Distribució beta
| No s'ha de confondre amb funció beta. |
 | |
Funció de distribució de probabilitat  | |
| Tipus | família exponencial, Distribució beta no central, distribució lambda de Wilks, Distribució de Dirichlet, distribució univariant i distribució de probabilitat contínua |
|---|---|
| Notació | Beta(α, β) |
| Paràmetres | α > 0 forma (real) β > 0 forma (real) |
| Suport | or |
| fdp | on |
| FD | |
| Esperança matemàtica | (vegeu funció digamma i vegeu secció: mitjana geomètrica) |
| Mediana | |
| Moda | = per α, β > 1
qualsevol valor en per α, β = 1 {0, 1} (bimodal) per α, β < 1 0 per α ≤ 1, β > 1 1 per α > 1, β ≤ 1 |
| Variància | (vegeu funció trigamma i vegeu secció: Variància geomètrica) |
| Coeficient de simetria | |
| Curtosi | |
| Entropia | |
| FC | (vegeu funció hipergeomètrica confluent) |
| Mathworld | BetaDistribution |
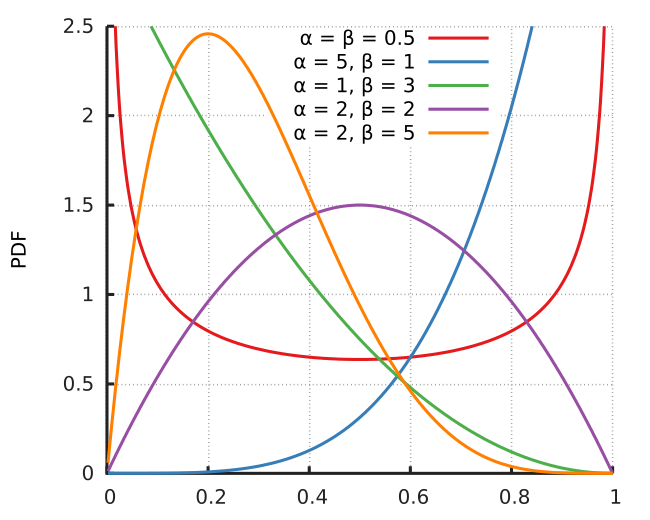
En teoria de la probabilitat i estadística, la distribució beta és una família de distribucions de probabilitat contínues definides en l'interval [0, 1], parametritzades per dos paràmetres de forma, denotats α i β, que apareixen com a exponents de la variable aleatòria i controlen la forma de la distribució. Es tracta d'un cas especial de la distribució de Dirichlet.
La distribució beta ha estat aplicada per modelar el comportament de variables aleatòries limitades a intervals de longitud finita en una àmplia varietat de disciplines.
En inferència bayesiana, la distribució beta és la distribució anterior conjugada de la distribució de Bernoulli, la distribució binomial, la binomial negativa, i la distribució geomètrica. Per exemple, la distribució beta pot ser usada en anàlisi bayesiana per descriure el coneixement inicial sobre la probabilitat d'èxit com ara la probabilitat que una nau espacial completi una missió específica. La distribució beta és, a més, un model vàlid per al comportament aleatori de percentatges i proporcions.
La formulació habitual de la distribució beta és també coneguda com a distribució beta de primer tipus, mentre que el terme distribució beta de segon tipus fa referència a la distribució beta prima.
Caracterització
[modifica]Funció de densitat de probabilitat
[modifica]La funció de densitat de probabilitat (fdp) de la distribució beta, per 0 ≤ x ≤ 1, i paràmetres de forma α, β > 0, és una funció potència de la variable x i de la seva reflexió (1 − x) com segueix::
on Γ(z) és la funció gamma. La funció beta, , és una constant de normalització per assegurarar que la probabilitat total és 1.
Aquesta definició inclou tots dos extrems x = 0 i x = 1, cosa que és consistent amb les definicions d'altres distribucions contínues que tenen com a domini un interval fitat i que són casos especials de la distribució beta, com per exemple la distribució arcsinus, i és consistent a més amb diversos autors, com Norman Lloyd Johnson i Samuel Kotz.[1][2][3][4] Tanmateix, la inclusió de x = 0 i x = 1 no funciona per α, β < 1; en conseqüència, diversos altres autors, com ara William Feller,[5][6][7] van triar excloure els extrems x = 0 i x = 1, (de tal manera que els dos extrems no formen part de fet del domini de la funció de densitat) i consideren doncs 0 < x < 1.
Diversos autors, com ara Norman Lloyd Johnson i Samuel Kotz,[1] usen el símbols p i q (enlloc de α i β) pels paràmetres de forma de la distribució beta, reminiscència dels símbols usats tradicionalment en la distribució de Bernoulli, ja que la distribució beta tendeix a ser igual a la de Bernoulli en el límit en què els paràmetres de forma α i β s'apropen al valor de zero.
A partir d'ara, una variable aleatòria X distribuïda segons beta amb paràmetres α i β serà denotada:[8][9]
Altres notació per una variable aleatòria distribuïda segons beta usades en literatura estocàstica són [10] i .[5]
Funció de distribució acumulada
[modifica]

La funció de distribució acumulada de la distribució beta és:
on és la funció beta incompleta i és la funció beta incompleta normalitzada.
Distribució beta amb quatre paràmetres
[modifica]Johnson et al [11] introdueixen la distribució beta amb quatre paràmetres mitjançant la funció de densitaton . Designarem aquesta distribució per . El cas anterior correspon a , que Johnson et al.[11] anomenen la distribució beta estàndard amb paràmetres . D'altra banda, si i definimalehores . La distribució inclou la distribució arcsinus amb suport en qualsevol interval afitat i la distribució del semicercle de Wigner
En tota la resta d'aquest article considerarem només el cas estàndard .
Propietats
[modifica]Mesures de tendència central
[modifica]Moda
[modifica]La moda d'una variable aleatòria amb distribució beta X amb α, β > 1 és el valor més probable de la distribució (i correspon al pic de la FDP), i ve donat per la següent expressió:[1]
Quant tos dos paràmetres són menors que u (α, β < 1), aquest valor correspon a l'anti-moda, el punt amb més baixa probabilitat.[3]
Si α = β, l'expressió de la moda se simplifica a 1/2, mostrant que per α = β > 1 la moda (o l'anti-moda quan α, β < 1), es troba al centre de la distribució: és simètrica en aquests casos. Vegeu la secció Formes en aquest article per una llista completa de casos de la moda, per valors arbitararis de α i β. En diversos d'aquests casos, el valor màxim de la funció de densitat es dona en un dels dos extrems. En alguns casos el valor (màxim) de la funció densitat en el final és finit. Per exemple, en el cas de α = 2, β = 1 (o α = 1, β = 2), la funció de densitat es converteix en la distribució triangular que és finita en tots dos extrems. En diversos altres casos, hi ha una singularitat matemàtica en un dels extrems, on el valor de la funció densitat tendeix a infinit. Per exemple, en el cas α = β = 1/2, la distribució beta se simplifica i es converteix en la distribució arcsinus. Hi ha un debat en la comunitat de matemàtics sobre alguns d'aquests casos i sobre si els extrems (x = 0, i x = 1) poden considerar-se o no modes:[6][8]

- Sobre si els extrems són part o no del domini de la funció densitat.
