Mikroarchitektura

Mikroarchitektura je pojem z oboru počítačů a informačních technologií. Představuje způsob, jakým je v procesoru implementována daná instrukční sada. Pro jednu instrukční sadu může existovat více mikroarchitektur, které ji implementují. Mikroarchitekturami i návrhem instrukčních sad se zabývá obor architektura počítačů.
Mikroarchitektura je obvykle reprezentována (více či méně detailními) diagramy, které obsahují jednotlivé (logické i fyzické) části procesoru; ty jsou pak spojeny vazbami, vztahy, signály či jinými způsoby komunikace mezi nimi (u těchto spojnic se pak většinou rozlišuje mezi cestou dat a způsobem, kterým jsou zpracovávána a řízena).
Mezi základní věci, které mikroarchitektura procesoru definuje a řeší, patří model vykonávání programu (exekuční model), registry, adresování paměti, softwarová a hardwarová přerušení, datové formáty a další.
Koncepty mikroarchitektury
[editovat | editovat zdroj]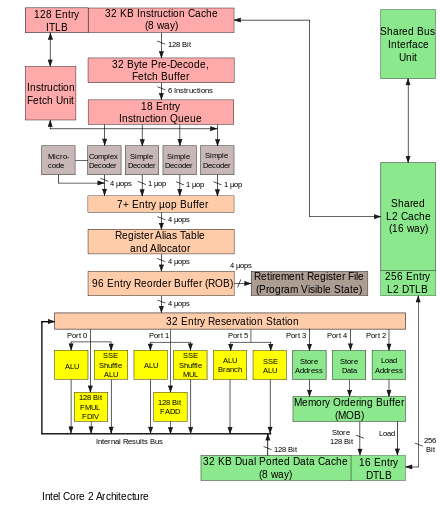
Nejčastějším návrhem procesoru současnosti je datový a instrukční pipelining. Tato technika je použita ve většině dnešních procesorů, mikrokontrolerů a datových signálových procesorů (DSP). Svým způsobem připomíná sériovou výrobu v továrně, kde místo výrobků jsou instrukce a místo dílů jednotlivé fáze jejich zpracování. Ty zahrnují načtení instrukce z programové paměti, dekódování instrukce, provedení a případné zapsání výsledku. Některé instrukce mohou vyžadovat přístup k paměti (adresování), ke vstupním/výstupním portům, skoky v programu, a další prostředky.
Bez pipeliningu by se každá fáze vykonání instrukce zabírala čas, který by procesor nevyužil na nic jiného (analogií k sériové výrobě – např. automobilů – by byl případ, ve kterém by žádný autodíl nesměl vstoupit na běžící pás dřív než by právě zpracovávané auto sjelo kompletní z výrobní linky).
Dobrý návrh pipeliningu je stěžejním bodem mikroarchitektury. Volba počtu fází zpracování instrukce, jejich samotné implementační řešení, zpoždění v jejich zpracování a konkrétně volba velikosti a typu cacheování a předpovídání větvení programu jsou prvky, které určují výkon celého procesoru. Často tato řešení narážejí na limity (popřípadě jejich kombinace, kdy zvyšování jednoho aspektu začíná omezovat druhé) a rozhodnutí, které z různých přibližně stejně dobrých alternativ dát přednost. Mezi takové konstrukční aspekty mikroarchitektury patří:
- cena
- velikost, tvar, počet vrstev, prostorové řešení čipu
- komplexnost
- spotřeba energie
- ztrátové teplo, ztrátový výkon
- kompatibilita, použitelnost v existujících systémech
- spolehlivost při vyšších frekvencích, spolupráce s jinými součástmi počítače
- odolnost, náročnost na provozní prostředí
- snadnost vývoje/testování/vychytání chyb, nároky spojené s výrobou
Prvky mikroarchitektury
[editovat | editovat zdroj]CISC versus RISC
[editovat | editovat zdroj]CISC a RISC jsou dva vzájemně soupeřící a doplňující koncepty instrukčních sad. Jejich hlavní rozdíl je v komplexitě instrukcí – zatímco CISC jde cestou implementace i velmi komplexních a složitých instrukcí, u procesorů RISC je instrukční sada redukovaná a složitější instrukce se musejí implementovat jako sekvence těch existujících. Navíc všechny instrukce RISC zabírají v paměti stejný počet bitů (binární kód je pak o něco delší, zato nemůže dojít k desinterpretaci kódu vlivem chyby s čítačem instrukcí). Výhodou architektury RISC je zachování jednoduchosti (s kterou souvisejí i výrobní náklady a cena), lepší odolnost a spolehlivost při vyšších frekvencích. To, které RISCové instrukce budou v „základní sestavě“ a které se budou muset emulovat, je určeno po pečlivé analýze využití instrukcí podle typu (většina komplexních instrukcí se využívá jen velmi zřídka, což obhajuje to, aby byly emulovány).
