Differential privacy
Differential privacy (DP) is a mathematically rigorous framework for releasing statistical information about datasets while protecting the privacy of individual data subjects. It enables a data holder to share aggregate patterns of the group while limiting information that is leaked about specific individuals.[1][2] This is done by injecting carefully calibrated noise into statistical computations such that the utility of the statistic is preserved while provably limiting what can be inferred about any individual in the dataset.
Another way to describe differential privacy is as a constraint on the algorithms used to publish aggregate information about a statistical database which limits the disclosure of private information of records in the database. For example, differentially private algorithms are used by some government agencies to publish demographic information or other statistical aggregates while ensuring confidentiality of survey responses, and by companies to collect information about user behavior while controlling what is visible even to internal analysts.
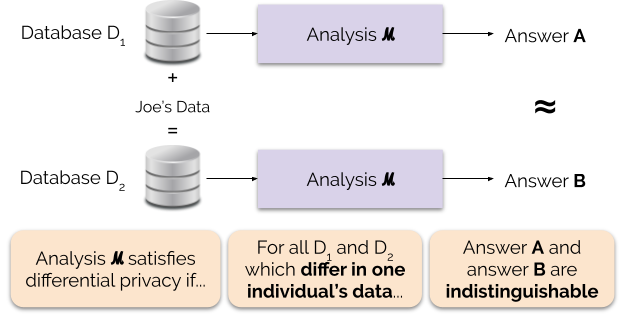
Roughly, an algorithm is differentially private if an observer seeing its output cannot tell whether a particular individual's information was used in the computation. Differential privacy is often discussed in the context of identifying individuals whose information may be in a database. Although it does not directly refer to identification and reidentification attacks, differentially private algorithms provably resist such attacks.[3]
ε-differential privacy
[edit]
The 2006 Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam D. Smith article[3] introduced the concept of ε-differential privacy, a mathematical definition for the privacy loss associated with any data release drawn from a statistical database.[4] (Here, the term statistical database means a set of data that are collected under the pledge of confidentiality for the purpose of producing statistics that, by their production, do not compromise the privacy of those individuals who provided the data.)
The definition of ε-differential privacy requires that a change to one entry in a database only creates a small change in the probability distribution of the outputs of measurements, as seen by the attacker.[3] The intuition for the definition of ε-differential privacy is that a person's privacy cannot be compromised by a statistical release if their data are not in the database.[5] In differential privacy, each individual is given roughly the same privacy that would result from having their data removed.[5] That is, the statistical functions run on the database should not be substantially affected by the removal, addition, or change of any individual in the data.[5]
How much any individual contributes to the result of a database query depends in part on how many people's data are involved in the query. If the database contains data from a single person, that person's data contributes 100%. If the database contains data from a hundred people, each person's data contributes just 1%. The key insight of differential privacy is that as the query is made on the data of fewer and fewer people, more noise needs to be added to the query result to produce the same amount of privacy. Hence the name of the 2006 paper, "Calibrating noise to sensitivity in private data analysis."[citation needed]
Definition
[edit]Let ε be a positive real number and be a randomized algorithm that takes a dataset as input (representing the actions of the trusted party holding the data). Let denote the image of .
The algorithm is said to provide (ε, δ)-differential privacy if, for all datasets and that differ on a single element (i.e., the data of one person), and all subsets of :
where the probability is taken over the randomness used by the algorithm.[6] This definition is sometimes called "approximate differential privacy", with "pure differential privacy" being a special case when . In the latter case, the algorithm is commonly said to satisfy ε-differential privacy (i.e., omitting ).[citation needed]
Differential privacy offers strong and robust guarantees that facilitate modular design and analysis of differentially private mechanisms due to its composability, robustness to post-processing, and graceful degradation in the presence of correlated data.[citation needed]
Example
[edit]According to this definition, differential privacy is a condition on the release mechanism (i.e., the trusted party releasing information about the dataset) and not on the dataset itself. Intuitively, this means that for any two datasets that are similar, a given differentially private algorithm will behave approximately the same on both datasets. The definition gives a strong guarantee that presence or absence of an individual will not affect the final output of the algorithm significantly.