- Sobre si una singularitat es pot anomenar mai moda.
- Sobre si casos amb dos màxims es poden anomenar bimodals.
Mediana
[modifica]

La mediana de la distribució beta és un únic nombre real pel qual la funció beta incompleta . No hi ha una forma tancada general per la mediana de la distribució beta per valors arbitraris de α i β. Les formes tancades per valors particulars dels paràmetres α i β són:
- Per a casos simètrics en què α = β, la mediana és = 1/2.
- Per α = 1 i β > 0, la mediana és (aquest cas és l'imatge especular de la distribució de la funció potència [0,1])
- Per α > 0 i β = 1, la mediana val = (aquest cas és la distribució de la funció potència [0,1] distribution[6])
- Per α = 3 i β = 2, la mediana val 0.6142724318676105..., la solució real de la funció quàrtica 1 − 8x3 + 6x4 = 0, que es troba en l'interval [0,1].
- Per α = 2 i β = 3, la mediana val 0.38572756813238945... = 1−median(Beta(3, 2))
Les següents són les cotes quan un dels paràmetres és finit (no zero) i l'altre tendeix als límits:
Una aproximació raonable del valor de la mediana de la distribució beta, per tant α i β majors o iguals a u, ve donada per la fórmula:[12]
Quan α, β ≥ 1, l'error relatiu (que en aquest cas és l'error d'aproximació dividit entre la mediana) en aquesta aproximació és menor que el 4% i per tant α ≥ 2 i β ≥ 2 és menor que l'1%. L'error absolut dividit entre la diferència entre la mitjana i la moda és similarment baix:
![Abs[(aproximació de la mediana)/mediana] per distribucions beta amb 1 ≤ α ≤ 5 i 1 ≤ β ≤ 5](http://upload.wikimedia.org/wikipedia/commons/a/af/Relative_Error_for_Approximation_to_Median_of_Beta_Distribution_for_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg)
![Abs[(aproximació de la mediana)/(mitjana - moda)] per distribucions beta amb 1 ≤ α ≤ 5 i 1 ≤ β ≤ 5](http://upload.wikimedia.org/wikipedia/commons/thumb/e/e8/Error_in_Median_Apprx._relative_to_Mean-Mode_distance_for_Beta_Distribution_with_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg/650px-Error_in_Median_Apprx._relative_to_Mean-Mode_distance_for_Beta_Distribution_with_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg)
Mitjana
[modifica]
El valor esperat (o mitjana) (μ) d'una variable aleatòria que segueix la distribució beta X amb els dos paràmetres α i β és una funció només del ràtio β/α d'aquests paràmetres:[1]
Sigui α = β, en aquesta expressió s'obté μ = 1/2, mostrant que per α = β la mitjana es troba en el centre de la distribució: és simètrica. A més, es poden obtenir els següents límits a partir d'aquesta expressió:
Per tant, per β/α → 0, o per α/β → ∞, la mitjana es troba en l'extrem dret, x = 1. En aquests casos límit, la distribució beta es converteix en una distribució degenerada d'un sol punt amb una delta de Dirac centrada en l'extrem dret x = 1, amb probabilitat 1, i probabilitat zero per a la resta de valors. Hi ha un 100% de probabilitat (certesa absoluta) concentrada en l'extrem dret de l'interval, x = 1.
De manera similar, per β/α → ∞ o, cosa que és el mateix per α/β → 0, la mitjana es troba en l'extrem esquerre, x = 0. La distribució beta esdevé una distribució degenerada d'un sol punt amb una delta de Dirac centrada en l'extrem esquerre x = 0, amb probabilitat 1, i amb probabilitat zero altrament. En aquest cas hi ha un 100% de probabilitat (certesa absoluta) en l'extrem esquerre, x = 0. A continuació es mostren els límits quan un dels dos paràmetres és un nombre finit (no zero) i l'altre paràmetre tendeix a zero o infinit:
Mentre que per les distribucions unimodals típiques (amb modes localitzades al centre i punts d'inflexió en tots dos costats de la moda i cues més llargues) (amb Beta(α, β) tal que α, β > 2) se sap que la mitjana de la mostra no és tan robusta com la mediana; el cas contrari es dona en les distribucions bimodals en forma d'U (amb Beta(α, β) tal que α, β ≤ 1), amb les modes localitzades en els extrems de la distribució. Com Mosteller i Tukey van remarcar ([13] p. 207) "la mitjana de les observacions en els dos extrems usa tota la informació de la mostra. Això il·lustra com, per distribucions amb cua curta, les observacions dels extrems haurien de tenir més pes." Per contra, segueix que la mitjana de les distribucions bimodals amb modes en els extrems de la distribució (amb Beta(α, β) tal que α, β ≤ 1) no és robusta, ja que la mediana de la mostra rebaixa les observacions en l'extrem de la mostra a considerar. Una aplicació pràctica d'això és per exemple la dels camins aleatoris, ja que la probabilitat del temps des de l'últim pas per l'origen segueix una distribució arcsinus Beta(1/2, 1/2):[5][14] la mitjana en el nombre de realitzacions en un camí aleatori és un estimador molt més robust que la mediana (que és un estimador de mesura de la mostra inapropiat en aquest cas).
Mitjana geomètrica
[modifica]


El logaritme de la mitjana geomètrica GX d'una distribució amb variable aleatòria X és la mitjana aritmètica de ln(X) o, cosa que és el mateix, el seu valor esperat és:
En una distribució beta, la integral del valor esperat dona:
on ψ és la funció digamma.
Per tant, la mitjana geomètrica de la distribució beta amb paràmetres de forma α i β és l'exponencial de les funcions digamma de α i β com segueix:
Mentre que en la distribució beta amb paràmetres de forma iguals α = β, la simetria és 0 i la moda és igual a la mitjana i a la mediana i val 1/2, la mitjana geomètrica és menys de 1/2: 0 < GX < 1/2. La raó d'això és el fet que la transformació logarítmica dona molt més pes als valors de X propers al zero, ja que ln(X) tendeix fortament a menys infinit a mesura que X s'apropa a zero, mentre que ln(X) esdevé més pla cap al zero a mesura que X → 1.
A través de la línia α = β, es compleixen els següents límits:
A continuació es mostren els límits quan un dels dos paràmetres és un nombre finit (no zero) i l'altre paràmetre tendeix a zero o infinit:
Les gràfiques que es mostren a la dreta mostren la diferència entre la mitjana i la mitjana geomètrica per paràmetres de forma α i β del zero al 2. A més del fet que la diferència entre ells s'apropi al zero a mesura que α i β van cap a l'infinit i que la diferència es torni més granper valors de α i β propers a zero, es pot observar una asimetria evident de la mitjana geomètrica respecte als paràmetres de forma α i β. La diferència entre la mitjana geomètrica i la mitjana és més gran per valors petits de α respecte β que quan s'intercanvien els valors de β i α.
