Pemahaman dokumen menjadi mudah dengan AI generatif—rangkum dokumen berukuran besar dengan solusi siap pakai yang direkomendasikan Google.
Vision AI
Ekstrak insight dari gambar, dokumen, dan video
Akses model visi tingkat lanjut melalui API untuk mengotomatiskan tugas visi, menyederhanakan analisis, dan mendapatkan hasil analisis yang bisa ditindaklanjuti. Atau bangun aplikasi kustom dengan pelatihan model no-code dan biaya rendah di lingkungan terkelola.
Pelanggan baru akan mendapatkan kredit gratis senilai hingga $300 untuk mencoba Vision AI dan produk Google Cloud lainnya.
Anda juga dapat mencoba men-deploy solusi peringkasan dokumen dan pemrosesan gambar AI/ML yang direkomendasikan Google.
Ringkasan
Apa itu computer vision?
Computer vision adalah bidang kecerdasan buatan (AI) yang memungkinkan komputer dan sistem menafsirkan dan menganalisis data visual serta memperoleh informasi yang berarti dari gambar digital, video, dan input visual lainnya. Beberapa penerapan umum solusi ini di dunia termasuk: deteksi objek, pemrosesan konten visual (gambar, dokumen, video), pemahaman dan analisis, penelusuran produk, penelusuran dan klasifikasi gambar, serta moderasi konten.
AI generatif multimodal canggih
Vertex AI dari Google Cloud menawarkan akses ke Gemini, yakni model multimodal canggih yang mampu memahami hampir semua jenis input, menggabungkan berbagai jenis informasi, dan menghasilkan hampir semua jenis output. Meskipun Gemini paling cocok untuk tugas yang menggabungkan visual, teks, dan kode, Gemini Pro Vision unggul dalam berbagai tugas terkait visi, seperti pengenalan objek, pemahaman konten digital, dan pemberian teks/deskripsi. Anda dapat mengaksesnya melalui API.
AI generatif yang berfokus pada Vision
Imagen di Vertex AI menghadirkan kemampuan AI generatif gambar paling canggih dari Google kepada developer aplikasi melalui API. Beberapa fitur utamanya mencakup pembuatan gambar (GA terbatas) dengan perintah teks, pengeditan gambar (GA terbatas) dengan perintah teks, mendeskripsikan gambar dalam teks (juga dikenal sebagai visual captioning, GA), dan penyesuaian model subjek (GA terbatas). Pelajari lebih lanjut berbagai fitur utamanya dan tahapan peluncurannya.
Vision AI yang Siap Digunakan
Didukung oleh model ML computer vision terlatih, Cloud Vision API adalah API (REST dan RPC) yang siap digunakan dan memungkinkan developer mengintegrasikan fitur deteksi penglihatan umum dengan mudah dalam aplikasi, termasuk pelabelan gambar, deteksi wajah dan struktur, pengenalan karakter optik (OCR), dan pemberian tag konten vulgar.
Setiap fitur yang Anda terapkan ke gambar adalah unit yang dapat ditagih. Dengan Cloud Vision API, Anda dapat menggunakan 1.000 unit fiturnya secara gratis setiap bulannya. Lihat detail harga
Pemahaman dokumen AI generatif
Document AI adalah platform pemahaman dokumen yang menggabungkan computer vision dan teknologi lain seperti natural language processing untuk mengekstrak teks dan data dari dokumen yang dipindai, mengubah data tidak terstruktur menjadi informasi terstruktur dan insight bisnis.
Solusi ini menawarkan berbagai pemroses terlatih yang dioptimalkan untuk berbagai jenis dokumen. Solusi ini juga mempermudah pembuatan pemroses kustom untuk mengklasifikasikan, membagi, dan mengekstrak data terstruktur dari dokumen melalui Document AI Workbench.

Vision AI yang siap digunakan untuk video
Dengan teknologi computer vision sebagai intinya, Video Intelligence API adalah cara mudah untuk memproses, menganalisis, dan memahami konten video.
Model ML-nya yang terlatih akan otomatis mengenali aneka jenis objek, tempat, dan tindakan dalam video yang disimpan maupun video streaming, dengan kualitas luar biasa. Solusi ini sangat efisien untuk kasus penggunaan umum seperti moderasi dan rekomendasi konten, arsip media, dan iklan kontekstual. Anda juga dapat melatih model ML kustom dengan Vertex AI Vision untuk kebutuhan spesifik Anda.

