Speech-to-Text
Sprache mit der KI von Google in Text umwandeln
Mit nutzerfreundlichen APIs wandeln Sie Gesprochenes in Texttranskriptionen um und integrieren Spracherkennung in Anwendungen.
Neukunden erhalten außerdem ein Guthaben von bis zu 300 $, um Speech-to-Text und andere Google Cloud-Produkte auszuprobieren.
Features
Erweiterte Sprach-KI
Speech-to-Text kann Chirp verwenden, das Google Cloud-Basismodell für Sprache. Es wird anhand von Millionen von Stunden an Audiodaten und Milliarden von Textsätzen trainiert. Dies steht im Gegensatz zu herkömmlichen Spracherkennungstechniken, die sich auf große Mengen sprachspezifischer, überwachter Daten konzentrieren. Diese Techniken verbessern die Erkennung und Transkription von Nutzern für mehr gesprochene Sprachen und Akzente.
Unterstützung von 125 Sprachen und Sprachvarianten
Schaffen Sie sich mit umfangreicher Sprachunterstützung eine globale Nutzerbasis. Transkribieren Sie kurze und lange Audiodateien und sogar gestreamte Audiodaten. Speech-to-Text bietet Nutzern außerdem mit Chirp, der nächsten Generation von universellen Sprachmodellen, eine genauere und weltübergreifende Übersetzung und Erkennung. Chirp wurde durch selbstverwaltetes Training mit Millionen Stunden Audiomaterial und 28 Milliarden Sätzen an Text in über 100 Sprachen entwickelt.
Vortrainierte oder anpassbare Modelle für die Transkription
Für die Sprachsteuerung und die Transkription von Telefonanrufen und Videos stehen verschiedene vortrainierte Modelle zur Auswahl, die für die besonderen Qualitätsanforderungen im jeweiligen Bereich optimiert sind.Mit der Speech-to-Text-UI können Sie benutzerdefinierte Ressourcen ganz einfach anpassen, testen, erstellen und verwalten.
Sofort einsatzbereite Compliance mit gesetzlichen Vorschriften und Sicherheitsvorschriften
Mit der Speech-to-Text API Version 2 erhalten Unternehmens- und Geschäftskunden zusätzliche Sicherheits- und regulatorische Anforderungen. Der Datenstandort ermöglicht den Aufruf von Transkriptionsmodellen über einen vollständig regionalisierten Dienst, der Google Cloud-Regionen wie Singapur und Belgien nutzt. Dank Einfallsreichtum der Erkennung sind keine speziellen Dienstkonten für die Authentifizierung und Autorisierung erforderlich. Logs zum Generieren und Transkribieren von Ressourcen werden in der Google Cloud Console ganz einfach zur Verfügung gestellt. Die Speech-to-Text API Version 2 bietet außerdem eine Verschlüsselung für Unternehmen mit vom Kunden verwalteten Verschlüsselungsschlüsseln für alle Ressourcen sowie Batchtranskription.
KI-gestützte Spracherkennung und -transkription
Speech-to-Text verwendet Modellanpassung, um die Genauigkeit häufig verwendeter Wörter zu verbessern, das für die Transkription verfügbare Vokabular zu erweitern und die Transkription von verrauschten Audiodaten zu verbessern. Mit der Modellanpassung können Nutzer Speech-to-Text so anpassen, dass bestimmte Wörter oder Wortgruppen häufiger erkannt werden als andere Optionen, die sonst möglicherweise vorgeschlagen werden. Sie können Speech-to-Text beispielsweise dahingehend beeinflussen, ob Sie „Butter“ statt „Buddha“ transkribieren.
Spracherkennung per Streaming
Bei der Echtzeit-Spracherkennung verarbeitet die API Audioeingaben, die über das Mikrofon einer Anwendung gestreamt oder aus einer aufgezeichneten Audiodatei gesendet werden (inline oder über Cloud Storage).
Sprachanpassung
Passen Sie die Spracherkennung an Ihre besonderen Gegebenheiten an. Geben Sie Hinweise für Fachbegriffe und seltene Wörter und verbessern Sie so die Accuracy beim Transkribieren bestimmter Wörter oder Wortgruppen. Mithilfe von Klassen können gesprochene Zahlen automatisch in Adressen, Jahresangaben, Geldbeträge und vieles mehr umgewandelt werden.