For example, assume we have a database of medical records where each record is a pair (Name, X), where is a Boolean denoting whether a person has diabetes or not. For example:
| Name | Has Diabetes (X) |
|---|---|
| Ross | 1 |
| Monica | 1 |
| Joey | 0 |
| Phoebe | 0 |
| Chandler | 1 |
| Rachel | 0 |
Now suppose a malicious user (often termed an adversary) wants to find whether Chandler has diabetes or not. Suppose he also knows in which row of the database Chandler resides. Now suppose the adversary is only allowed to use a particular form of query that returns the partial sum of the first rows of column in the database. In order to find Chandler's diabetes status the adversary executes and , then computes their difference. In this example, and , so their difference is 1. This indicates that the "Has Diabetes" field in Chandler's row must be 1. This example highlights how individual information can be compromised even without explicitly querying for the information of a specific individual.
Continuing this example, if we construct by replacing (Chandler, 1) with (Chandler, 0) then this malicious adversary will be able to distinguish from by computing for each dataset. If the adversary were required to receive the values via an -differentially private algorithm, for a sufficiently small , then he or she would be unable to distinguish between the two datasets.
Composability and robustness to post processing
[edit]Composability refers to the fact that the joint distribution of the outputs of (possibly adaptively chosen) differentially private mechanisms satisfies differential privacy.[3]
- Sequential composition. If we query an ε-differential privacy mechanism times, and the randomization of the mechanism is independent for each query, then the result would be -differentially private. In the more general case, if there are independent mechanisms: , whose privacy guarantees are differential privacy, respectively, then any function of them: is -differentially private.[7]
- Parallel composition. If the previous mechanisms are computed on disjoint subsets of the private database then the function would be -differentially private instead.[7]
The other important property for modular use of differential privacy is robustness to post processing. This is defined to mean that for any deterministic or randomized function defined over the image of the mechanism , if satisfies ε-differential privacy, so does .[3]
The property of composition permits modular construction and analysis of differentially private mechanisms[3] and motivates the concept of the privacy loss budget.[citation needed] If all elements that access sensitive data of a complex mechanisms are separately differentially private, so will be their combination, followed by arbitrary post-processing.[3]
Group privacy
[edit]In general, ε-differential privacy is designed to protect the privacy between neighboring databases which differ only in one row. This means that no adversary with arbitrary auxiliary information can know if one particular participant submitted their information. However this is also extendable.[3] We may want to protect databases differing in rows, which amounts to an adversary with arbitrary auxiliary information knowing if particular participants submitted their information. This can be achieved because if items change, the probability dilation is bounded by instead of ,[8] i.e., for D1 and D2 differing on items:Thus setting ε instead to achieves the desired result (protection of items).[3] In other words, instead of having each item ε-differentially private protected, now every group of items is ε-differentially private protected (and each item is -differentially private protected).[3]
Hypothesis testing interpretation
[edit]One can think of differential privacy as bounding the error rates in a hypothesis test. Consider two hypotheses:
- : The individual's data is not in the dataset.
- : The individual's data is in the dataset.
Then, there are two error rates:
- False Positive Rate (FPR):
- False Negative Rate (FNR):
Ideal protection would imply that both error rates are equal, but for a fixed (ε, δ) setting, an attacker can achieve the following rates:[9]
ε-differentially private mechanisms
[edit]Since differential privacy is a probabilistic concept, any differentially private mechanism is necessarily randomized. Some of these, like the Laplace mechanism, described below, rely on adding controlled noise to the function that we want to compute. Others, like the exponential mechanism[10] and posterior sampling[11] sample from a problem-dependent family of distributions instead.
An important definition with respect to ε-differentially private mechanisms is sensitivity.[3] Let be a positive integer, be a collection of datasets, and be a function. One definition of the sensitivity of a function, denoted , can be defined by:[3]where the maximum is over all pairs of datasets and in differing in at most one element and denotes the L1 norm.[3] In the example of the medical database below, if we consider to be the function , then the sensitivity of the function is one, since changing any one of the entries in the database causes the output of the function to change by either zero or one. This can be generalized to other metric spaces (measures of distance), and must be to make certain differentially private algorithms work, including adding noise from the Gaussian distribution (which requires the L2 norm) instead of the Laplace distribution.[3]
There are techniques (which are described below) using which we can create a differentially private algorithm for functions, with parameters that vary depending on their sensitivity.[3]
Laplace mechanism
[edit]This section may be too technical for most readers to understand. (July 2024) |

The Laplace mechanism adds Laplace noise (i.e. noise from the Laplace distribution, which can be expressed by probability density function , which has mean zero and standard deviation ). Now in our case we define the output function of as a real valued function (called as the transcript output by ) as where and is the original real valued query/function we planned to execute on the database. Now clearly can be considered to be a continuous random variable, where
which is at most . We can consider to be the privacy factor . Thus follows a differentially private mechanism (as can be seen from the definition above). If we try to use this concept in our diabetes example then it follows from the above derived fact that in order to have as the -differential private algorithm we need to have . Though we have used Laplace noise here, other forms of noise, such as the Gaussian Noise, can be employed, but they may require a slight relaxation of the definition of differential privacy.[8]
Randomized response
[edit]A simple example, especially developed in the social sciences,[12] is to ask a person to answer the question "Do you own the attribute A?", according to the following procedure:
- Toss a coin.