Norman Lloyd Johnson i Samuel Kotz[1] van suggerir l'aproximació logarítimica a la funció digamma ψ(α) ≈ ln(α − 1/2) que resulta en la següent aproximació a la mitjana geomètrica:
Valors numèrics de l'error d'aproximació en aquesta aproximació són:: [(α = β = 1): 9.39%]; [(α = β = 2): 1.29%]; [(α = 2, β = 3): 1.51%]; [(α = 3, β = 2): 0.44%]; [(α = β = 3): 0.51%]; [(α = β = 4): 0.26%]; [(α = 3, β = 4): 0.55%]; [(α = 4, β = 3): 0.24%].
De manera similar, es pot calcular el valor dels paràmetres de forma requerits per tal que la mitjana geomètrica valgui 1/2. Donat un valor del paràmetre β, quin hauria de ser el valor de l'altre paràmetre, α, tal que la mitjana geomètrica de la variable aleatòria fos 1/2?. La resposta és que (per β > 1), el valor de α requerit tendeix a β + 1/2 a mesura que β → ∞. Per exemple, totes aquestes parelles tenen la mateixa mitjana geomètrica de 1/2: [β = 1, α = 1.4427], [β = 2, α = 2.46958], [β = 3, α = 3.47943], [β = 4, α = 4.48449], [β = 5, α = 5.48756], [β = 10, α = 10.4938], [β = 100, α = 100.499].
La propietat fonamental de la mitjana geomètrica, que pot ser demostrada de no complir-se per qualsevol altre tipus de mitjana, és:
Això fa que la mitjana geomètrica sigui la única mitjana correcta quan es promitgen resultats normalitzats, és a dir resultats que són presentats com ratios respecte valors referència.[15] Això és relevant, ja que la distribució beta és un model escaient en el comportament aleatori de percentatges i és particularment oportú en la màxima versemblança en el modelatge estadístic de proporcions. La mitjana geomètrica té un paper cabdal en l'estimació de màxima probabilitat, vegeu la secció Màxima semblança. De fet, quan es fa l'estimació de màxima probabilitat, a més de la mitjana geomètrica GX basada en la variable aleatòria X, també apareix de manera natural una altra mitjana geomètrica: la que es basa en la transformació lineal ––(1 − X), la imatge mirall de X, denotada G(1−X):
A través d'una línia α = β, es compleixen els següents límits:
A continuació es mostren els límits quan un dels dos paràmetres és un nombre finit (no zero) i l'altre paràmetre tendeix a zero o infinit:
Té el següent valor aproximat:
Tot i que tant GX com G(1−X) són asimètrques, en el cas que tots dos paràmetres de forma siguin inguals α = β, les mitjana geomètriques són iguals: GX = G(1−X). Aquesta igualtat prové de la següent simetria mostrada entre totes dues mitjanes geomètriques:
Mitjana harmònica
[modifica]



La inversa de la mitjana harmònica (HX) d'una distribució amb variable aletòria X és la mitjana aritmètica de 1/X o, cosa que és el mateix, el seu valor esperat. Per tant, la mitjana harmònica (HX) d'una distribució beta amb paràmetres de forma α i β és:
La mitjana harmònica (HX) de la distribució beta amb α < 1 no està definida, ja que l'expressió que la defineix no està definida en l'interval [0, 1] per valors del paràmetre α inferiors a la unitat.
Sigui α = β en l'expressió superior, s'obté:
demostrant que per α = β la mitjana harmònica va de 0, per α = β = 1, fins a 1/2, per α = β → ∞.
A continuació es mostren els límits quan un dels dos paràmetres és un nombre finit (no zero) i l'altre paràmetre tendeix a zero o infinit:
La mitjana harmònica té un paper important en l'estimació de màxima probabilitat en el cas dels quatre paràmetres, a més de la mitjana geomètrica. De fet, quan es fa estimació de màxima probabilitat en el cas dels quatre paràmetres, a part de la mitjana harmònica HX de la variable aleatòria X, també apareix una altra mitjana harmònica de manera natural: la mitjana harmònica de la transformació lineal (1 − X), la imatge mirall de X, denotada H1 − X:
La mitjana harmònica (H(1 − X)) d'una distribució beta amb β < 1 no està definida, per la mateixa raó que abans, amb el cas de α.
Sigui α = β en l'expressió superior, s'obté:
demostrant que per α = β la mitjana harmònica va de 0, per α = β = 1, fins a 1/2, per α = β → ∞.
A continuació es mostren els límits quan un dels dos paràmetres és un nombre finit (no zero) i l'altre paràmetre tendeix a zero o infinit, en aquest cas per una variable aleatòria 1-x:
Malgrat que tant HX com H1−X són asimètrics, en el cas que els paràmetres de forma de tots dos siguin iguals α = β, les seves mitjanes harmòniques seran iguals: HX = H1−X. Aquesta igualtat es desprèn de la següent simetria que mostren totes dues mitjanes harmòniques:
Mesures de dispersió estadística
[modifica]Variància
[modifica]
La variància (el segon moment centrat en la mitjana) d'una variable aleatòria segons la distribució beta X amb paràmetres α i β és:[1][16]
Sigui α = β, en l'expressió superior s'obté:
fent palès que, per α = β, la variància decreix monòtonament a mesura que el valor de α = β augmenta. Quan α = β = 0 en l'expressió, es troba la màxima variància var(X) = 1/4[1] que només es dona en aquest límit, a α = β = 0.
La distribució beta pot també ser parametritzada en termes de la seva mitjana μ (0 < μ < 1) i mida de la mostra ν = α + β (ν > 0) (vegeu secció anomenada "Mitjana i mida de la mostra", més avall):
Usant aquesta paramatrització, es pot expressar la variància en termes de la mitjana μ i la mida de la mostra ν com segueix:
Com que ν = (α + β) > 0, s'ha de complir que var(X) < μ(1 − μ).
En en el cas de distribució simètrica, la mitjana es troba en el mig de la distribució, μ = 1/2, i per tant:
A més, els següents límits (en què només la variable indicada tendeix al límit) es poden obtenir a partir de l'expressió superior:
Variància geomètrica i covariància
[modifica]

El logaritme de la variància geomètrica, ln(varGX), d'una distribució amb variable aleatòria X és el segon moment del logaritme de X centrat en la mitjana geomètrica de X, ln(GX):
i per tant, la variància geomètrica és:
En la matriu d'informació de Fisher, i en la curvatura del logaritme de la funció de verosimilitud, el logaritme de la variància geomètrica de la variable reflectida 1 − X i el logaritme de la covariància geomètrica entre X i 1 − X apareix:
En la distribució beta, es poden derivar moments logarítmics d'ordre superior usant la representació de la distribució beta com a proporció de dues distribucions Gamma i diferenciant al llarg de la integral. Es poden expressar també en termes de funcions poli-gamma d'ordre superior. Vegeu la secció "Altres moments, Moments de variables aleatòries transformades, Moments de variables aleatòries transformades logarítmicament". La variància de les variables logarítmiques i la covariància de ln X i ln(1−X) són:
on la funció trigamma, denotada ψ1(α), és la segona de les funcions poligamma, i és definida com lal derivada de la funció digamma:
Per tant,
Les gràfiques mostren el logaritme de les variàncies geomètriques i el logaritme de les covariàncies geomètriques versus els paràmetres de forma α i β. Les gràfiques mostren que el logaritme de les variàncies geomètriques i el logaritme de les covariàncies geomètriques són propers a zero per valors de α i β superiors a 2, i que el logaritme de les variàncies geomètriques augmenta ràpidament de valor per valors dels paràmetres de forma α i β inferiors a la unitat. El logaritme de les variàncies geomètriques és positiu per tots els valors dels paràmetres de forma. El logaritme de la covariància geomètrica és negatiu per tots els valors dels paràmetres de forma, i arriba a nombres negatius grans per valors de α i β inferiors a la unitat.