Speech-to-Text On-Prem
Sie behalten die volle Kontrolle über Ihre Infrastruktur und geschützten Sprachdaten, wenn Sie die Spracherkennung von Google lokal in Ihren eigenen, privaten Rechenzentren nutzen. Unser Vertrieb hilft Ihnen beim Start.
Multikanal-Erkennung
In Multichannel-Szenarien (z. B. in einer Videokonferenz) erkennt Speech-to-Text die unterschiedlichen Kanäle und bearbeitet die Transkripte entsprechend, um die Reihenfolge zu bewahren.
Unterdrückung von Nebengeräuschen
Speech-to-Text verarbeitet Audioinhalte mit Nebengeräuschen aus unterschiedlichsten Umgebungen, ohne dass eine zusätzliche Geräuschunterdrückung notwendig ist.
Modelle für spezielle Bereiche
Für die Sprachsteuerung und die Transkription von Telefonanrufen und Videos stehen verschiedene vortrainierte Modelle zur Auswahl, die für die besonderen Qualitätsanforderungen im jeweiligen Bereich optimiert sind. Unser erweitertes Telefoniemodell ist beispielsweise auf Audioaufnahmen von Telefonaten abgestimmt, wie etwa Aufnahmen mit einer Abtastrate von 8 kHz.
Inhalte filtern
Der Obszönitätenfilter erkennt unangemessene oder unsachgemäße Inhalte in den Audiodaten. Vulgäre Sprache wird aus der Textausgabe herausgefiltert.
Transkriptionsbewertung
Sie können eigene Sprachdaten hochladen und diese ohne Code transkribieren lassen. Bewerten Sie die Qualität, indem Sie Ihre Konfiguration iterieren.
Automatische Zeichensetzung (Beta)
Speech-to-Text sorgt für korrekte Zeichensetzung bei Transkriptionen, z. B. durch die Angabe von Kommas, Fragezeichen und Punkten.
Sprecherbestimmung
Sie können automatisch ermitteln lassen, von welchem Sprecher in einer Unterhaltung welche Äußerung stammt.
Funktionsweise
Speech-to-Text hat drei Hauptmethoden zur Spracherkennung: synchron, asynchron und Streaming. Bei jeder Methode werden Textergebnisse zurückgegeben, die davon abhängen, ob die Transkription bei der Nachbearbeitung, in regelmäßigen Abständen oder in Echtzeit erforderlich ist. Einfach ausgedrückt: Sie geben Audiodaten ein und erhalten dann eine textbasierte Antwort.
Speech-to-Text hat drei Hauptmethoden zur Spracherkennung: synchron, asynchron und Streaming. Bei jeder Methode werden Textergebnisse zurückgegeben, die davon abhängen, ob die Transkription bei der Nachbearbeitung, in regelmäßigen Abständen oder in Echtzeit erforderlich ist. Einfach ausgedrückt: Sie geben Audiodaten ein und erhalten dann eine textbasierte Antwort.

Demo
Speech-to-Text API testen
Du kannst Audiotranskripte schnell erstellen – entweder per Datei-Upload oder per Sprachbefehl direkt in ein Mikrofon.
Gängige Einsatzmöglichkeiten
Audio transkribieren
Audiotranskript erstellen
Audiotranskript erstellen
Hier erfahren Sie, wie Sie die Speech-to-Text API in der Cloud Console verwenden, indem Sie in nur wenigen Schritten eine Audiotranskription erstellen. Außerdem lassen sich kurze und lange Audioinhalte sowie Audiostreams transkribieren.
Tutorials, Kurzanleitungen und Labs
Audiotranskript erstellen
Audiotranskript erstellen
Hier erfahren Sie, wie Sie die Speech-to-Text API in der Cloud Console verwenden, indem Sie in nur wenigen Schritten eine Audiotranskription erstellen. Außerdem lassen sich kurze und lange Audioinhalte sowie Audiostreams transkribieren.
Videos mithilfe von KI untertiteln
Mit KI Untertitel für Videos erstellen
Mit KI Untertitel für Videos erstellen
Transkribieren Sie Audio- und Videoinhalte mit Untertiteln. Untertitel zu bestehenden Inhalten oder in Echtzeit zu Streaminginhalten hinzufügen Unser Videotranskriptionsmodell ist ideal für die Indexierung oder Untertitelung von Videos und/oder Inhalten mit mehreren Sprechern und nutzt ähnliche ML-Technologie wie YouTube für die Untertitelung. In dieser Anleitung erfahren Sie, wie Sie mit den KI-Diensten von Google Cloud, der Speech-to-Text API und der Translation API Videos Untertitel hinzufügen und lokalisierte Untertitel in anderen Sprachen bereitstellen.