Visual Inspection AI
Visual Inspection AI mengotomatiskan tugas pemeriksaan visual di lingkungan manufaktur dan industri lainnya. Layanan ini memanfaatkan computer vision dan teknik deep learning yang canggih untuk menganalisis gambar dan video, mengidentifikasi anomali, mendeteksi dan menemukan kerusakan, serta memeriksa bagian yang hilang dan rusak pada produk rakitan.
Anda dapat melatih model kustom tanpa perlu keahlian teknis dan dengan gambar berlabel minimum, menjalankan inferensi secara efisien di jalur produksi, dan terus memperbarui model dengan data baru dari pabrik.

Platform Vision AI Terpadu
Vertex AI Vision adalah lingkungan pengembangan aplikasi terkelola sepenuhnya yang memungkinkan developer untuk membangun, men-deploy, dan mengelola aplikasi computer vision dengan mudah untuk memproses berbagai modalitas data, seperti teks, gambar, video, dan data tabulasi. Teknologi ini mengurangi waktu untuk membangun aplikasi dari hitungan hari menjadi hitungan menit dengan biaya sepersepuluh dari penawaran saat ini.
Anda dapat membangun dan men-deploy model kustom Anda sendiri, serta mengelola dan menskalakannya dengan pipeline CI/CD. Codelab ini juga terintegrasi dengan alat open source populer, seperti TensorFlow dan PyTorch.

Privasi dan keamanan data
Google Cloud memiliki kemampuan terdepan di industri yang memberi Anda—pelanggan kami—kontrol atas data Anda serta memberikan visibilitas tentang waktu dan cara data Anda diakses.
Sebagai pelanggan Google Cloud, Anda adalah pemilik data pelanggan Anda. Kami menerapkan langkah-langkah keamanan yang ketat untuk mengamankan data pelanggan serta memberi Anda alat dan fitur untuk mengontrolnya sesuai keinginan Anda. Data pelanggan adalah data Anda, bukan data Google. Kami hanya memproses data Anda sesuai dengan perjanjian Anda.
Pelajari lebih lanjut di Privacy Resource Center.
Membandingkan produk computer vision
| Penawaran | Paling cocok untuk | Fitur utama |
|---|---|---|
Integrasi fitur visi dasar yang cepat dan mudah. | Fitur bawaan seperti pelabelan gambar, deteksi wajah dan tempat terkenal, OCR, dan penelusuran aman. Hemat biaya, bayar per penggunaan. | |
Mengekstrak insight dari dokumen dan gambar yang dipindai, sehingga mengotomatiskan alur kerja dokumen. | OCR (didukung oleh AI Generatif), NLP, ML untuk pemahaman dokumen, ekstraksi teks, identifikasi entity, kategorisasi dokumen. | |
Menganalisis konten video, moderasi dan rekomendasi konten, arsip media, dan iklan kontekstual. | Deteksi dan pelacakan objek, pemahaman scene, pengenalan aktivitas, deteksi dan analisis wajah, deteksi dan pengenalan teks. | |
Mengotomatiskan tugas inspeksi visual di lingkungan manufaktur dan industri | Mendeteksi anomali, mendeteksi dan menemukan kerusakan, serta memeriksa perakitan. | |
Membangun dan men-deploy model kustom untuk kebutuhan tertentu. | Alat persiapan data, pelatihan model, dan deployment, kontrol penuh atas solusi Anda. Membutuhkan keahlian teknis. | |
Analisis dan pemahaman visual, question answering multimodal. | Pencarian info, pengenalan objek, pemahaman konten digital, pembuatan konten terstruktur, pemberian teks/deskripsi, dan ekstrapolasi. | |
Mendapatkan deskripsi gambar otomatis. Penelusuran dan klasifikasi gambar. Moderasi dan rekomendasi konten. | Pembuatan gambar, pengeditan gambar, visual captioning, dan embedding multimodal. Lihat daftar lengkap fitur dan tahap peluncurannya. |
Karena dioptimalkan untuk berbagai tujuan, produk ini memungkinkan Anda memanfaatkan model ML terlatih dan memulai dengan cepat dan efektif, serta dapat melakukan penyesuaian dengan mudah.
