiene un amigo que vive lejos y con quien habla a diario por teléfono acerca de lo que hizo durante el día. A su amigo le interesan tres actividades: caminar por la plaza, salir de compras y limpiar su departamento. Lo que su amigo hace depende exclusivamente del estado del tiempo en ese día. Usted no tiene información clara acerca del estado del tiempo donde su amigo vive, pero conoce tendencias generales. Basándose en lo que su amigo le dice que hizo en el día, usted intenta adivinar el estado del tiempo.
Supóngase que el estado del tiempo se comporta como una cadena de Márkov discreta. Existen dos estados, "Lluvioso" y "Soleado", pero usted no los puede observar directamente, es decir, están ocultos. Existe también una cierta posibilidad de que su amigo haga una de sus actividades cada día, dependiendo del estado del tiempo: "caminar", "comprar" o "limpiar". Dado que su amigo le cuenta sus actividades del día, esas son las observaciones. El sistema completo es un modelo oculto de Márkov.
Usted conoce las tendencias generales del tiempo en el área y lo que a su amigo le gusta hacer. En otras palabras, los parámetros del HMM son conocidos. Pueden escribirse usando el lenguaje de programación Python:
estados = ('Lluvioso', 'Soleado')
observaciones = ('caminar', 'comprar', 'limpiar')
probabilidad_inicial = {'Lluvioso': 0.6, 'Soleado': 0.4}
probabilidad_transicion = {
'Lluvioso' : {'Lluvioso': 0.7, 'Soleado': 0.3},
'Soleado' : {'Lluvioso': 0.4, 'Soleado': 0.6},
}
probabilidad_emision = {
'Lluvioso' : {'caminar': 0.1, 'comprar': 0.4, 'limpiar': 0.5},
'Soleado' : {'caminar': 0.6, 'comprar': 0.3, 'limpiar': 0.1},
}
En esta porción de código se tiene:
La probabilidad_inicial que representa el estado en el que usted cree que se encuentra el HMM la primera vez que su amigo lo llama (es decir, sabe que es un poco más probable que esté lluvioso). La distribución de probabilidades que se usó aquí no es la de equilibrio, que es (dadas las probabilidades de transición) aproximadamente {'Lluvioso': 0.571, 'Soleado': 0.429}.
La probabilidad_transicion representa el cambio del tiempo en la cadena de Márkov por detrás del modelo. En este ejemplo, hay un 30% de probabilidad de que mañana esté soleado si hoy llovió.
La probabilidad_emision representa con cuanta probabilidad su amigo realiza una actividad determinada cada día. Si llueve, hay un 50% de probabilidad de que esté limpiando su casa; si hay sol, hay un 60% de probabilidades de que haya salido a caminar.
Aplicaciones de modelos ocultos de Márkov
[editar]- Criptoanálisis
- Reconocimiento del habla, de gestos y de movimientos corporales, reconocimiento óptico de caracteres
- Traducción automática
- Seguimiento de partituras musicales[4]
- Bioinformática y Genómica
- predicción de regiones que codifican proteínas dentro de genomas
- modelado de familias de secuencias de proteína o ADN relacionado
- predicción de elementos de estructura secundaria en secuencias primarias de proteína
Notas
[editar]Véase también
[editar]- Andréi Márkov
- Algoritmo de Baum-Welch
- Inferencia bayesiana
- Estimación estadística
- Algoritmo de Viterbi
- Modelo oculto de Márkov jerárquico
- Modelo oculto de Márkov por capas
- Modelo oculto de semi-Márkov
- Modelo de Márkov de orden variable
Enlaces externos
[editar]- Información general de los HMM
- Hidden Markov Model (HMM) Toolbox para Matlab (por Kevin Murphy)
- Hidden Markov Model Toolkit (HTK) (un toolkit portable para construcción y manipulación de modelos ocultos de Márkov)
- Hidden Markov Models (presentación con matemática básica)
- GHMM Library (página inicial del proyecto GHMM Library)
- Jahmm Java Library (biblioteca Java y aplicaciones gráficas asociadas)
- Tutorial paso a paso de HMMs (University of Leeds)
- Software para modelos de Márkov Models y procesos (TreeAge Software)
- Hidden Markov Models (por Narada Warakagoda)
- HMM y otros programas estadísticos (Implementación de algoritmos de HMMs en C)
| Control de autoridades |
|
|---|
Datos: Q176769
Multimedia: Hidden Markov Model / Q176769