A continuació es mostren els límits quan un dels dos paràmetres és un nombre finit (no zero) i l'altre paràmetre tendeix a zero o infinit:
I a continuació els límits quan tots dos paràmetres varien:
Tot i que tant ln(varGX) com ln(varG(1 − X)) són asimètrics, quan els paràmtres de forma són d'igual valor, α = β, es té: ln(varGX) = ln(varG(1−X)). Aquesta igualtat segueix de la següent simetria que es mostra en el logaritme de les variàncies geomètriques:
El logaritme de la covariància geomètrica és simètric:
Desviació mitjana respecte la mitjana
[modifica]

La desviació mitjana respecte la mitjana de la distribució beta amb paràmetres de forma α i β és:[6]
La desciació mitjana respecte la mitjana és un estimador estadístic més robust de la dispersió estadística que la desviació estànderd en la distribució beta amb cues i punts d'inflexió a cada costat de la moda, distribucions Beta(α, β) amb α,β > 2, ja que depèn de la desviació (absoluta) lineal enlloc de dependre en la desviació quadràtica respecte la mitjana. Per tant, a l'efecte de desviacions molt grans respecte la mitjana no se'ls dona tant pes.
Usant l'aproximació de Stirling de la funció gamma, Norman Lloyd Johnson i Samuel Kotz[1] van derivar la següent aproximació per valors dels paràmetres de forma superiors a la unitat (l'error relatiu en aquesta aproximació és només del -3.5% per α = β = 1, i decreix a zero a mesura que α → ∞, β → ∞):
En el límit α → ∞, β → ∞, el quocient entre desviació mitjana i la desviació estàndard (per a la distribució beta) es torna igual al ràtio de les mateixes mesures de la distribució normal: . Quan α = β = 1 aquest ràtio és igual a , així que de α = β = 1 a α, β → ∞ el quocient decreix en un 8.5%. Quan α = β = 0 la desviació estàndard és exactament igual a la desviació mitjana respecte la mitjana. I, per tant, aquest ràtio decreix en un 15% de α = β = 0 a α = β = 1, i en un 25% de α = β = 0 a α, β → ∞. Tanmateix, per distribucions beta asimètriques tals que α → 0 o β → 0, el ràtio entre la desviació estàndard i la desviació mitjana tendeix a infinit (tot i que cadascuna d'elles, individualment, s'apropen a zero), ja que la desviació mitjana s'apropa a zero molt més ràpidament que la desviació estàndard.
Usant la parametrització en termes de la mitjana μ i la mida de la mostra ν = α + β > 0:
- α = μν, β = (1−μ)ν
es pot expressar la desviació mitjana respecte la mitjana en termes de la mitjana μ i de la mida de la mostra ν com segueix:
En el cas que la distribució sigui simètrica, la mitjana es troba al mig de la distribució, μ = 1/2, i per tant:
També, els següents límits (en què només la variable marcada tendeix als límits) es poden obtenir a partir de les expressions superiors:
Diferència absoluta mitjana
[modifica]La diferència absoluta mitjana de la distribució beta és:
El coeficient de Gini de la distribució beta és la meitat de la diferència absoluta mitajana relativa:
Asimetria
[modifica]
L'asimetria (el tercer moment centrat en la mitjana, notmalitzat per la variància elevada a 3/2) de la distribució beta és:[1]
Sigui α = β en l'expressió superior s'obté γ1 = 0, mostrant un altre cop que per α = β la distribució és simètrica i per tant l'asimetria és zero. Es dóns asimetria positiva (amb cua a la dreta) per α < β, i asimetria negativa (cua a l'esquerra) per α > β.
Usant la parametrització en termes de la mitjana μ i la mida de la mostra ν = α + β:
es pot expressar l'asimetria en aquests termes com es mostra a continuació:
L'asimetria també es pot expressar només en termes de la variància var i de la mitjana μ com segueix:
La gràfica de l'asimetria en funció de la variància i la mitjana que acompanya el text mostra que la màxima variància (1/4) va lligada amb asimetria zero i amb la condició de simetria (μ = 1/2), i la màxima simetria (infinit positiu o negatiu) es dona quan la mitjana es troba en un dels dos extrems, talment que la "massa" de la distribució de probabilitat es concentra en els dos extrems (mínima variància).
La següent expressió pel quadrat de l'asimetria, en termes de la mida de la mostra ν = α + β i la variància var, és útil en el mètode d'estimació de moments de quatre paràmetres:
Aquesta expressió dona correctament una asimetria de zero per α = β, ja que en aquest cas (vegeu la secció "Variància"): .
En el cas simètric (α = β), l'asimetria = 0 en tot el domini, i els següents límits apliquen:
En els casos asimètrics (α ≠ β) apliquen els següents límits (en què només la variable indicada tendeix als límits), que poden ser derivats de l'expressió superior:


Curtosi
[modifica]Funció característica
[modifica]




La funció característica és la transformada de Fourier de la funció densitat de probabilitat. La funció característica de la distribució beta és la funció hipergeomètrica confluent de Kummer (de primer tipus):[1][17][18]
on:
és el factorial ascendent, també anomenat "símbol de Pochhammer". El valor de la funció característica per t = 0, és la unitat:
- .
A més, les parts reals i imaginàries de la funció característica tenen les següents simetris respecte l'origen de la variable t:
El cas simètric α = β simplifica la funció característica de la distribució beta a una funció de Bessel, ja que en el cas especial case α + β = 2α la funció hipergeomètrica confluent (de primer tipus) es redueix a una funció de Bessel (la funció´modificada de Bessel de primer tipus ) usant la segona transformada de Kummer's com segueix:
En les gràfiques que acompanyen el text, la part real (Re) de la funció característica de la distribució beta es mostra pel cas simètric (α = β) i l'asimètric (α ≠ β).
Altres moments
[modifica]Funció generadora de moment
[modifica]També segueix[1][6] que la funció generadora de moments de la distribució beta és:
En particular MX(α; β; 0) = 1.