- If heads, then toss the coin again (ignoring the outcome), and answer the question honestly.
- If tails, then toss the coin again and answer "Yes" if heads, "No" if tails.
(The seemingly redundant extra toss in the first case is needed in situations where just the act of tossing a coin may be observed by others, even if the actual result stays hidden.) The confidentiality then arises from the refutability of the individual responses.
But, overall, these data with many responses are significant, since positive responses are given to a quarter by people who do not have the attribute A and three-quarters by people who actually possess it. Thus, if p is the true proportion of people with A, then we expect to obtain (1/4)(1-p) + (3/4)p = (1/4) + p/2 positive responses. Hence it is possible to estimate p.
In particular, if the attribute A is synonymous with illegal behavior, then answering "Yes" is not incriminating, insofar as the person has a probability of a "Yes" response, whatever it may be.
Although this example, inspired by randomized response, might be applicable to microdata (i.e., releasing datasets with each individual response), by definition differential privacy excludes microdata releases and is only applicable to queries (i.e., aggregating individual responses into one result) as this would violate the requirements, more specifically the plausible deniability that a subject participated or not.[13][14]
Stable transformations
[edit]A transformation is -stable if the Hamming distance between and is at most -times the Hamming distance between and for any two databases .[citation needed] If there is a mechanism that is -differentially private, then the composite mechanism is -differentially private.[7]
This could be generalized to group privacy, as the group size could be thought of as the Hamming distance between and (where contains the group and does not). In this case is -differentially private.[citation needed]
Research
[edit]Early research leading to differential privacy
[edit]In 1977, Tore Dalenius formalized the mathematics of cell suppression.[15] Tore Dalenius was a Swedish statistician who contributed to statistical privacy through his 1977 paper that revealed a key point about statistical databases, which was that databases should not reveal information about an individual that is not otherwise accessible.[16] He also defined a typology for statistical disclosures.[4]
In 1979, Dorothy Denning, Peter J. Denning and Mayer D. Schwartz formalized the concept of a Tracker, an adversary that could learn the confidential contents of a statistical database by creating a series of targeted queries and remembering the results.[17] This and future research showed that privacy properties in a database could only be preserved by considering each new query in light of (possibly all) previous queries. This line of work is sometimes called query privacy, with the final result being that tracking the impact of a query on the privacy of individuals in the database was NP-hard.[citation needed]
21st century
[edit]In 2003, Kobbi Nissim and Irit Dinur demonstrated that it is impossible to publish arbitrary queries on a private statistical database without revealing some amount of private information, and that the entire information content of the database can be revealed by publishing the results of a surprisingly small number of random queries—far fewer than was implied by previous work.[18] The general phenomenon is known as the Fundamental Law of Information Recovery, and its key insight, namely that in the most general case, privacy cannot be protected without injecting some amount of noise, led to development of differential privacy.[citation needed]
In 2006, Cynthia Dwork, Frank McSherry, Kobbi Nissim and Adam D. Smith published an article[3] formalizing the amount of noise that needed to be added and proposing a generalized mechanism for doing so.[citation needed] This paper also created the first formal definition of differential privacy.[4] Their work was a co-recipient of the 2016 TCC Test-of-Time Award[19] and the 2017 Gödel Prize.[20]
Since then, subsequent research has shown that there are many ways to produce very accurate statistics from the database while still ensuring high levels of privacy.[1]
Adoption in real-world applications
[edit]To date there are over 12 real-world deployments of differential privacy, the most noteworthy being:
- 2008: U.S. Census Bureau, for showing commuting patterns.[21]
- 2014: Google's RAPPOR, for telemetry such as learning statistics about unwanted software hijacking users' settings.[22][23]
- 2015: Google, for sharing historical traffic statistics.[24]
- 2016: Apple iOS 10, for use in Intelligent personal assistant technology.[25]
- 2017: Microsoft, for telemetry in Windows.[26]
- 2020: Social Science One and Facebook, a 55 trillion cell dataset for researchers to learn about elections and democracy.[27][28]
- 2021: The US Census Bureau uses differential privacy to release redistricting data from the 2020 Census.[29]
Public purpose considerations
[edit]There are several public purpose considerations regarding differential privacy that are important to consider, especially for policymakers and policy-focused audiences interested in the social opportunities and risks of the technology:[30]
- Data utility and accuracy. The main concern with differential privacy is the trade-off between data utility and individual privacy. If the privacy loss parameter is set to favor utility, the privacy benefits are lowered (less “noise” is injected into the system); if the privacy loss parameter is set to favor heavy privacy, the accuracy and utility of the dataset are lowered (more “noise” is injected into the system). It is important for policymakers to consider the trade-offs posed by differential privacy in order to help set appropriate best practices and standards around the use of this privacy preserving practice, especially considering the diversity in organizational use cases. It is worth noting, though, that decreased accuracy and utility is a common issue among all statistical disclosure limitation methods and is not unique to differential privacy. What is unique, however, is how policymakers, researchers, and implementers can consider mitigating against the risks presented through this trade-off.