Integrasi fitur visi dasar yang cepat dan mudah.
Fitur bawaan seperti pelabelan gambar, deteksi wajah dan tempat terkenal, OCR, dan penelusuran aman.
Hemat biaya, bayar per penggunaan.
Mengekstrak insight dari dokumen dan gambar yang dipindai, sehingga mengotomatiskan alur kerja dokumen.
OCR (didukung oleh AI Generatif), NLP, ML untuk pemahaman dokumen, ekstraksi teks, identifikasi entity, kategorisasi dokumen.
Menganalisis konten video, moderasi dan rekomendasi konten, arsip media, dan iklan kontekstual.
Deteksi dan pelacakan objek, pemahaman scene, pengenalan aktivitas, deteksi dan analisis wajah, deteksi dan pengenalan teks.
Mengotomatiskan tugas inspeksi visual di lingkungan manufaktur dan industri
Mendeteksi anomali, mendeteksi dan menemukan kerusakan, serta memeriksa perakitan.
Membangun dan men-deploy model kustom untuk kebutuhan tertentu.
Alat persiapan data, pelatihan model, dan deployment, kontrol penuh atas solusi Anda. Membutuhkan keahlian teknis.
Analisis dan pemahaman visual, question answering multimodal.
Pencarian info, pengenalan objek, pemahaman konten digital, pembuatan konten terstruktur, pemberian teks/deskripsi, dan ekstrapolasi.
Mendapatkan deskripsi gambar otomatis.
Penelusuran dan klasifikasi gambar.
Moderasi dan rekomendasi konten.
Pembuatan gambar, pengeditan gambar, visual captioning, dan embedding multimodal.
Lihat daftar lengkap fitur dan tahap peluncurannya.
Karena dioptimalkan untuk berbagai tujuan, produk ini memungkinkan Anda memanfaatkan model ML terlatih dan memulai dengan cepat dan efektif, serta dapat melakukan penyesuaian dengan mudah.
Cara Kerjanya
Rangkaian alat Vision AI Google Cloud menggabungkan computer vision dengan teknologi lain untuk memahami dan menganalisis video serta mengintegrasikan fitur deteksi visi dalam aplikasi dengan mudah, termasuk pelabelan gambar, deteksi wajah dan struktur, pengenalan karakter optik (OCR), dan pemberian tag konten vulgar.
Alat-alat ini tersedia melalui API dan tetap dapat disesuaikan untuk kebutuhan tertentu.
Rangkaian alat Vision AI Google Cloud menggabungkan computer vision dengan teknologi lain untuk memahami dan menganalisis video serta mengintegrasikan fitur deteksi visi dalam aplikasi dengan mudah, termasuk pelabelan gambar, deteksi wajah dan struktur, pengenalan karakter optik (OCR), dan pemberian tag konten vulgar.
Alat-alat ini tersedia melalui API dan tetap dapat disesuaikan untuk kebutuhan tertentu.

Demo
Melihat cara kerja computer vision dengan file yang Anda miliki
Penggunaan Umum
Mendeteksi teks dalam file mentah dan membuat ringkasan secara otomatis
Meringkas dokumen besar dengan AI generatif
Solusi yang digambarkan dalam diagram arsitektur di sebelah kanan men-deploy pipeline yang dipicu saat Anda menambahkan dokumen PDF baru ke bucket Cloud Storage. Pipeline mengekstrak teks dari dokumen Anda, membuat ringkasan dari teks yang diekstrak, dan menyimpan ringkasan tersebut dalam database untuk Anda lihat dan telusuri.
Anda dapat memanggil aplikasi dengan mengupload file melalui Jupyter Notebook, atau langsung ke Cloud Storage di konsol Google Cloud.
Perkiraan waktu deployment: 11 menit (1 menit untuk mengonfigurasi, 10 menit untuk men-deploy).
Petunjuk
Meringkas dokumen besar dengan AI generatif
Solusi yang digambarkan dalam diagram arsitektur di sebelah kanan men-deploy pipeline yang dipicu saat Anda menambahkan dokumen PDF baru ke bucket Cloud Storage. Pipeline mengekstrak teks dari dokumen Anda, membuat ringkasan dari teks yang diekstrak, dan menyimpan ringkasan tersebut dalam database untuk Anda lihat dan telusuri.