Moments superiors
[modifica]Utilitzant la funció generadora de moments, el moment k-èssim ve donat pel factor:[1]
multiplicant el terme (de la sèrie exponencial) en la sèrie de la funció generadora de moments:
on (x)(k) és un símbol de Pochhammer que representa un factorial creixent. També pot ser escrit de forma recursiva com:
Com que la funció generadora de moment té un radi de convergència positiu, la distribució beta és determinada pels seus moments.[19]
Moments de variables aleatòries transformades
[modifica]Transformacions lineals
[modifica]També es poden demostrar les següents esperances per les variables aleatòries,[1] en què la variable aleatòria X segueix la distribució beta amb paràmetres α i β: X ~ Beta(α, β). L'esperança estadística de la variable 1 − X és la simetria mirall de l'esperança de X:
A causa de la simetria-mirall de la funció de denistat de probabilitat de la distribució beta, les variances de les variables X i 1 − X són idèntiques, i la covariança de X(1 − X és la variància canviada de signe:
Aquestes són les esperances de les variables invertides, (que estan relacionades amb la mitjana harmònica, vegeu la secció "Mitjana harmònica"):
La següent transformació, consistent a dividir la variable X per la seva imatge-mirall X/(1 − X), dona com a resultat l'esperança de la "distribució beta invertida" o distribució beta prima (també coneguda com a distribució beta de segon tipus o distribució de Pearson de tipus VI):[1]
Les variàncies d'aquestes variables transformades es poden obtenir per integració, com les esperances dels segons moments centrats en les variables corresponents:
La següent variància de la variable X dividida per la imatge-mirall (X/(1−X) resulta en la variància de la "distribució beta invertida:[1]
Les covariàncies són:
Aquestes esperances i variàncies apareixen en la matriu d'informació de Fisher de quatre paràmetres (vegeu secció "Informació de Fisher," "quatre paràmetres")
Transformacions logarítmiques
[modifica]
En aquesta secció es parla de l'esperança de les transformacions logarítmiques (útils en estimacions de màxima versemblança, vegeu la secció que porta per títol Màxima versemblança). Les següents transformacions lineals logarítmiques estan relacionades amb les mitjanes geomètriques GX i G(1−X) (vegi's secció "Mitjana geomètrica"):
On la funció digamma ψ(α) és definida com la derivada logarítmica de la funció gamma:[17]
Les transformacions logit són interessants,[20] ja que normalment transformen diverses formes (inclús formes de J) en densitats en forma de campana respecte la variable logit (normalment asimètriques), i poden desfer-se de les singularitats en la variable original:
Johnson[21] va considerar la distribució de la variable logit transformada ln(X/1−X), inclosa la seva funció generadora de moment i aproximacions per valors grans dels paràmetres de forma. Aquesta transformació estén el domini finit [0, 1] en què es basa la variable original X a un domini infinit en totes dues direccions de la recta dels reals (−∞, +∞).
Es poden derivar moments logarítmics d'ordre superior utilitzant la representació de la distribució beta com a proporció de dues distribucions gamma i diferenciant al llarg de la integral. Es poden expressar en funció de funcions poli-gamma d'ordre superior com es mostra a continuació:
Per tant, la variància de les variables logarítmiques i la covariància de ln(X) i ln(1−X) són:
on la funció trigamma, anotada com ψ1(α), és la segona de les funcions poligamma, i és definida com la derivada de la funció digamma:
- .
Les variàncies i covariàncies de les variables logarítmicament transformades X i (1−X) són diferents, en general, perquè la transformació logarítmica destrueix la simetria de mirall de les variables originals X i (1−X), ja que el logaritme s'apropa a menys infinit quan la variable tendeix a zero.
Aquestes variàncies i covariàncies logarítmiques són els elements de la matriu d'informació de Fisher per a la distribució beta. També són una mesura de la curvatura de la funció log de versamblança.
Les variàncies de les variables log inverses són idèntiques a les variàncies de les variables log:
També segueix que les variàncies de les variables logit transformades són:
Quantitats d'informació (entropia)
[modifica]Donada una variable aleatòria que segueix una distribució beta, X ~ Beta(α, β), l'entropia de Shannon de X és[22](mesurada en nats), l'esperança de menys el logaritme de la funció de densitat de probabilitat:
on f(x; α, β) és la funció de densitat de probabilitat de la distribució beta:
La funció digamma ψ apareix en la fórmula de l'entropia de Shannon com a conseqüència de la fórmula integral d'Euler dels nombres harmònics que segueix de la integral:
L'entropia de Shannon de la distribució beta és negativa per valors d'α i β positius, excepte quan α = β = 1 (per aquests valors dels paràmetres, la distribució beta es converteix en la distribució uniforme contínua), quan l'entropia pren el seu valor màxim de zero. És d'esperar que el valor màxim de l'entropia es doni quan la distribució beta es converteix en la distribució uniforme, ja que la incertesa és màxima quan totes els esdeveniments són equiprobables.
Quan α o β s'apropen a zero, l'entropia tendeix al seu mínim, que té una valor de menys infinit. Per (un d'ells o tots dos) α o β s'apropen a zero, hi ha una mínima quantitat d'ordre: tota la densitat de probabilitat està concentrada en un dels extrems, i hi ha una densitat de probabilitat de zero en els punts que es troben entre els dos extrems. De manera semblant quan (un d'ells o tots dos) α o β s'apropen a infinit, l'entropia s'apropa al seu valor mínim de menys infinit, i a una quantitat màxima d'ordre. Si o bé α o bé β s'apropen a infinit (i l'altre és finit) tota la densitat de probabilitat es concentra en un dels extrems, i la densitat de probabilitat és zero en tota la resta del domini. Si tots dos paràmetres de forma són iguals (el cas simètric), α = β, i tendeixen a infinit de manera simultània, la densitat de probilitat esdevé punxa (una delta de Dirac) concentrada al mig x = 1/2, i llavors hi ha un 100% de probabilitat en el mig x = 1/2 i probabilitat zero a la resta del domini.


L'entropia (en el cas continu) va ser introduïda per Shannon en el seu article original (en el qual la va anomenar "entropia d'una distribució contínua"), en la secció de conclusions[23] del mateix article en el qual va definir l'entropia discreta. Des de llavors se sap que l'entropia de Shannon pot diferir del límit infinitesimal de l'entropia discreta per una diferència infinitèssima, per tant l'entropia de Shannon pot ser negativa (com ho és en la distribució beta). El que realment importa és el valor relatiu de l'entropia.
Donades dues variables aleatòries distribuïdes segons beta, X1 ~ Beta(α, β) i X₂ ~ Beta(α′, β′), l'entropia creuada és (mesurada en nats)[24]
L'entropia creuada ha estat usada com una mètrica de l'error per mesurar la distància entre dues hipòtesis.[25][26] El seu valor absolut és mínim quan les dues distribucions són idèntiques. És la mesura d'informació més estratament relacionada amb la log màxima probabilitat [24](vegi's secció sobre "Estimació paramètrica. Estimació de màxima probabilitat")).
L'entropia negativa, o divergència de Kullback-Leibler DKL(X1 || X₂), és una mesura de la ineficiència d'assumir que la distribució és X₂ ~ Beta(α′, β′) quan la distribució és realment X1 ~ Beta(α, β). És definida com (mesurada en nats).
L'entropia relativa, divergència de Kullback Leibler, és sempre no-negativa. AW continuació es mostren alguns exemples numèrics:
- X1 ~ Beta(1, 1) i X₂ ~ Beta(3, 3); DKL(X1 || X₂) = 0.598803; DKL(X₂ || X1) = 0.267864; h(X1) = 0; h(X₂) = −0.267864
- X1 ~ Beta(3, 0.5) i X₂ ~ Beta(0.5, 3); DKL(X1 || X₂) = 7.21574; DKL(X₂ || X1) = 7.21574; h(X1) = −1.10805; h(X₂) = −1.10805.