- Data privacy and security. Differential privacy provides a quantified measure of privacy loss and an upper bound and allows curators to choose the explicit trade-off between privacy and accuracy. It is robust to still unknown privacy attacks. However, it encourages greater data sharing, which if done poorly, increases privacy risk. Differential privacy implies that privacy is protected, but this depends very much on the privacy loss parameter chosen and may instead lead to a false sense of security. Finally, though it is robust against unforeseen future privacy attacks, a countermeasure may be devised that we cannot predict.
Attacks in practice
[edit]Because differential privacy techniques are implemented on real computers, they are vulnerable to various attacks not possible to compensate for solely in the mathematics of the techniques themselves. In addition to standard defects of software artifacts that can be identified using testing or fuzzing, implementations of differentially private mechanisms may suffer from the following vulnerabilities:
- Subtle algorithmic or analytical mistakes.[31][32]
- Timing side-channel attacks.[33] In contrast with timing attacks against implementations of cryptographic algorithms that typically have low leakage rate and must be followed with non-trivial cryptanalysis, a timing channel may lead to a catastrophic compromise of a differentially private system, since a targeted attack can be used to exfiltrate the very bit that the system is designed to hide.
- Leakage through floating-point arithmetic.[34] Differentially private algorithms are typically presented in the language of probability distributions, which most naturally lead to implementations using floating-point arithmetic. The abstraction of floating-point arithmetic is leaky, and without careful attention to details, a naive implementation may fail to provide differential privacy. (This is particularly the case for ε-differential privacy, which does not allow any probability of failure, even in the worst case.) For example, the support of a textbook sampler of the Laplace distribution (required, for instance, for the Laplace mechanism) is less than 80% of all double-precision floating point numbers; moreover, the support for distributions with different means are not identical. A single sample from a naïve implementation of the Laplace mechanism allows distinguishing between two adjacent datasets with probability more than 35%.
- Timing channel through floating-point arithmetic.[35] Unlike operations over integers that are typically constant-time on modern CPUs, floating-point arithmetic exhibits significant input-dependent timing variability.[36] Handling of subnormals can be particularly slow, as much as by ×100 compared to the typical case.[37]
See also
[edit]- Implementations of differentially private analyses – deployments of differential privacy
- Quasi-identifier
- Exponential mechanism (differential privacy) – a technique for designing differentially private algorithms
- k-anonymity
- Differentially private analysis of graphs
- Protected health information
- Local differential privacy
- Privacy
References
[edit]- ^ a b Hilton, M; Cal (2012). "Differential Privacy: A Historical Survey". Semantic Scholar. S2CID 16861132. Retrieved 31 December 2023.
- ^ Dwork, Cynthia (2008-04-25). "Differential Privacy: A Survey of Results". In Agrawal, Manindra; Du, Dingzhu; Duan, Zhenhua; Li, Angsheng (eds.). Theory and Applications of Models of Computation. Lecture Notes in Computer Science. Vol. 4978. Springer Berlin Heidelberg. pp. 1–19. doi:10.1007/978-3-540-79228-4_1. ISBN 978-3-540-79227-7. S2CID 2887752.