Anda dapat memanggil aplikasi dengan mengupload file melalui Jupyter Notebook, atau langsung ke Cloud Storage di konsol Google Cloud.
Perkiraan waktu deployment: 11 menit (1 menit untuk mengonfigurasi, 10 menit untuk men-deploy).
Membangun pipeline pemrosesan gambar
Pemrosesan gambar yang skalabel pada arsitektur serverless
Solusi yang digambarkan dalam diagram di sebelah kanan, menggunakan model machine learning yang telah dilatih sebelumnya untuk menganalisis gambar yang disediakan pengguna dan menghasilkan anotasi gambar. Men-deploy solusi ini akan membuat layanan pemrosesan gambar yang dapat membantu Anda menangani konten buatan pengguna yang tidak aman atau berbahaya, mendigitalkan teks dari dokumen fisik, mendeteksi dan mengklasifikasikan objek dalam gambar, dan banyak lagi.
Anda akan dapat meninjau setelan konfigurasi dan keamanan untuk memahami cara menyesuaikan layanan pemrosesan gambar dengan berbagai kebutuhan.
Perkiraan waktu deployment: 12 menit (2 menit untuk mengonfigurasi, 10 menit untuk men-deploy).
Petunjuk
Pemrosesan gambar yang skalabel pada arsitektur serverless
Solusi yang digambarkan dalam diagram di sebelah kanan, menggunakan model machine learning yang telah dilatih sebelumnya untuk menganalisis gambar yang disediakan pengguna dan menghasilkan anotasi gambar. Men-deploy solusi ini akan membuat layanan pemrosesan gambar yang dapat membantu Anda menangani konten buatan pengguna yang tidak aman atau berbahaya, mendigitalkan teks dari dokumen fisik, mendeteksi dan mengklasifikasikan objek dalam gambar, dan banyak lagi.
Anda akan dapat meninjau setelan konfigurasi dan keamanan untuk memahami cara menyesuaikan layanan pemrosesan gambar dengan berbagai kebutuhan.
Perkiraan waktu deployment: 12 menit (2 menit untuk mengonfigurasi, 10 menit untuk men-deploy).
Mendapatkan deskripsi gambar otomatis dengan AI generatif
Fitur Visual Captioning di Imagen memungkinkan Anda membuat deskripsi yang relevan untuk gambar. Anda dapat menggunakannya untuk mendapatkan metadata yang lebih mendetail tentang gambar untuk disimpan dan ditelusuri, untuk membuat teks otomatis guna mendukung kasus penggunaan aksesibilitas, dan mendapatkan deskripsi singkat tentang produk dan aset visual.
Fitur ini tersedia dalam bahasa Inggris, Prancis, Jerman, Italia, dan Spanyol, dan dapat diakses di Konsol Google Cloud, atau melalui panggilan API.
Petunjuk
Fitur Visual Captioning di Imagen memungkinkan Anda membuat deskripsi yang relevan untuk gambar. Anda dapat menggunakannya untuk mendapatkan metadata yang lebih mendetail tentang gambar untuk disimpan dan ditelusuri, untuk membuat teks otomatis guna mendukung kasus penggunaan aksesibilitas, dan mendapatkan deskripsi singkat tentang produk dan aset visual.
Fitur ini tersedia dalam bahasa Inggris, Prancis, Jerman, Italia, dan Spanyol, dan dapat diakses di Konsol Google Cloud, atau melalui panggilan API.