La divergència de Kullback Leibler no és simètrica DKL(X1 || X₂) ≠ DKL(X₂ || X1) en el cas en què les distribucions de beta individuals Beta(1, 1) i Beta(3, 3) són simètriques, però tenen entropies diferents h(X1) ≠ h(X₂). El valor de la divergència de Kullback Leibler depèn de la direcció en què es recorre: si es va d'entropia (de Shannon) més alta a entropia (de Shannon) més baixa o si es va a l'inrevés. En l'exemple numèric més amunt, la divergència de Kullback Leibler mesura la ineficiència d'assumir que la distribució és Beta(3, 3) amb forma de campana, enlloc de Beta(1, 1) uniforme. L'entropia "h" de Beta(1, 1) és més alta que l'entropia "h" de Beta(3, 3) ja que la distribució uniforme Beta(1, 1) té una quantitat de desordre màxima. La divergència de Kullback Leibler és més que dues vegades més gran (0.598803 enlloc de 0.267864) quan es mesura en la direcció d'entropia decreixent: la direcció que assumeix que la distribució Beta(1, 1) uniforme és Beta(3, 3) amb forma de campana enlloc del sentit invers. En aquest sentit concret, la divergència deKullback Leibler és consistent amb el segon principi de la termodinàmica.
La divergència de Kullback Leibler és simètrica DKL(X1 || X₂) = DKL(X₂ || X1) en els casos asimètrics Beta(3, 0.5) i Beta(0.5, 3) que tenen la mateixa entropia de Shannon h(X1) = h(X₂).
La condició de simetria:
segueix de les definicions superiors i de la simetria de mirall f(x; α, β) = f(1−x; α, β) que es dona en la distribució beta.
Relacions entre mesures estadístiques
[modifica]Relació entre mitjana, moda i mediana
[modifica]Si 1 < α < β llavors la moda ≤ mediana ≤ mitjana.[12] Expressant la moda (només per α, β > 1), i la mitjana en termes de α i β:
Si 1 < β < α llavors l'ordre de les inequacions és el contrari. Amb α, β > 1, la distància absoluta entre la mitjana i la mediana és menys que el 5% de la distància entre els valors màxim i mínim de x. D'altra banda, la distància absoluta entre la mitjana i la moda pot arribar al 50% de la distància entre el valor màxim i el mínim de x, pel cas (patològic) de α = 1 i β = 1 (els valors pel qual la distribució beta s'apropa a la distribució uniforme i l'entropia diferencial s'acosta al seu valor màxim, i per tant al màxim "desordre").
Per exemple, per α = 1.0001 i β = 1.00000001:
- moda = 0.9999; PDF(moda) = 1.00010
- mitjana = 0.500025; PDF(mitjana) = 1.00003
- mediana = 0.500035; PDF(mediana) = 1.00003
- mitjana − moda = −0.499875
- mitjana − mediana = −9.65538 × 10−6
(on PDF vol dir funció de densitat de probabilitat)


Relació entre mitjana, mitjana geomètrica i mitjana harmònica
[modifica]
És ben sabut a partir de la desigualtat entre les mitjanes aritmètica i geomètrica que la mitjana geomètrica és inferior a la mitjana aritmètica. De manera similar, la mitjana harmònica és inferior a la mitjana geomètrica. La figura a la dreta del text ho mostra per α = β, tant la mitjana com la mediana són exactament 1/2, independentment del valor de α = β, i la moda és també igual a 1/2 per α = β > 1, tanmateix la mitjana geomètrica i la mitjana harmònica són inferiors a 1/2 i només s'apropen al valor de la mitjana aritmètica de forma asimptòtica a mesura que α = β → ∞.
Curtosi fitada pel quadrat de l'asimetria
[modifica]
Com va assenyalar el matemàtic William Feller,[5] en la distribució de Pearson la densitat de probabilitat beta apareix com una distribució de tipus I (tota diferència entre la distribució beta i la distribució de Pearson de tipus I és només superficial i no hi fa cap diferència en la discussió següent, sobre la relació entre la curtosi i l'asimetria). Karl Pearson va mostrar, en el Plate 1 del seu article[27] publicat l'any 1916, un gràfica amb la curtosi a l'eix vertical (d'ordenades) i el quadrat de l'asimetria en l'eix horitzontal (d'abscisses), en el qual es mostraven diverses distribucions.[28] La regió ocupada per la distribució beta està fitada per les dues següents rectes en el pla (asimetria², curtosi), o en el pla (asimetria², excés de curtosi):
o, de manera equivalent,
(En els temps en què no hi havia ordinadors digitals potents), Karl Pearson va calcular de manera precisa fites més ambicioses,[4][27] per exemple, separant les formes d'"U" de les formes de "J" de la distribució. La recta que fa de inferior (excés de curtosi + 2 − asimetria² = 0) és produïda per les distribucions beta asimètriques en forma d'"U" en què tots dos valors dels paràmetres de forma α i β són propers a zero. La recta que fa de fita superior (excés de curtosi − (3/2) asimetria² = 0) és produïda per les distribucions extremadament asimètriques en què un dels valors dels dos paràmetres és molt alt i l'altre és molt baix. Karl Pearson va mostrar[27] que aquesta recta de fita superior (excés de curtosi − (3/2) asimetria² = 0) és també la intersecció amb la distribució de Pearson de tipus III, que té un domini no limitat en una direcció (cap a més infinit), i pot tenir forma de campana o de J. El seu fill, Egon Pearson, va demostrar[28] que la regió (en el pla curtosi/quadrat de l'asimetria) ocupat per la distribució beta (equivalentment, la distribució de Pearson de tipus I) a mesura que s'apropa a la seva frontera (excés de curtosi − (3/2) asimetria² = 0) la comparteix amb la distribució khi no centrada. Karl Pearson[29] (Pearson 1895, pp. 357, 360, 373–376) també va demostrar que la distribució gamma és una distribució de Pearson de tipus III. És per això que la recta frontera de la distribució de tipus III de Pearson és coneguda com la recta gamma. (Això es pot concloure del fet que l'excés de curtosi de la distribució gamma és 6/k i el quadrat de l'asimetria és 4/k, per tant (excés de curtosi − (3/2) asimetria² = 0) se satisfà de forma idèntica en la distribució gamma independentment del valor del paràmetre "k"). Més tard, Pearson va observar que la distribució khi quadrat és un cas especial de la distribució de Pearson de tipus III i també comparteix aquesta recta de frontera (com és aparent del fet que per la distribució khi quadrat l'excés de curtosi és 12/k i el quadrat de l'asimetria és 8/k, per tant (excés de curtosi − (3/2) asimetria² = 0) se satisfà igualment independentment del paràmetre "k"). Això és el que s'espera, ja que la distribució khi quadrat since X ~ χ²(k) és un cas especial de la distribució gamma, amb parametrització X ~ Γ(k/2, 1/2) on k és un nombre enter positiu que especifica el "nombre de graus de llibertat" de la distribució khi quadrat.