- ^ a b c d e f g h i j k l m n o p Calibrating Noise to Sensitivity in Private Data Analysis by Cynthia Dwork, Frank McSherry, Kobbi Nissim, Adam Smith. In Theory of Cryptography Conference (TCC), Springer, 2006. doi:10.1007/11681878_14. The full version appears in Journal of Privacy and Confidentiality, 7 (3), 17-51. doi:10.29012/jpc.v7i3.405
- ^ a b c HILTON, MICHAEL. "Differential Privacy: A Historical Survey" (PDF). S2CID 16861132. Archived from the original (PDF) on 2017-03-01.
{{cite journal}}: Cite journal requires|journal=(help) - ^ a b c Dwork, Cynthia (2008). "Differential Privacy: A Survey of Results". In Agrawal, Manindra; Du, Dingzhu; Duan, Zhenhua; Li, Angsheng (eds.). Theory and Applications of Models of Computation. Lecture Notes in Computer Science. Vol. 4978. Berlin, Heidelberg: Springer. pp. 1–19. doi:10.1007/978-3-540-79228-4_1. ISBN 978-3-540-79228-4.
- ^ The Algorithmic Foundations of Differential Privacy by Cynthia Dwork and Aaron Roth. Foundations and Trends in Theoretical Computer Science. Vol. 9, no. 3–4, pp. 211‐407, Aug. 2014. doi:10.1561/0400000042
- ^ a b c Privacy integrated queries: an extensible platform for privacy-preserving data analysis by Frank D. McSherry. In Proceedings of the 35th SIGMOD International Conference on Management of Data (SIGMOD), 2009. doi:10.1145/1559845.1559850
- ^ a b Differential Privacy by Cynthia Dwork, International Colloquium on Automata, Languages and Programming (ICALP) 2006, p. 1–12. doi:10.1007/11787006_1
- ^ Kairouz, Peter, Sewoong Oh, and Pramod Viswanath. "The composition theorem for differential privacy." International conference on machine learning. PMLR, 2015.link
- ^ F.McSherry and K.Talwar. Mechasim Design via Differential Privacy. Proceedings of the 48th Annual Symposium of Foundations of Computer Science, 2007.
- ^ Christos Dimitrakakis, Blaine Nelson, Aikaterini Mitrokotsa, Benjamin Rubinstein. Robust and Private Bayesian Inference. Algorithmic Learning Theory 2014
- ^ Warner, S. L. (March 1965). "Randomised response: a survey technique for eliminating evasive answer bias". Journal of the American Statistical Association. 60 (309). Taylor & Francis: 63–69. doi:10.1080/01621459.1965.10480775. JSTOR 2283137. PMID 12261830. S2CID 35435339.
- ^ Dwork, Cynthia. "A firm foundation for private data analysis." Communications of the ACM 54.1 (2011): 86–95, supra note 19, page 91.
- ^ Bambauer, Jane, Krishnamurty Muralidhar, and Rathindra Sarathy. "Fool's gold: an illustrated critique of differential privacy." Vand. J. Ent. & Tech. L. 16 (2013): 701.
- ^ Tore Dalenius (1977). "Towards a methodology for statistical disclosure control". Statistik Tidskrift. 15. hdl:1813/111303.
- ^ Dwork, Cynthia (2006). "Differential Privacy". In Bugliesi, Michele; Preneel, Bart; Sassone, Vladimiro; Wegener, Ingo (eds.). Automata, Languages and Programming. Lecture Notes in Computer Science. Vol. 4052. Berlin, Heidelberg: Springer. pp. 1–12. doi:10.1007/11787006_1. ISBN 978-3-540-35908-1.
- ^ Dorothy E. Denning; Peter J. Denning; Mayer D. Schwartz (March 1979). "The Tracker: A Threat to Statistical Database Security". ACM Transactions on Database Systems. 4 (1): 76–96. doi:10.1145/320064.320069. S2CID 207655625.
- ^ Irit Dinur and Kobbi Nissim. 2003. Revealing information while preserving privacy. In Proceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems (PODS '03). ACM, New York, NY, USA, 202–210. doi:10.1145/773153.773173
- ^ "TCC Test-of-Time Award".
- ^ "2017 Gödel Prize".
- ^ Erlingsson, Úlfar; Pihur, Vasyl; Korolova, Aleksandra (2014). "RAPPOR: Randomized Aggregatable Privacy-Preserving Ordinal Response". Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security. pp. 1054–1067. doi:10.1145/2660267.2660348. ISBN 978-1-4503-2957-6.
- ^ google/rappor, GitHub, 2021-07-15
- ^ Tackling Urban Mobility with Technology by Andrew Eland. Google Policy Europe Blog, Nov 18, 2015.
- ^ "Apple – Press Info – Apple Previews iOS 10, the Biggest iOS Release Ever". Apple. Retrieved 20 June 2023.
