Distributed version control
In software development, distributed version control (also known as distributed revision control) is a form of version control in which the complete codebase, including its full history, is mirrored on every developer's computer.[1] Compared to centralized version control (cf. monorepo), this enables automatic management branching and merging, speeds up most operations (except pushing and fetching), improves the ability to work offline, and does not rely on a single location for backups.[1][2][3] Git, the world's most popular version control system,[4] is a distributed version control system.
In 2010, software development author Joel Spolsky described distributed version control systems as "possibly the biggest advance in software development technology in the [past] ten years".[2]
Distributed vs. centralized
[edit]Distributed version control systems (DVCS) use a peer-to-peer approach to version control, as opposed to the client–server approach of centralized systems. Distributed revision control synchronizes repositories by transferring patches from peer to peer. There is no single central version of the codebase; instead, each user has a working copy and the full change history.
Advantages of DVCS (compared with centralized systems) include:
- Allows users to work productively when not connected to a network.
- Common operations (such as commits, viewing history, and reverting changes) are faster for DVCS, because there is no need to communicate with a central server.[5] With DVCS, communication is necessary only when sharing changes among other peers.
- Allows private work, so users can use their changes even for early drafts they do not want to publish.[citation needed]
- Working copies effectively function as remote backups, which avoids relying on one physical machine as a single point of failure.[5]
- Allows various development models to be used, such as using development branches or a Commander/Lieutenant model.[6]
- Permits centralized control of the "release version" of the project[citation needed]
- On FOSS software projects it is much easier to create a project fork from a project that is stalled because of leadership conflicts or design disagreements.
Disadvantages of DVCS (compared with centralized systems) include:
- Initial checkout of a repository is slower as compared to checkout in a centralized version control system, because all branches and revision history are copied to the local machine by default.
- The lack of locking mechanisms that is part of most centralized VCS and still plays an important role when it comes to non-mergeable binary files such as graphic assets or too complex single file binary or XML packages (e.g. office documents, PowerBI files, SQL Server Data Tools BI packages, etc.).[citation needed]
- Additional storage required for every user to have a complete copy of the complete codebase history.[7]
- Increased exposure of the code base since every participant has a locally vulnerable copy.[citation needed]
Some originally centralized systems now offer some distributed features. Team Foundation Server and Visual Studio Team Services now host centralized and distributed version control repositories via hosting Git.
Similarly, some distributed systems now offer features that mitigate the issues of checkout times and storage costs, such as the Virtual File System for Git developed by Microsoft to work with very large codebases,[8] which exposes a virtual file system that downloads files to local storage only as they are needed.
Work model
[edit]This section needs expansion. You can help by adding to it. (June 2008) |
The distributed model is generally better suited for large projects with partly independent developers, such as the Linux kernel project, because developers can work independently and submit their changes for merge (or rejection). This flexibility allows adopting custom source code contribution workflows, such as the integrator workflow, which is the most widely used. Unlike the centralized model where developers must serialize their work to avoid problems with different versions, in the distributed model, developers can clone the entire history of the code to their local machines. They commit their changes to their local repositories first, creating 'change sets,' before pushing them to the master repository. This approach enables developers to work locally and disconnected, making it more convenient for distributed teams.[9]
Central and branch repositories
[edit]In a truly distributed project, such as Linux, every contributor maintains their own version of the project, with different contributors hosting their own respective versions and pulling in changes from other users as needed, resulting in a general consensus emerging from multiple different nodes. This also makes the process of "forking" easy, as all that is required is one contributor stop accepting pull requests from other contributors and letting the codebases gradually grow apart.
This arrangement, however, can be difficult to maintain, resulting in many projects choosing to shift to a paradigm in which one contributor is the universal "upstream", a repository from whom changes are almost always pulled. Under this paradigm, development is somewhat recentralized, as every project now has a central repository that is informally considered as the official repository, managed by the project maintainers collectively. While distributed version control systems make it easy for new developers to "clone" a copy of any other contributor's repository, in a central model, new developers always clone the central repository to create identical local copies of the code base. Under this system, code changes in the central repository are periodically synchronized with the local repository, and once the development is done, the change should be integrated into the central repository as soon as possible.
Organizations utilizing this centralize pattern often choose to host the central repository on a third party service like GitHub, which offers not only more reliable uptime than self-hosted repositories, but can also add centralized features like issue trackers and continuous integration.