Un exemple d'una distribució beta propera a la frontera superior (excés de curtosi − (3/2) asimetria² = 0) ve donada per α = 0.1, β = 1000, per la qual el ratio (excés de curtosi)/(asimetria²) = 1.49835 s'apropa al límit superior de 1.5. Un exemple de distribució beta propera a la frontera inferior (excés de curtosi + 2 − asimetria² = 0) és donat per α= 0.0001, β = 0.1, valors pels quals l'expressió (excés de curtosi + 2)/(asimetria²) = 1.01621 s'apropa al límit inferior de 1. En el límit infinitessimal tant per α com per β quan s'apropen a zero simètricament, l'excés de curtosi arriba al seu valor mínim de −2. Aquest valor mínim es dona quan la recta frontera inferior intersecta l'eix vertical (d'ordenades). (Tanmateix, en la gràfica original de Pearson, les ordenades són la curtosi, i no excés de curtosi, i augmenta cap avall i no cap a dalt).
Valors de l'asimetria i de l'excés de curtosi sota la frontera inferior (excés de curtosi + 2 − asimetria² = 0) no es poden donar per cap distribució, i per tant Karl Pearson va anomenar-la de forma convenient "regió impossible." La frontera d'aquesta "regió impossible" ve determinada per les distribucions (simètriques o asimètriques) bimodals en forma d'"U" per les quals els paràmetres α i β s'apropen a zero i per tant tota la densitat de probabilitat està concentrada en els extrems: x = 0, 1 amb pràctiment res en comú entre elles. Com que per α ≈ β ≈ 0 la densitat de probabilitat està concentrada en els dos extrems x = 0 i x = 1, aquesta "frontera impossible" ve determinada per una distribució de 2 punts: la probabilitat només pot prendre 2 valors (distribució de Bernoulli), un dels dos valors té probabilitat p i l'altre té probabilitat q = 1−p. En els casos propers a aquesta frontera amb simetria α = β, l'asimetria és ≈ 0, l'excés de curtosi ≈ −2 (aquesta és el valor més baix possible d'excés de curtosi per cap distribució), i les probabilitats són p ≈ q ≈ 1/2. En els casos propers a aquesta frontera amb asimetria, l'excés de curtosi és ≈ −2 + asimetria², i la densitat de probabilitat està més concentrada en un dels extrems que en l'altre (amb gairebé res entre mig), amb probabilitat a l'extrem esquerre x = 0 i amb probabilitat a l'extrem dret x = 1.
Simetria
[modifica]Totes les afirmacions que segueixen estan condicionades al fet que α, β > 0. Existeix simetria en:
- Funció de densitat de probabilitat simetria de reflexió:
- Funció de distribució acumulada simetria i translació unitària:
- Moda simetria i translació unitària:
- Mediana simetria i translació unitària:
- Mitjana simetria i translació unitària:
- Mitjanes geomètriques cadascuna és asimètrica individualment, la següent simetria aplica entre dues mitjanes geomètriques una basada en X i l'altra basada en la seva reflexió (1-X):

- Mitjanes harmòniquesHarmonic means cadascuna és asimètrica individualment, la següent simetria aplica entre dues mitjanes harmòniques una basada en X i l'altra basada en la seva reflexió (1-X):
- .
- Variància simetria:
- Variàncies geomètriques cadascuna és asimètrica individualment, la següent simetria aplica entre dues log variàncies geomètriques una basada en X i l'altra basada en la seva reflexió (1-X):
- Covariància geomètrica simetria:
- Desviació absoluta mitjana al voltant de la mitjana simetria:
- Asimetria simetria:
- Excés de curtosi simetria:
- Funció característica simetria de la part real (respecte l'origen de la variable "t")
- Funció característica simetria de la part imaginària (respecte l'origen de la variable "t")
- Funció característica simetria del valor absolut (respecte l'origen de la variable "t")
- Entropia diferencial simetria:
- Entropia relativa (també anomenada divergència de Kullback-Leibler) simetria:
- Matriu d'informació de Fisher simetria:
Geometria de la funció de densitat de probabilitat
[modifica]Punts d'inflexió
[modifica]

Per certs valors dels paràmetres de forma α i β, la funció de densitat de probabilitat té punts d'inflexió, en els quals la curvatura canvia de signe. La posició d'aquests punts d'inflexió pot ser útil com a mesura de la dispersió o de l'extensió de la distribució.
Defineixi's el següent paràmetre:
Hi haurà punts d'inflexió,[1][3][6][7] que dependran del valor dels paràmetres de forma α i β, segons:
- (α > 2, β > 2) La distribució té forma de campana (és simètrica pel fet que α = β i asimètrica altrament), amb dos punts d'inflexió, equidistants a la moda:
- (α = 2, β > 2) La distribució és unimodal, positivament asimètrica, amb cua a la dreta, amb un punt d'inflexió, que es troba a la dreta de la moda:
- (α > 2, β = 2) La distribució és unimodal, negativament asimètrica, amb cua a l'esquerra, amb un punt d'inflexió, que es troba a la dreta de la moda:
- (1 < α < 2, β > 2, α+β>2) La distribució és unimodal, positivament asimètrica, amb cua a la dreta, amb un punt d'inflexió, que es troba a la dreta de la moda:
- (0 < α < 1, 1 < β < 2) La distribució té la moda a l'extrem esquerre x = 0 i és positivament asimètrica, amb cua a la dreta. Hi ha un punt d'inflexió, que es troba a la dreta de la moda:
- (α > 2, 1 < β < 2) La distribució és unimodal i negativament asimètrica, amb cua a l'esquerra, té un punt d'inflexió, que es troba a l'esquerra de la moda:
- (1 < α < 2, 0 < β < 1) La distribució té la moda a l'extrem dret x=1 i és negativament asimètrica, amb cua a l'esquerra. Hi ha un punt d'inflexió, que es troba a l'esquerra de la moda:
No hi ha punts d'inflexió en la resta de regions (tant simètriques com asimètriques): en forma d'U: (α, β < 1) en forma d'U de cap per avall: (1 < α < 2, 1 < β < 2), amb forma de J inversa (α < 1, β > 2) o amb forma de J: (α > 2, β < 1)
Les gràfiques de la dreta mostren la ubicació dels punts d'inflexió (verticalment de 0 a 1) versus α i β (els eixos horitzontals van del 0 al 5). Hi ha talls gran en les superfícies que intersecten les rectes α = 1, β = 1, α = 2, i β = 2 ja que és en aquests valors que la distribució beta canvia de 2 modes, a 1 mode a cap mode.