- ^ Collecting telemetry data privately by Bolin Ding, Jana Kulkarni, Sergey Yekhanin. NIPS 2017.
- ^ Messing, Solomon; DeGregorio, Christina; Hillenbrand, Bennett; King, Gary; Mahanti, Saurav; Mukerjee, Zagreb; Nayak, Chaya; Persily, Nate; State, Bogdan (2020), Facebook Privacy-Protected Full URLs Data Set, Zagreb Mukerjee, Harvard Dataverse, doi:10.7910/dvn/tdoapg, retrieved 2023-02-08
- ^ Evans, Georgina; King, Gary (January 2023). "Statistically Valid Inferences from Differentially Private Data Releases, with Application to the Facebook URLs Dataset". Political Analysis. 31 (1): 1–21. doi:10.1017/pan.2022.1. ISSN 1047-1987. S2CID 211137209.
- ^ "Disclosure Avoidance for the 2020 Census: An Introduction". 2 November 2021.
- ^ "Technology Factsheet: Differential Privacy". Belfer Center for Science and International Affairs. Retrieved 2021-04-12.
- ^ McSherry, Frank (25 February 2018). "Uber's differential privacy .. probably isn't". GitHub.
- ^ Lyu, Min; Su, Dong; Li, Ninghui (1 February 2017). "Understanding the sparse vector technique for differential privacy". Proceedings of the VLDB Endowment. 10 (6): 637–648. arXiv:1603.01699. doi:10.14778/3055330.3055331. S2CID 5449336.
- ^ Haeberlen, Andreas; Pierce, Benjamin C.; Narayan, Arjun (2011). "Differential Privacy Under Fire". 20th USENIX Security Symposium.
- ^ Mironov, Ilya (October 2012). "On significance of the least significant bits for differential privacy". Proceedings of the 2012 ACM conference on Computer and communications security (PDF). ACM. pp. 650–661. doi:10.1145/2382196.2382264. ISBN 9781450316514. S2CID 3421585.
- ^ Andrysco, Marc; Kohlbrenner, David; Mowery, Keaton; Jhala, Ranjit; Lerner, Sorin; Shacham, Hovav (May 2015). "On Subnormal Floating Point and Abnormal Timing". 2015 IEEE Symposium on Security and Privacy. pp. 623–639. doi:10.1109/SP.2015.44. ISBN 978-1-4673-6949-7. S2CID 1903469.
- ^ Kohlbrenner, David; Shacham, Hovav (August 2017). "On the Effectiveness of Mitigations Against Floating-point Timing Channels". Proceedings of the 26th USENIX Conference on Security Symposium. USENIX Association: 69–81.
- ^ Dooley, Isaac; Kale, Laxmikant (September 2006). "Quantifying the interference caused by subnormal floating-point values" (PDF). Proceedings of the Workshop on Operating System Interference in High Performance Applications.
Further reading
[edit]Publications
[edit]- Calibrating noise to sensitivity in private data analysis, Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. In Proceedings of the Third conference on Theory of Cryptography (TCC'06). Springer-Verlag, Berlin, Heidelberg, 265–284. https://doi.org/10.1007/11681878_14 (This is the original publication of Differential Privacy, and not the eponymous article by Dwork that was published the same year.)
- Differential Privacy: A Survey of Results by Cynthia Dwork, Microsoft Research, April 2008 (Presents what was discovered during the first two years of research on differential privacy.)
- Differential Privacy: A Primer for a Non-Technical Audience, Alexandra Wood, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, et al, Vanderbilt Journal of Entertainment & Technology LawVanderbilt Journal of Entertainment, Volume 21, Issue 1, Fall 2018. (A good introductory document, but definitely *not* for non-technical audiences!)
- Technology Factsheet: Differential Privacy by Raina Gandhi and Amritha Jayanti, Belfer Center for Science and International Affairs, Fall 2020
- Differential Privacy and the 2020 US Census, MIT Case Studies in Social and Ethical Responsibilities of Computing, no. Winter 2022 (January). https://doi.org/10.21428/2c646de5.7ec6ab93.
- Differential Privacy, Simson L. Garfinkel, MIT Press Essential Knowledge Series, March 2025.
- Bowen, Claire McKay and Simson Garfinkel, The Philosophy of Differential Privacy, AMS Notices, November 2021.
Tutorials
[edit]- A Practical Beginner's Guide To Differential Privacy by Christine Task, Purdue University, April 2012