Membuat proses streaming video
Mendapatkan insight dari video streaming dengan Vertex AI Vision
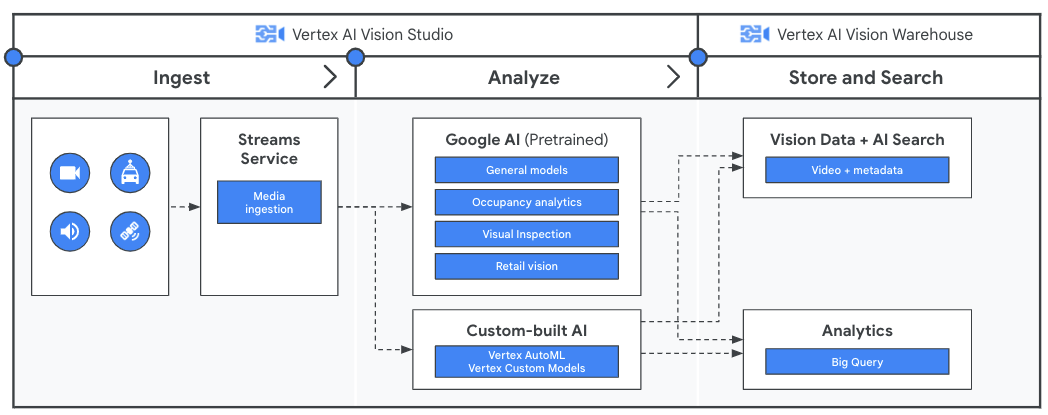
Sebelum menganalisis data video dengan aplikasi Anda, buat pipeline untuk aliran data berkelanjutan dengan layanan Stream di Vertex AI Vision. Data yang diserap kemudian dianalisis oleh model Google yang telah dilatih sebelumnya atau model kustom Anda. Output analisis dari streaming tersebut akan disimpan di Vertex AI Vision Warehouse tempat Anda dapat menggunakan kemampuan penelusuran canggih dengan teknologi AI untuk mengkueri konten media yang tidak terstruktur.
Petunjuk
Mendapatkan insight dari video streaming dengan Vertex AI Vision
Sebelum menganalisis data video dengan aplikasi Anda, buat pipeline untuk aliran data berkelanjutan dengan layanan Stream di Vertex AI Vision. Data yang diserap kemudian dianalisis oleh model Google yang telah dilatih sebelumnya atau model kustom Anda. Output analisis dari streaming tersebut akan disimpan di Vertex AI Vision Warehouse tempat Anda dapat menggunakan kemampuan penelusuran canggih dengan teknologi AI untuk mengkueri konten media yang tidak terstruktur.
Mengekstrak teks dan insight dari dokumen dengan AI generatif
Mendapatkan insight dari dokumen yang beragam dengan Document AI
Dengan dukungan model dasar, Document AI Custom Extractor dapat mengekstrak teks dan data dari dokumen generik dan khusus domain, secara lebih cepat dan dengan akurasi yang lebih tinggi. Sesuaikan dengan mudah hanya dengan 5-10 dokumen untuk mendapatkan performa yang lebih baik.
Jika Anda ingin melatih model sendiri, beri label otomatis pada set data dengan model dasar untuk mempercepat waktu produksi.
Anda juga dapat memilih untuk menggunakan pemroses khusus terlatih—lihat daftar lengkap pemroses.
Petunjuk
Mendapatkan insight dari dokumen yang beragam dengan Document AI
Dengan dukungan model dasar, Document AI Custom Extractor dapat mengekstrak teks dan data dari dokumen generik dan khusus domain, secara lebih cepat dan dengan akurasi yang lebih tinggi. Sesuaikan dengan mudah hanya dengan 5-10 dokumen untuk mendapatkan performa yang lebih baik.
Jika Anda ingin melatih model sendiri, beri label otomatis pada set data dengan model dasar untuk mempercepat waktu produksi.
Anda juga dapat memilih untuk menggunakan pemroses khusus terlatih—lihat daftar lengkap pemroses.