Formes
[modifica]




La funció de densitat de la distribució beta pot prendre una gran varietat de formes diferents en funció dels valors dels dos paràmetres α i β. La versatilitat en les formes de la distribució beta (utilitzant només dos paràmetres) és en part responsable del fet que es trobi en moltes aplicacions de modelatge de mesures reals:
Simètrica
[modifica]Asimètrica
[modifica]Estimació de paràmetres
[modifica]Mètode de moments
[modifica]Dos paràmetres desconeguts
[modifica]Quatre paràmetres desconeguts
[modifica]Màxima semblança
[modifica]Dos paràmetres desconeguts
[modifica]Quatre paràmetres desconeguts
[modifica]Matriu d'informació de Fisher
[modifica]Dos paràmetres desconeguts
[modifica]Quatre paràmetres desconeguts
[modifica]Generació de variables aleatòries distribuïdes segons beta
[modifica]Distribucions relacionades
[modifica]Transformacions
[modifica]Casos especials i limitants
[modifica]Derivació d'altres distribucions
[modifica]Combinació amb altres distribucions
[modifica]Composició en altres distribucions
[modifica]Generalitzacions
[modifica]Aplicacions
[modifica]Estadística d'ordre
[modifica]Regla de successió
[modifica]Inferència bayesiana
[modifica]Probabilitat anterior de Bayes (Beta(1,1))
[modifica]Probabilitat anterior de Haldane (Beta(0,0))
[modifica]Probabilitat anterior de Jeffrey (Beta(1/2,1/2) per una distribució de Bernoulli o binomial)
[modifica]Lògica subjectiva
[modifica]Anàlisi de Wavelet
[modifica]Gestió de projectes: cost d'una tasca i modelatge d'horaris
[modifica]Parametritzacions alternatives
[modifica]Dos paràmetres
[modifica]Mitjana i mida de la mostra
[modifica]Moda i concentració
[modifica]Mitjana (freqüència al·lèlica) i distància genètica (de Wright) entre dues poblacions
[modifica]Mitjana i variància
[modifica]Història
[modifica]Referències
[modifica]- ↑ 1,00 1,01 1,02 1,03 1,04 1,05 1,06 1,07 1,08 1,09 1,10 1,11 1,12 1,13 1,14 1,15 Johnson, Norman L.; Kotz, Samuel; Balakrishnan, N. «Chapter 21:Beta Distributions». A: Continuous Univariate Distributions Vol. 2. 2a edició. Wiley, 1995. ISBN 978-0-471-58494-0.
- ↑ Keeping, E. S.. Introduction to Statistical Inference. Dover Publications, 2010. ISBN 978-0486685021.
- ↑ 3,0 3,1 3,2 Wadsworth, George P. and Joseph Bryan. Introduction to Probability and Random Variables. McGraw-Hill, 1960.
- ↑ 4,0 4,1 Hahn, Gerald J.; Shapiro, S. Statistical Models in Engineering (Wiley Classics Library). Wiley-Interscience, 1994. ISBN 978-0471040651.
- ↑ 5,0 5,1 5,2 5,3 Feller, William. An Introduction to Probability Theory and Its Applications, Vol. 2. Wiley, 1971. ISBN 978-0471257097.
- ↑ 6,0 6,1 6,2 6,3 6,4 6,5 Gupta (Editor), Arjun K. Handbook of Beta Distribution and Its Applications. CRC Press, 2004. ISBN 978-0824753962.
- ↑ 7,0 7,1 Panik, Michael J. Advanced Statistics from an Elementary Point of View. Academic Press, 2005. ISBN 978-0120884940.
- ↑ 8,0 8,1 Rose, Colin; Smith, Murray D. Mathematical Statistics with MATHEMATICA. Springer, 2002. ISBN 978-0387952345.
- ↑ Kruschke, John K. Doing Bayesian data analysis: A tutorial with R and BUGS. p. 83: Academic Press / Elsevier, 2011. ISBN 978-0123814852.
- ↑ Berger, James O. Statistical Decision Theory and Bayesian Analysis. 2a edició. Springer, 2010. ISBN 978-1441930743.
- ↑ 11,0 11,1 Johnson, N. L.; Kotz, S.; Balakrishnan, N.. Continuous univariate distributions. 2a edició. New York: Wiley, ©1994-©1995, p. 210. ISBN 0-471-58495-9.
- ↑ 12,0 12,1 Kerman J (2011) "A closed-form approximation for the median of the beta distribution". arXiv:1111.0433v1
- ↑ Mosteller, Frederick and John Tukey. Data Analysis and Regression: A Second Course in Statistics. Addison-Wesley Pub. Co., 1977. ISBN 978-0201048544.
- ↑ Feller, William. An Introduction to Probability Theory and Its Applications. 1. 3rd, 1968. ISBN 978-0471257080.
- ↑ Philip J. Fleming and John J. Wallace. How not to lie with statistics: the correct way to summarize benchmark results. Communications of the ACM, 29(3):218–221, March 1986.
- ↑ «NIST/SEMATECH e-Handbook of Statistical Methods 1.3.6.6.17. Beta Distribution», 01-04-2012. [Consulta: 31 maig 2016].
- ↑ 17,0 17,1 Abramowitz, Milton and Irene A. Stegun. Handbook Of Mathematical Functions With Formulas, Graphs, And Mathematical Tables. Dover, 1965. ISBN 978-0-486-61272-0.
- ↑ Table of Integrals, Series, and Products (en anglès). 8. Academic Press, Inc., 2015. ISBN 978-0-12-384933-5. LCCN 2014010276.
- ↑ Billingsley, Patrick. «30». A: Probability and measure. 3rd. Wiley-Interscience, 1995. ISBN 978-0-471-00710-4.
- ↑ MacKay, David. Information Theory, Inference and Learning Algorithms. Cambridge University Press; First Edition, 2003. ISBN 978-0521642989.
- ↑ Johnson, N.L. «Systems of frequency curves generated by methods of translation». Biometrika, 36, 1–2, 1949, pàg. 149–176. DOI: 10.1093/biomet/36.1-2.149.
- ↑ A. C. G. Verdugo Lazo and P. N. Rathie. "On the entropy of continuous probability distributions," IEEE Trans. Inf. Theory, IT-24:120–122, 1978.
- ↑ Shannon, Claude E., "A Mathematical Theory of Communication," Bell System Technical Journal, 27 (4):623–656,1948.PDF
- ↑ 24,0 24,1 Cover, Thomas M. and Joy A. Thomas. Elements of Information Theory 2nd Edition (Wiley Series in Telecommunications and Signal Processing). Wiley-Interscience; 2 edition, 2006. ISBN 978-0471241959.
- ↑ Plunkett, Kim, and Jeffrey Elman. Exercises in Rethinking Innateness: A Handbook for Connectionist Simulations (Neural Network Modeling and Connectionism). p. 166: A Bradford Book, 1997. ISBN 978-0262661058.
- ↑ Nallapati, Ramesh. The smoothed dirichlet distribution: understanding cross-entropy ranking in information retrieval. Ph.D. thesis: Computer Science Dept., University of Massachusetts Amherst, 2006.
- ↑ 27,0 27,1 27,2 Pearson, Karl «Mathematical contributions to the theory of evolution, XIX: Second supplement to a memoir on skew variation». Philosophical Transactions of the Royal Society A, 216, 538–548, 1916, pàg. 429–457. Bibcode: 1916RSPTA.216..429P. DOI: 10.1098/rsta.1916.0009. JSTOR: 91092.
- ↑ 28,0 28,1 Pearson, Egon S. «Some historical reflections traced through the development of the use of frequency curves». THEMIS Statistical Analysis Research Program, Technical Report 38, Office of Naval Research, Contract N000014-68-A-0515, Project NR 042–260, 7-1969.
- ↑ Pearson, Karl «Contributions to the mathematical theory of evolution, II: Skew variation in homogeneous material». Philosophical Transactions of the Royal Society, 186, 1895, pàg. 343–414. Bibcode: 1895RSPTA.186..343P. DOI: 10.1098/rsta.1895.0010. JSTOR: 90649.