Pull requests
[edit]Contributions to a source code repository that uses a distributed version control system are commonly made by means of a pull request, also known as a merge request.[10] The contributor requests that the project maintainer pull the source code change, hence the name "pull request". The maintainer has to merge the pull request if the contribution should become part of the source base.[11]
The developer creates a pull request to notify maintainers of a new change; a comment thread is associated with each pull request. This allows for focused discussion of code changes. Submitted pull requests are visible to anyone with repository access. A pull request can be accepted or rejected by maintainers.[12]
Once the pull request is reviewed and approved, it is merged into the repository. Depending on the established workflow, the code may need to be tested before being included into official release. Therefore, some projects contain a special branch for merging untested pull requests.[11][13] Other projects run an automated test suite on every pull request, using a continuous integration tool, and the reviewer checks that any new code has appropriate test coverage.
History
[edit]The first open-source DVCS systems included Arch, Monotone, and Darcs. However, open source DVCSs were never very popular until the release of Git and Mercurial.
BitKeeper was used in the development of the Linux kernel from 2002 to 2005.[14] The development of Git, now the world's most popular version control system,[4] was prompted by the decision of the company that made BitKeeper to rescind the free license that Linus Torvalds and some other Linux kernel developers had previously taken advantage of.[14]
See also
[edit]- Version control
- List of version-control software
- Comparison of version-control software
- Category:Software using distributed version control
- Repository clone
- Git, an open source DVCS developed for Linux Kernel development
- Mercurial, a cross-platform system similar to Git
- Fossil, a distributed version control system, bug tracking system and wiki software
- BitKeeper
- GNU Bazaar
- Darcs
- Concurrent Versions System, a predecessor of distributed version control systems
- TortoiseHg, a graphical interface for Mercurial
- Code Co-op, a peer-to-peer version control system
References
[edit]- ^ a b Chacon, Scott; Straub, Ben (2014). "About version control". Pro Git (2nd ed.). Apress. Chapter 1.1. Retrieved 4 June 2019.
- ^ a b Spolsky, Joel (17 March 2010). "Distributed Version Control Is Here to Stay, Baby". Joel on Software. Retrieved 4 June 2019.
- ^ "Intro to Distributed Version Control (Illustrated)". www.betterexplained.com. Retrieved 7 January 2018.
- ^ a b "Version Control Systems Popularity in 2016". www.rhodecode.com. Retrieved 7 January 2018.
- ^ a b O'Sullivan, Bryan. "Distributed revision control with Mercurial". Retrieved July 13, 2007.
- ^ Chacon, Scott; Straub, Ben (2014). "Distributed workflows". Pro Git (2nd ed.). Apress. Chapter 5.1.
- ^ "What is version control: centralized vs. DVCS". www.atlassian.com. 14 February 2012. Retrieved 7 January 2018.
- ^ Jonathan Allen (2017-02-08). "How Microsoft Solved Git's Problem with Large Repositories". Retrieved 2019-08-06.
- ^ Upadhaye, Annu (22 Feb 2023). "Centralized vs Distributed Version Control". GFG. Retrieved 4 April 2024.
- ^ Sijbrandij, Sytse (29 September 2014). "GitLab Flow". GitLab. Retrieved 4 August 2018.
- ^ a b Johnson, Mark (8 November 2013). "What is a pull request?". Oaawatch. Retrieved 27 March 2016.
- ^ "Using pull requests". GitHub. Retrieved 27 March 2016.
- ^ "Making a Pull Request". Atlassian. Retrieved 27 March 2016.
- ^ a b McAllister, Neil. "Linus Torvalds' BitKeeper blunder". InfoWorld. Retrieved 2017-03-19.
External links
[edit]- Essay on various revision control systems, especially the section "Centralized vs. Decentralized SCM"
- Introduction to distributed version control systems - IBM Developer Works article
Years, where available, indicate the date of first stable release. Systems with names in italics are no longer maintained or have planned end-of-life dates. | ||||||
| Local only |
| 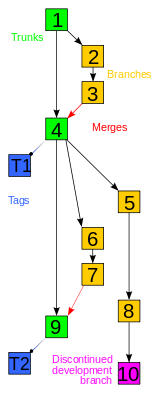 | ||||
| Client–server |
| |||||
| Distributed |
| |||||
| Concepts | ||||||