Pemeriksaan visual presisi tinggi
Mengotomatiskan pemeriksaan kualitas dengan Visual Inspection AI
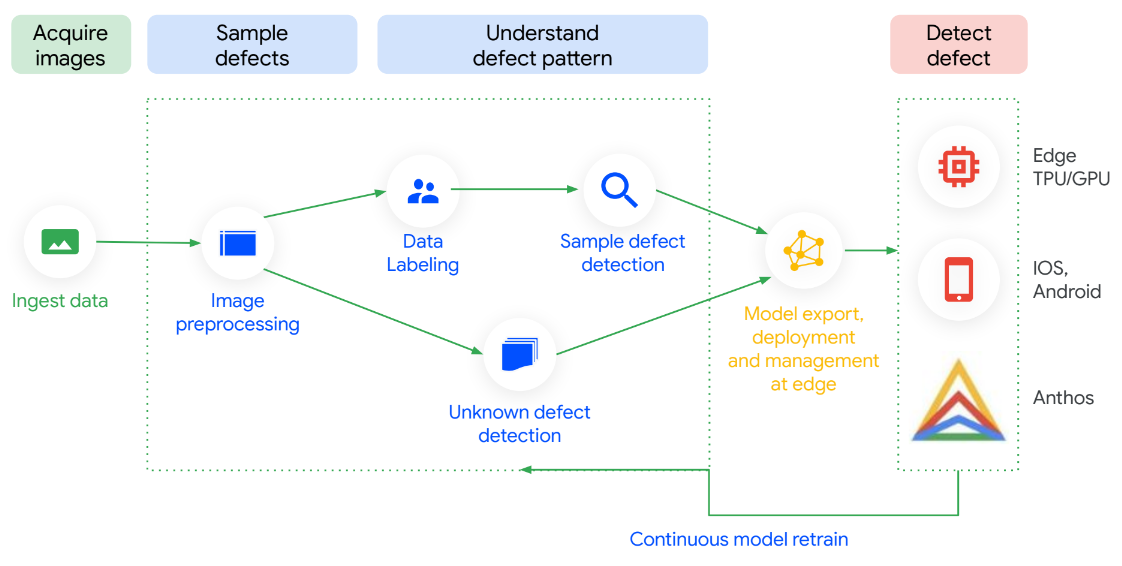
Visual Inspection AI dioptimalkan di setiap langkah sehingga mudah disiapkan dan cepat untuk melihat ROI. Dengan gambar berlabel 300 kali lebih sedikit untuk mulai melatih model inspeksi berperforma tinggi dibandingkan platform ML tujuan umum, platform ML ini terbukti memberikan akurasi hingga 10 kali lebih tinggi. Anda dapat melatih model tanpa keahlian teknis, dan model tersebut berjalan secara lokal. Keunggulan terbaiknya adalah model ini dapat terus diperbarui dengan data yang mengalir dari pabrik, sehingga memberi Anda akurasi yang lebih baik saat menemukan kasus penggunaan baru.
Petunjuk
Mengotomatiskan pemeriksaan kualitas dengan Visual Inspection AI
Visual Inspection AI dioptimalkan di setiap langkah sehingga mudah disiapkan dan cepat untuk melihat ROI. Dengan gambar berlabel 300 kali lebih sedikit untuk mulai melatih model inspeksi berperforma tinggi dibandingkan platform ML tujuan umum, platform ML ini terbukti memberikan akurasi hingga 10 kali lebih tinggi. Anda dapat melatih model tanpa keahlian teknis, dan model tersebut berjalan secara lokal. Keunggulan terbaiknya adalah model ini dapat terus diperbarui dengan data yang mengalir dari pabrik, sehingga memberi Anda akurasi yang lebih baik saat menemukan kasus penggunaan baru.
Harga
| Mekanisme penetapan harga Vision AI | Setiap penawaran visi memiliki serangkaian fitur atau prosesor, yang memiliki harga berbeda. Lihat halaman rincian harga untuk mengetahui detailnya. | ||
|---|---|---|---|
| Tingkatan gratis | Produk/Layanan | Harga diskon | Detail |
Vision API | 1.000 unit pertama setiap bulan gratis | 5.000.001+ unit per bulan | |
Document AI | T/A Harga bergantung pada prosesor. | 5.000.001+ halaman per bulan untuk Pemroses Enterprise Document OCR | |
Video Intelligence API | 1.000 menit pertama per bulan gratis | 100.000+ menit per bulan | |
Vertex AI Vision | T/A Penetapan harga bersifat sensitif terhadap fitur. |
| |
Imagen—embedding multimodal |
|
| US$0,0001 per input gambar |
Imagen—visual captioning |
|
| US$0,0015 per gambar |
Gemini Pro Vision | |||
Mekanisme penetapan harga Vision AI
Setiap penawaran visi memiliki serangkaian fitur atau prosesor, yang memiliki harga berbeda. Lihat halaman rincian harga untuk mengetahui detailnya.
Vision API
1.000 unit pertama
setiap bulan gratis
5.000.001+ unit
per bulan
Document AI
T/A
Harga bergantung pada prosesor.
5.000.001+ halaman
per bulan untuk Pemroses Enterprise Document OCR
1.000 menit pertama
per bulan gratis
100.000+ menit
per bulan
Vertex AI Vision
T/A
Penetapan harga bersifat sensitif terhadap fitur.
Imagen—embedding multimodal
US$0,0001
per input gambar
Imagen—visual captioning
US$0,0015
per gambar