Tutorials, Kurzanleitungen und Labs
Mit KI Untertitel für Videos erstellen
Mit KI Untertitel für Videos erstellen
Transkribieren Sie Audio- und Videoinhalte mit Untertiteln. Untertitel zu bestehenden Inhalten oder in Echtzeit zu Streaminginhalten hinzufügen Unser Videotranskriptionsmodell ist ideal für die Indexierung oder Untertitelung von Videos und/oder Inhalten mit mehreren Sprechern und nutzt ähnliche ML-Technologie wie YouTube für die Untertitelung. In dieser Anleitung erfahren Sie, wie Sie mit den KI-Diensten von Google Cloud, der Speech-to-Text API und der Translation API Videos Untertitel hinzufügen und lokalisierte Untertitel in anderen Sprachen bereitstellen.
Speech-to-Text zu Anwendungen hinzufügen
Speech-to-Text zu Anwendungen hinzufügen
Speech-to-Text zu Anwendungen hinzufügen
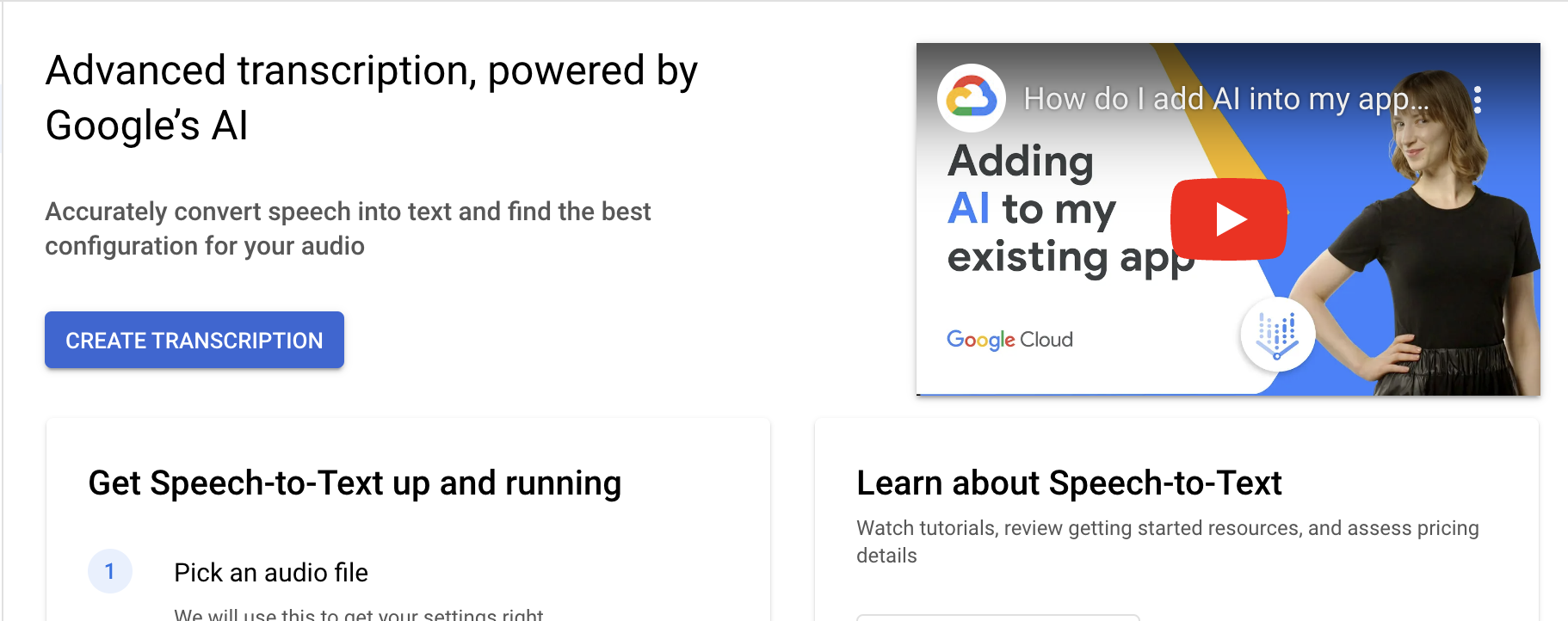
Hier erfahren Sie, wie Sie Speech-to-Text schnell und einfach für Ihre Anwendung mit Google Cloud aktivieren. In diesem Video erfahren Sie, wie Sie KI ohne umfassende Erfahrung mit ML-Modellen in Ihre Anwendung einbinden können. Mit der vortrainierten Speech-to-Text API aktivieren Sie schnell und einfach KI für Ihre Anwendung.