Přestože nejzastoupenější architektury pro osobní počítače, x86 a x86-64, jsou CISCové, je v posledních letech znát jistý odklon k RISCové technologii, například představením architektur IA-32 a IA-64.
Příklady dalších architektur (podle jiných hledisek než jen komplexnosti instrukční sady) jsou např. VLIW (Very Long Instruction Word) a EPIC (Explicitly Paralell Instruction Computing), které se snaží zvládnout datový paralelismus, včetně SIMD a vektorů.
Exekuční jednotka
[editovat | editovat zdroj]Hlavním prvkem mikroarchitektury je exekuční jednotka, která se stará o vykonávání instrukcí. Jejími komponentami většinou jsou aritmetickologická jednotka (ALU), jednotka pro počty s pohyblivou řádovou čárkou (FPU), jednotky implementující adresování a čtení/zápis z/do paměti, předpovídání větvení a SIMD.
Instrukční pipelining
[editovat | editovat zdroj]Instrukční pipelining je prvek mikroarchitektury, který má největší vliv na celkovou rychlost procesoru, neboť určuje, jak rychle budou instrukce (při dané taktovací frekvenci) zpracovávány. Někdejší návrhy MIPS a SPARC měly často 10 i vícekrát vyšší výkon oproti soudobým CISCovým procesorů při stejné frekvenci a ceně. Pipelining je využíván jak v RISCových tak CISCových procesorech (např. CISCový procesor VAX 8800 z roku 1986 měl již tehdy komplexní pipelining a dokonce i předpovídání skoků). Nyní se pipelining používá v drtivé většině procesorů (včetně embeded řešení) a vyšší složitost spojená s jeho implementací nějak zásadně do jejich ceny nepromlouvá. Nebývá jen u hardwarově specifických procesorů podporujících mikroinstrukce.
Cache
[editovat | editovat zdroj]Předpovídání skoků
[editovat | editovat zdroj]Předpovídání skoků (branch prediction) je technika mikroarchitektury, která se snaží předpovídat skoky v programu (binárním kódu), jenž má být vykonán. Vykonává se v procesorech s pipeliningem po fázi načtení a dekódování instrukcí, které zatím čekají ve frontě na vykonání. U procesorů s branch prediction je implementována logika, která se u načtených instrukcí (podmíněných) skoků pokouší předpovědět, zdali nastanou či ne, a na základě toho začne spekulativně načítat kód za cílovou adresou tohoto skoku. Pokud je podmínka pro skok do jiné části paměti splněna, začátek kódu na cílové adrese je již k dispozici, načtený do ad hoc paměti přímo v čipu. Ušetří se tak několik drahocenných okamžiků, které by jinak byly spotřebovány na zahození dosavadního kódu, přesunutí programového čítače na cílovou adresu skoku a začátek načítání do pipeliningu odtamtud.
Ještě dál než předvídání skoků jde spekulativní vykonávání kódu (speculative execution), které dokonce vykonává kód na cíli skoku. Pokud se předpověď skoku vyplní, vyústí to ve větší urychlení času, pokud nikoli, výsledkem je naopak zpomalení oproti situaci bez spekulativního vykonávání, protože všechen spekulativní kód se musí pečlivě vrátit do původního stavu.
Superskalární architektura
[editovat | editovat zdroj]Vykonávání instrukcí mimo pořadí
[editovat | editovat zdroj]U této techniky si procesor sám (bez ohledu na binární kód) určí pořadí vykonávaných instrukcí, tím, že je zpřehází tak, aby optimalizoval jejich vykonání. Některé instrukce jsou kratší a manipulují pouze s daty v registrech, jiné vyžadují přístup k paměti (která buď je nebo není v cache), portům, atd. a vyžadují více času na provedení. Procesor pak v takovém případě může buďto čekat na výsledek nebo v mezičase vykonávat instrukce, které nejsou takto časově náročné a jejich vykonání v tomto přehozeném pořadí v žádném případě neovlivní chod programu. Zde je důležité pečlivě hlídat závislosti hodnot různých registrů na sobě, použití příznaků, které vytvoří, apod. (nelze například prohodit pořadí po sobě jdoucích instrukcí, které operují se stejným registrem, neboť by program došel k různým výsledkům). Analýza a implementace vykonávání instrukcí mimo pořadí patří v architektuře počítačů mezi ty náročnější.
Mezistupněm do tohoto stádia je použití kompilátoru pro daný procesor (z assembleru i vyššího programovacího jazyka), který pořadí instrukcí optimalizuje za procesor. Jedny z prvních takových byly kompilátory jazyka C pro procesory P6 a později kompilátory pro C#.
Přejmenovávání registrů
[editovat | editovat zdroj]S určitou paralelou k vykonávání instrukcí mimo pořadí i zde procesor mění binární kód, jež má vykonávat, tentokrát tím, že si přejmenovává registry a to tak, aby odstranil nepotřebné serializované vykonávání programu, vynucené opětovným používáním stejných registrů. Opět, i tato technika je náročná na implementaci, protože musí být transparentní vůči vykonávání původního kódu v nezměněné podobě (logika přejmenovávání registrů nesmí například přepisovat registry, které by byly v této fázi čteny).
Multiprocesing a multithreading
[editovat | editovat zdroj]Tyto dvě technologie implementují paralelismus vykonávaného programu. Multiprocesing pomocí zapojení a využití více procesorů v počítači, kdy každý procesor si bere na starosti různé agendy programu (nebo operačního systému a v něm běžícího programu). Multithreading v rozdělení programu do tzv. vláken (threadů), přinejmenším pro odstranění modálnosti aplikace (tedy její netečnosti do dokončení nějakého jejího vykonávaného procesu, např. ukládání, nahrávání, konvertování, …) až po simultánní multithreading, který umožňuje superskalárním procesorům vykonávat instrukce z různých programů simultánně ve stejný okamžik.
Existující mikroarchitektury
[editovat | editovat zdroj]Intel
[editovat | editovat zdroj]Mikroarchitektury x86:
- x86 (8086, 80186, 80286, i386, i486)
- P5
- P6 (Pentium M / Enhanced Pentium M)
- NetBurst
- Core (Penryn)
- Bonnell (Saltwell)
- Nehalem (Westmere)
- Sandy Bridge (Ivy Bridge)
- Haswell (Broadwell)
- Silvermont (Airmont)
- Skylake (Cannonlake (Valleyview, Tangier, Cherryview))
- Larrabee
- Goldmont
Mikroarchitektury Itanium:
- Merced
- McKinley
- Montecito
- Tukwila
- Poulson
- Kittson
AMD
[editovat | editovat zdroj]Mikroarchitektury x86:
- Am386, Am486, Am5x86
- K5
- K6 (K6-2, K6-III)
- K7 (Athlon, Duron, Sempron)
- K8 Hammer/Sledgehammer (Opteron, Athlon, Turion 64)
- K10/(Barcelona, Budapest, Agena, Toliman, Kuma, Lima, Sparta)/(Family 10h)
- K10.5 (Phenom II, Athlon II, Sempron, Turion II)
- AMD Turion X2 Ultra (Family 11h)
- K12 Llano (Family 12h)
- Bobcat (Family 14h)
- Bulldozer (Family 15h)
- Piledriver
- Steamroller
- Jaguar (Family 16h)
- Excavator
Mikroarchitektury nekompatibilní s x86:
- AMD Am2900
- AMD Am29000
ARM
[editovat | editovat zdroj]Odkazy
[editovat | editovat zdroj]Reference
[editovat | editovat zdroj]V tomto článku byl použit překlad textu z článku Microarchitecture na anglické Wikipedii.
Externí odkazy
[editovat | editovat zdroj]Obrázky, zvuky či videa k tématu mikroarchitektura na Wikimedia Commons
- (anglicky)PC Processor Microarchitecture Archivováno 7. 6. 2011 na Wayback Machine.
- (anglicky)Computer Architecture: A Minimalist Perspective - book webpage