Tutorials, Kurzanleitungen und Labs
Speech-to-Text zu Anwendungen hinzufügen
Speech-to-Text zu Anwendungen hinzufügen
Hier erfahren Sie, wie Sie Speech-to-Text schnell und einfach für Ihre Anwendung mit Google Cloud aktivieren. In diesem Video erfahren Sie, wie Sie KI ohne umfassende Erfahrung mit ML-Modellen in Ihre Anwendung einbinden können. Mit der vortrainierten Speech-to-Text API aktivieren Sie schnell und einfach KI für Ihre Anwendung.
Audio in Text übersetzen
Sprache, Text und Übersetzung mit Google Cloud APIs
Sprache, Text und Übersetzung mit Google Cloud APIs
In diesem Kurs verwenden Sie die Speech-to-Text API, um eine Audiodatei in eine Textdatei zu transkribieren, mit der Google Cloud Translation API zu übersetzen und mit Natural Language KI synthetische Sprache zu erstellen.
Tutorials, Kurzanleitungen und Labs
Sprache, Text und Übersetzung mit Google Cloud APIs
Sprache, Text und Übersetzung mit Google Cloud APIs
In diesem Kurs verwenden Sie die Speech-to-Text API, um eine Audiodatei in eine Textdatei zu transkribieren, mit der Google Cloud Translation API zu übersetzen und mit Natural Language KI synthetische Sprache zu erstellen.
Preise
| Preisübersicht für Speech-to-Text | Die Preise für Speech-to-Text richten sich nach der API-Version, den Kanälen, Batchmethoden und etwaigen zusätzlichen Kosten für Google Cloud-Dienste wie Speicher. | |
|---|---|---|
| API-Version | Dienst und Funktion | Preise |
Speech-to-Text V1 API | V1 bietet den Datenstandort nur für mehrere Regionen. Zu den Modellen gehören kurz, lang, Telefonanruf und Video. V1 enthält kein Audit-Logging.Neukunden erhalten ein Guthaben von 300 $ und ein kostenloses Guthaben für 60 Minuten pro Monat für das Transkribieren und Analysieren von Audioinhalten. Es wird nicht mit Ihrem Guthaben verrechnet. | 0,024 $ pro Min. |
Speech-to-Text V2 API | V2 bietet einen Datenstandort für mehrere und einzelne Regionen. Zu den Modellen gehören kurz, lang, Telefonie, Video und Chirp. V2 umfasst Audit-Logging und Unterstützung für vom Kunden verwaltete Verschlüsselungsschlüssel. | 0,016 $ pro Min. |
Preisübersicht für Speech-to-Text
Die Preise für Speech-to-Text richten sich nach der API-Version, den Kanälen, Batchmethoden und etwaigen zusätzlichen Kosten für Google Cloud-Dienste wie Speicher.
Speech-to-Text V1 API
V1 bietet den Datenstandort nur für mehrere Regionen. Zu den Modellen gehören kurz, lang, Telefonanruf und Video. V1 enthält kein Audit-Logging.Neukunden erhalten ein Guthaben von 300 $ und ein kostenloses Guthaben für 60 Minuten pro Monat für das Transkribieren und Analysieren von Audioinhalten. Es wird nicht mit Ihrem Guthaben verrechnet.
0,024 $
pro Min.
Speech-to-Text V2 API
V2 bietet einen Datenstandort für mehrere und einzelne Regionen. Zu den Modellen gehören kurz, lang, Telefonie, Video und Chirp. V2 umfasst Audit-Logging und Unterstützung für vom Kunden verwaltete Verschlüsselungsschlüssel.
0,016 $
pro Min.